Czy nie ma już rozwoju branży IT bez AI? Jakie są największe korzyści i wyzwania związane z rozwojem sztucznej inteligencji? I jak odpowiedzialne wykorzystywać te technologie w swojej pracy? O tym rozmawiamy z Bartoszem Dziurą, Lead Software Architektem, i Marcinem Carykiem, Lead Test Engineerem z Codelab.
„Można to wypierać i nabijać się ze śmiesznych potknięć nowej technologii u progu kolejnej rewolucji technologicznej. Jednak ćwierć wieku temu też wielu wątpiło, iż Internet i Google staną się tak niezbędne dla większości z nas” – mówi nam Bartosz Dziura, Lead Software Architekt z Codelab, który w swojej pracy wykorzystuje AI w rozwoju projektów z branży automotive. Jak wygląda taka praca i jaka jest przyszłość branży IT w związku z dynamicznym rozwojem AI?
AI w branży IT i automotive – wyzwania i zagrożenia. O pracy dla Codelab opowiadają eksperci – Bartosz Dziura i Marcin Caryk
Obaj pracujecie dla Codelab i działacie w branży motoryzacyjnej. Bartosz jako Lead Software Architekt, a Marcin jako Lead Test Engineer. Jak wykorzystujecie AI w swojej pracy?
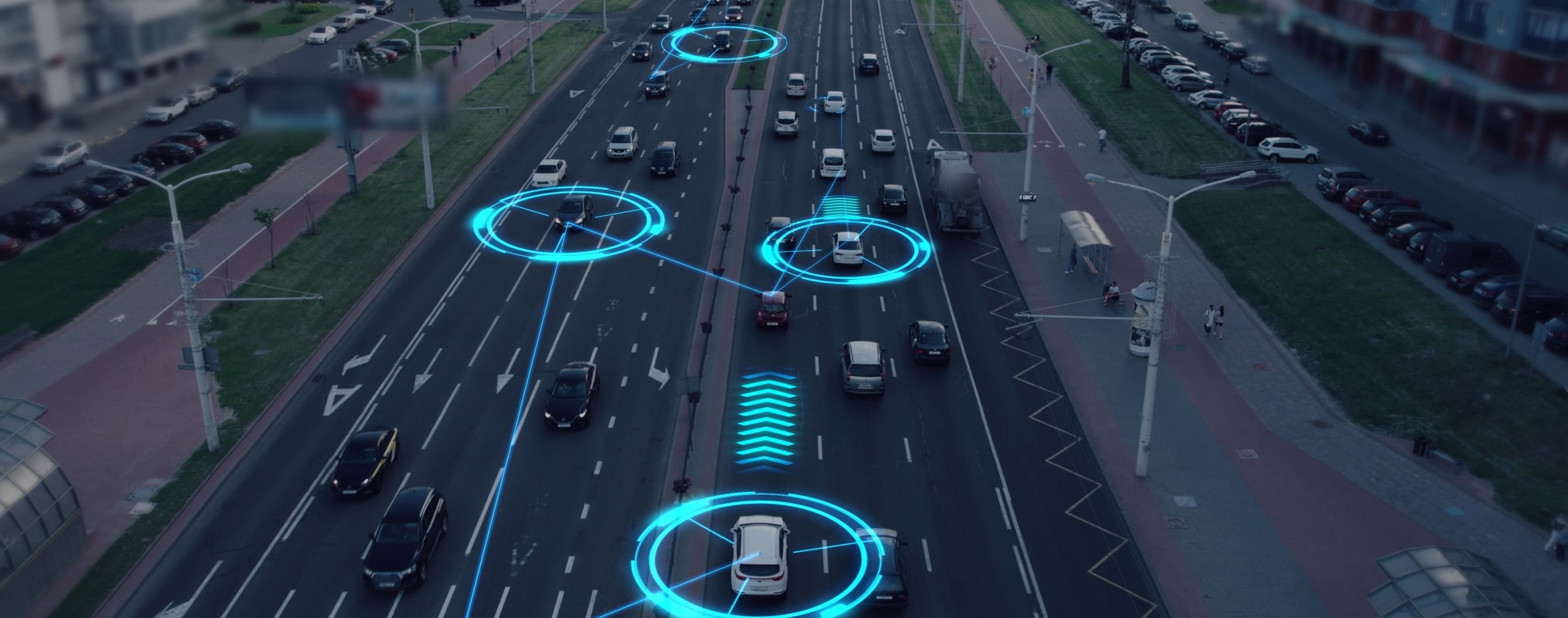
Bartosz Dziura: Pracujemy głównie w branży, w której sztuczna inteligencja, a zwłaszcza uczenie maszynowe, odgrywa kluczową rolę. Jest ono wykorzystywane przede wszystkim w zaawansowanych systemach wspomagania kierowcy, takich jak autonomiczne hamowanie awaryjne, asystent pasa ruchu. Ale też autopilot czy monitorowanie kierowcy (na przykład ocena poziomu senności, zmęczenia, skupienia na drodze, itp).
