
Naukowcy z Uniwersytetu Tsinghua, Uniwersytetu Stanowego Ohio i Uniwersytetu Kalifornijskiego w Berkeley stworzyli metodę mierzenia zdolności dużych modeli językowych (LLM) jako „agentów” działających w świecie rzeczywistym. Tym samym sztuczna inteligencja powoli przenika do świata rzeczywistego.
Modele LLM (Large Language Model), takie jak ChatGPT i Claude, zdobyły popularność w świecie technologii w ciągu ostatniego roku. Zaprezentowały się jako zaawansowane „chatboty”, które okazały się użyteczne w różnych zadaniach, takich jak kodowanie, handel kryptowalutami i generowanie tekstu. zwykle modele te są oceniane na podstawie zdolności generowania tekstu, który jest postrzegany jako ludzki. Lub na podstawie wyników testów zrozumiałości języka prostego przeznaczonych dla ludzi. Znacznie mniej prac naukowych opublikowano na temat modeli LLM jako tworów działających w świecie rzeczywistym.
“Agenci” sztucznej inteligencji wykonują konkretne zadania, takie jak wykonanie zestawu instrukcji w określonej przestrzeni. Są to wirtualne lub fizyczne byty, które reagują na dane wejściowe z otoczenia, podejmując akcje w celu osiągnięcia określonych celów. Agenci sztucznej inteligencji są często stosowani w dziedzinach takich jak robotyka, automatyka, gry komputerowe, zarządzanie operacjami czy finanse. A także w rozwiązaniach codziennego użytku, takich jak chatboty czy systemy sterowania inteligentnym domem. Kluczową cechą agentów sztucznej inteligencji jest zdolność do podejmowania decyzji autonomicznie. Decyzje podejmowane są na podstawie dostępnych danych i zaprogramowanych reguł, w celu realizacji określonych zadań.
Sztuczna inteligencja uczy się… chodzić
Na przykład badacze często szkolą agenta AI do nawigacji w złożonym środowisku cyfrowym jako metody badania wykorzystania uczenia maszynowego do bezpiecznego rozwijania autonomicznych robotów. Takim zadaniem może być na przykład nauka… chodzenia. Na poniższym filmiku możemy zobaczyć jak model AI, Albert, uczy się właśnie tego procesu.
Tradycyjni agenci uczenia maszynowego, takie jak ten przedstawiony na powyższym filmie, zwykle nie są budowane jako modele LLM. Głównie z powodu wysokich kosztów związanych z szkoleniem modeli takich jak ChatGPT i Claude. Niemniej jednak największe modele LLM wykazały się obiecującym potencjałem jako agenci.
Sztuczna inteligencja pod lupą AgentBench
Zespół wspomnianych naukowców opracował narzędzie o nazwie AgentBench. Ocenia ono i mierzy zdolności modeli LLM jako agentów działających w rzeczywistym świecie. Według zespołu jest to pierwsze tego typu narzędzie. Według artykułu naukowego badaczy, głównym wyzwaniem przy tworzeniu AgentBench było wykraczanie poza tradycyjne środowiska uczenia się sztucznej inteligencji – gry wideo i symulatory fizyki – i znalezienie sposobów zastosowania zdolności modeli LLM do rzeczywistych problemów, aby mogły być skutecznie mierzone.
Stworzyli oni wielowymiarowy zestaw testów, który mierzy zdolność modelu do wykonywania trudnych zadań w różnych środowiskach. Są to między innymi zadania polegające na wykonywaniu funkcji w bazie danych SQL, pracowaniu w systemie operacyjnym, planowaniu i wykonywaniu prac domowych czy zakupy online. A także kilka innych zadań na wysokim poziomie, które wymagają krok po kroku rozwiązywania problemów.
Według artykułu, największe i najdroższe modele LLM przewyższyły modele open-source o znaczną ilość:
Przeprowadziliśmy kompleksową ocenę 25 różnych modeli LLM dzięki AgentBench, w tym modeli opartych na API i open-source. Nasze wyniki ukazują, iż najlepsze modele, takie jak GPT-4, są zdolne do radzenia sobie z szerokim zakresem rzeczywistych zadań, co wskazuje na potencjał rozwoju skutecznego agenta stale się uczącego.
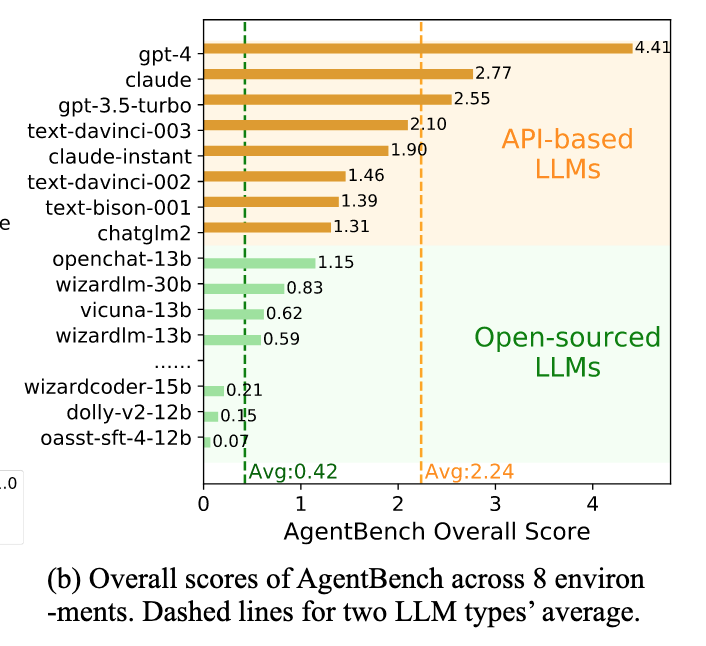 Wyniki testów (w 8 środowiskach) wybranych w badaniu modeli, z podziałem na API i Open-source. Przerywane line wskazują średnią wyników danej grupy. Źródło: arxiv.org
Wyniki testów (w 8 środowiskach) wybranych w badaniu modeli, z podziałem na API i Open-source. Przerywane line wskazują średnią wyników danej grupy. Źródło: arxiv.orgNaukowcy poszli choćby tak daleko, jak twierdzić, iż „najlepsze modele LLM stają się zdolne do radzenia sobie z złożonymi misjami w świecie rzeczywistym”.