Chociaż te systemy charakteryzują się wysoką precyzją percepcji otoczenia, zdolnością predykcji niedalekiej przyszłości oraz mają nieludzko krótki czas reakcji, przez cały czas są to wysoce wyspecjalizowane rozwiązania. A co za tym idzie, wciąż daleko im do tzw. ogólnej sztucznej inteligencji (AGI). Mam na myśli tzw. „silną” AI, zdolną do zastąpienia nas w niemal wszystkich zadaniach, o której wiele osób ostatnio spekuluje w kontekście boomu popularności i postępu technologii chatbotów takich jak ChatGPT. W naszej pracy bezpośrednie korzystanie z tych drugich jest mocno ograniczone. Zwłaszcza jeżeli chodzi o wykorzystanie generowanego przez nie kodu czy innych treści.
Głównymi powodami takiego stanu rzeczy są kwestie związane z ryzykiem prawnym oraz niejasnościami dotyczącymi praw autorskich zarówno do generowanych treści, jak i materiałów źródłowych używanych początkowo do wytrenowania tych modeli.
Marcin Caryk: AI to teraz temat na topie, wszędzie się o niej mówi i próbuje ją wykorzystać. Moje aktywności zawodowe odnoszą się do automotive, więc wykorzystywanie ogólnodostępnych AI, tzn. w chmurze, jest bardzo ograniczone. Wynika to z aspektów prawnych, możliwości wykorzystywania pewnych rozwiązań specyficznych dla branży w ogólnodostępnych modelach. Jako tester sporadycznie wspomagam się ChatGPT. Robię to jednak raczej do pomocy w ogólnych zagadnieniach, niezwiązanych z tematyką wykorzystywaną u klienta, np. podczas pracy z Pythonem czy w ramach mojej aktywności akademickiej jako nauczyciel. Staram się pokazać studentom, jak można wykorzystać takie narzędzie mądrze. Uczulam ich, żeby nie byli bierni kognitywnie w stosunku do treści, jaką wygenerują takie modele, innymi słowy, aby analizowali i weryfikowali to, co wygeneruje sztuczna inteligencja.
Co jest dla was największym wyzwaniem związanym z wykorzystaniem AI w pracy?
B.D.: Jednym z największych wyzwań jest weryfikacja bezpieczeństwa i poprawności działania systemów opartych na AI. Sam proces treningu modelu, zakładając dostęp do odpowiednio dużego zbioru danych, jest stosunkowo prosty. Problem pojawia się jednak, gdy na końcu tego procesu powstaje tzw. black box, którego działanie trudno jest ocenić bez testów równie wszechstronnych i różnorodnych, co docelowe rzeczywiste przypadki użytkowania.
W dzisiejszych czasach ta sama platforma programowo-sprzętowa może być podstawą w różnych modelach i markach samochodów na całym świecie. A więc przykładowe pytania, które trzeba sobie zadać i zweryfikować to:
- czy system prawidłowo rozpoznaje i interpretuje znaki, linie i światła na drodze zarówno w USA, Chinach, jak i w Ameryce Południowej?
- jak radzi sobie w trudnych warunkach, takich jak noc, deszcz, zima w Norwegii, jazda na autostradzie pod słońce w Brazylii, czy też na wąskiej drodze na wsi w Wielkiej Brytanii?
- czy potrafi rozpoznać wszystkich uczestników ruchu oraz inne nietypowe obiekty, które mogą się pojawić na drodze?
- czy system poprawnie rozpozna znak STOP choćby wtedy, gdy zostaną na nim umieszczone naklejki/graffiti przez wandala?
- czy istnieje ryzyko, iż model ma w sobie podatności, które ktoś mógłby wykorzystać, aby celowo wprowadzić go w błąd?
- czy jest odporny na „halucynacje” – fałszywe wykrywanie nieistniejących przeszkód, które mogłyby potencjalnie doprowadzić do tragicznego w skutkach awaryjnego hamowania na pustej autostradzie?
M.C.: Ujmując to bardzo ogólnie, największym problemem każdego modelu AI jest skuteczność jego działania. A co za tym idzie „umiejętność” reagowania na różne dane wejściowe „poprawną” odpowiedzią tzn. taką, którą spodziewamy się uzyskać. Projektant takiego modelu musiałby przewidzieć jak największą liczbę przypadków, zwłaszcza skrajnych, przygotować takie dane i wyuczyć dany model. Tak, aby dawał odpowiednie odpowiedzi, czyli odpowiednio reagował.
W swojej karierze zajmowałem się tworzeniem modeli sieci neuronowych do rozpoznawania na obrazach rentgenowskich defektów w spawanych częściach statku, dokładnie były to modele z dziedziny ML (ang. Machine Learning). Obróbka obrazu i przygotowywanie danych wejściowych do trenowania modelu to długa i żmudna praca, a zarazem kluczowa. Co się okazało, tam gdzie miałem najmniej danych model ML radził sobie najgorzej. Były to pęknięcia w spawach, które łatwo zauważyć i bez specjalnej analizy odrzucić taki spaw.
Dlatego też najważniejsze są dane wejściowe, ich różnorodność i ilość.
Jeżeli chodzi o dane dla Chata GPT, to tych danych jest już dostępnych bardzo dużo. Podobnie wszystkie dane o nas, ludziach, które budują nasze profile, zdradzają co lubimy, co zamawiamy, jakie strony przeglądamy itp. już istnieją, dostarczamy ich sami, codziennie. W przypadku branży automotive i autonomicznych kierowców jest to wciąż nisza – ciągle gromadzimy ten typ danych. Jazda po średniowiecznym miasteczku o wąskich uliczkach wygląda inaczej niż po nowoczesnych miastach trzypasmową drogą, tak więc możliwych scenariuszy jest niezwykle dużo.
Podsumowując, wyzwania w AI to: optymalne rozwiązania sprzętowe (kompaktowe o szybkim czasie reakcji), optymalny model AI, duża ilość danych do trenowania, walidacji i testowania.
W jaki sposób weryfikujecie przydatność danego rozwiązania opartego o AI?
B.D.: Najczęściej stosowaną metodą jest masowa kampania zbierania danych na całym świecie, realizowana dzięki specjalnie przystosowanych samochodów testowych. Pojazdy te gromadzą skrupulatnie wszystkie dane wejściowe i wyjściowe, pochodzące zarówno z istniejących podsystemów samochodu, jak i dodatkowych, precyzyjnie skalibrowanych z nimi sensorów, takich jak LiDAR czy dGPS. W przypadku bardziej niebezpiecznych scenariuszy, których nie można weryfikować na publicznych drogach, np. symulowania sytuacji awaryjnego hamowania w celu uniknięcia potrącenia pieszego, testy przeprowadzane są na dedykowanych torach testowych.
Ostatecznie mówimy o dziesiątkach, a choćby setkach tysięcy godzin nagrań, milionach przejechanych kilometrów i petabajtach zgromadzonych danych.
Warto również zauważyć, iż takie weryfikacje trzeba regularnie powtarzać, w miarę jak oprogramowanie ewoluuje. W tym celu wykorzystuje się techniki Software/Hardware-In-the-Loop, które umożliwiają regularne resymulacje wszystkich zebranych danych. Wyniki tych symulacji są następnie analizowane wielowymiarowo, aby wykryć jakiekolwiek negatywne korelacje, biasy (np. tendencje do zawyżania szacowanych odległości), regresje czy też nieprzewidziane przypadki graniczne. Przy tej skali danych analiza jednej iteracji potrafi zająć tygodnie, choćby z wykorzystaniem superkomputerów.
M.C.: Wszystko zależy od kontekstu do czego dane rozwiązanie i model są wykorzystywane. o ile chodzi o AI w automotive i wykorzystanie m.in. autonomicznego systemu jazdy, to jest to proces złożony. Przy tworzeniu modelu mamy już bowiem podział danych na dane uczące, walidujące i testujące. Po stworzeniu modelu AI czy całego systemu, mamy proces weryfikacji i analizy. Następnie po implementacji modelu na sprzęcie docelowym następuje proces weryfikacji w środowisku symulacyjnym. Sprawdzany jest m.in. czas reakcji i poprawność odpowiedzi z danymi wzorcowymi. Dane są tu generowane i nie pochodzą jeszcze od rzeczywistych czujników czy sprzętu. Często wykorzystuje się do tego różne symulatory, które podają przetworzone dane do modelu AI. Jest to testowanie Software-In-the-Loop. W momencie zestawienia wszystkich podzespołów, m.in. czujników, kamer, następuje proces testowania Hardware-In-the-Loop.
Jest to proces wykonywania testów integracyjnych, gdzie sprawdzane jest kooperacja wszystkich elementów systemu z wykorzystaniem testów wydajnościowych i optymalizacyjnych.
Dodatkowo w wielu przypadkach wykorzystuje się już inne modele AI, takie jak ML do automatycznego generowania przypadków testowych, do inteligentnego generowania danych testowych. Wykorzystywane są też algorytmy do wykrywania anomalii i izolacji błędu, zwłaszcza danych z różnego rodzaju czujników. Następnie testowane jest wszystko w modelu testowym pojazdu gdzie dane są gromadzone, a kierowca ma pełną kontrolę nad pojazdem. W tym wszystkim najważniejszy jest podział procesu testowego na testowanie funkcji krytycznych, regresji i cyklicznej weryfikacji. o ile mówimy o testowaniu modeli językowych takich jak ChatGPT, to nakład na testowanie jest mniejszy. Duży wkład na testowanie mają odbiorcy końcowi, podczas jego normalnego użytkowania.
A jak dbacie o jakość pracy wykonanej przez AI?
B.D.: Poprzez nieustanne porównywanie uzyskanych wyników z niezależnymi sensorami oraz innymi alternatywnymi źródłami „obiektywnej prawdy”. Ponadto, sprawdzamy spójność tych wyników w ramach samego systemu, „w poprzek” kolejnych wersji oprogramowania, a w przypadku wielokrotnych symulacji na tych samych danych wymagamy wręcz ich deterministyczności. Dobre systemy zakładają z góry istnienie redundantnych, technologicznie niezależnych źródeł informacji, wymagając wzajemnej zgodności wyników dla dalszego działania.
Na każdym etapie nieustannie (iteracyjnie) udoskonalamy naszą metodologię testów i analiz, aby zawczasu wykryć i zaadresować wszystkie potencjalne problemy.
Od wielu lat zajmuję się weryfikacją systemów ADAS. I choć bywa to wymagające – często zmuszające do kwestionowania założeń projektu, szczególnie w kontekście presji budżetowej i czasowej – daje to jednocześnie niesamowite poczucie misji. Praca ta ma bowiem realny wpływ na życie i bezpieczeństwo wszystkich ludzi, zarówno tych w samochodach jak i osób postronnych. jeżeli taka perspektywa i odpowiedzialność nie motywowałaby do działania i wspinania się na wyżyny swoich umiejętności, trudno sobie wyobrazić, co innego mogłoby to uczynić.
M.C.: Po pierwsze poprzez ciągłe testowanie rozwiązań AI, danymi rzeczywistymi jak i danymi symulacyjnymi. najważniejsze jest tutaj posiadanie przypadków z danymi brzegowymi, np. takimi które mają skrajnie wartości tzn. bardzo małe lub zbyt duże, ogólnie wykraczających poza zakresy. Osoba weryfikująca musi mieć tzw. „krytyczne spojrzenie” jak i dociekliwą osobowość oraz zawsze zadawać pytanie „A co by się stało, gdyby…?”.
Na pewno wiemy już teraz, iż rozwiązania AI nie są odpowiedzią na naszą niewiedzę, a raczej narzędziem wspomagającym inżynierów, oszczędzającym czas.
Dla przykładu wykorzystywanie ChatGPT wymaga weryfikacji informacji wygenerowanej przez AI, a co za tym idzie wiedzy modelu na temat zapytanego zagadnienia. Dokładnie tak, jak w przypadku generowania grafik przez AI. o ile wygenerowana postać ma 3 ręce i nie był to zamierzony cel, to wiemy, iż zdjęcie jest wygenerowane z błędem, ponieważ chcieliśmy, aby postać miała dwie ręce. Podobnie jest z każdym modelem AI, musimy dokładnie wiedzieć, co chcemy uzyskać i walidować dany model pod tym względem.
Waszym zdaniem od dzisiaj AI zawsze będzie towarzyszyć firmom tworzącym oprogramowanie?
B.D.: W naszej branży jest to już wręcz niemożliwe, aby na drogach w Unii Europejskiej dopuszczono do ruchu nowy samochód bez systemów ADAS. Liczba i jakość wymaganych funkcji tych systemów ciągle rośnie. W sytuacji, gdy emisje spalin są ściśle kontrolowane, a parametry silników elektrycznych są tak bardzo zbliżone, jakość systemu i automatyzacja stają się kluczowymi elementami konkurencyjności i budowania wartości, poza samą ceną pojazdu.
Śmiem twierdzić, iż niedługo AI stanie się nieodłącznym elementem naszego życia – zarówno zawodowego, jak i prywatnego.
Można to wypierać i wyśmiewać śmieszne potknięcia nowej technologii u progu kolejnej rewolucji technologicznej. Jednak ćwierć wieku temu też wielu wątpiło, iż Internet i Google staną się tak niezbędne dla większości z nas. Przykład: dzięki coraz bardziej zaawansowanym botom wirtualnym, jesteśmy coraz częściej bombardowani nieproszonymi i trudnymi do odsiania kontaktami, ofertami i spamem przez telefon, w formie SMS-ów czy e-maili. W tym “wyścigu zbrojeń” botów/AI każdy z nas będzie za chwilę potrzebował prywatnego asystenta AI / wirtualną sekretarkę, aby się chronić, skutecznie filtrować napływające informacje. To on zdecyduje, jakie informacje mają do nas dotrzeć, a które powinny być grzecznie, ale stanowczo odrzucone lub choćby całkowicie zignorowane.
M.C.: Uważam, iż tak, AI to już będzie dla nas nieodłączny “przyjaciel” podczas tworzenia oprogramowania. Wcześniej często pracowaliśmy poprzez przeszukiwanie np. forum Stack Overflow itp., a teraz jesteśmy w stanie oszczędzić czas, dzięki sztucznej inteligencji. Oczywiście uważam, iż każdy musi zawsze spojrzeć krytycznie na rozwiązanie, które poda mu AI. w uproszczeniu – bez wiedzy i zrozumienia, co się dzieje w tworzonym kodzie, wykorzystywanie AI może być zgubne.
Jeżeli zaś chodzi o nasze życie, już się to dzieje. W każdej dziedzinie coraz częściej i śmielej są wykorzystywane różne modele AI. W branży automotive również. To tylko kwestia czasu, kiedy samochody będą same jeździły, latały a nam będą towarzyszyć na co dzień rozwiązania takie jak asystenci, czy to w postaci wirtualnej lub też zrobotyzowanej.
Rozmówcy

Bartosz Dziura, Lead Software Architekt w Codelab. Prawie dwie dekady doświadczenia w embedded development z czego ostatnia w większości poświęcona na rozwój zaawansowanych systemów wspomagania kierowcy opartych na kamerach i wizji komputerowej dla niemieckich koncernów samochodowych i ich dostawców. Praca wciąż jest jego pasją i daje mu niezastąpione poczucie realnego wpływu na życie ludzi dookoła i ich bezpieczeństwo. Prywatnie stereotypowy geek: technofil, gamer (#PCMR i planszówki). jeżeli to, co robi w danej chwili, nie wymaga pełnego skupienia, najprawdopodobniej w tle asymiluje właśnie kolejnego audiobooka z gatunku sci-fi albo fantasy.

Marcin Caryk, Lead Test Engineer w Codelab. Od ponad dekady zajmuje się kwestiami związanym z testowaniem, automatyzacją testów, zagadnieniami DevOps i programowaniem w języku Python, jak i również tematami AI. Nauczyciel akademicki na ZPSB z tytułem PhD w dziedzinie elektrotechnika z doświadczeniem wykorzystania ML w zagadnieniach przemysłowych związanych z badaniami nieniszczącymi. Aktualnie pogłębia wiedzę związaną z AI, narzędziami związanymi z tym tematem i wykorzystaniem ich w codziennej pracy. Lubi uczyć się czegoś nowego. Prywatnie kolekcjoner gier planszowych i gier RPG, fan sztuk walki, zwłaszcza japońskich.