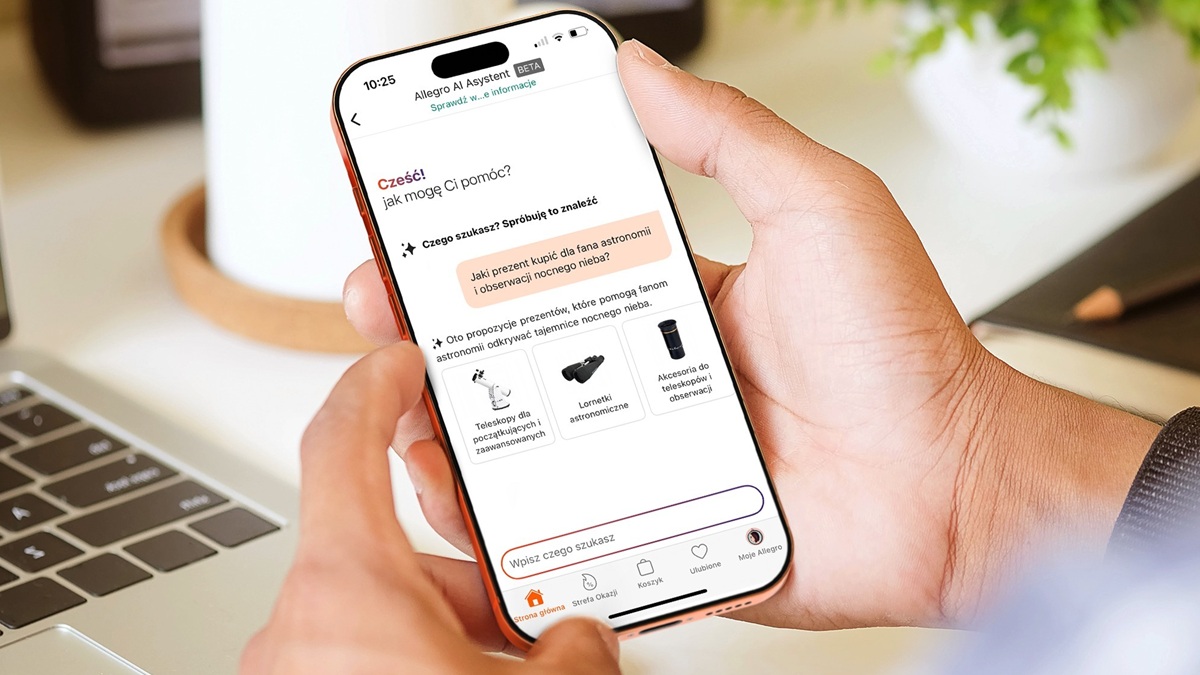
Chiński gigant technologiczny Tencent udostępnił jako oprogramowanie otwartoźródłowe dwa nowe modele tłumaczeniowe z serii Hunyuan. Firma twierdzi, iż w testach porównawczych deklasują one konkurencję, w tym Tłumacza Google.
Tencent postanowił rzucić rękawicę liderom rynku tłumaczeń maszynowych. Firma udostępniła jako oprogramowanie otwartoźródłowe (open source) dwa nowe, wyspecjalizowane modele do tłumaczeń: Hunyuan MT 7B oraz Hunyuan MT Chimera 7B. Jak twierdzi firma, w testach porównawczych wypadają one znacznie lepiej niż uznane narzędzia, takie jak Tłumacz Google, a choćby duże, zamknięte modele językowe, jak GPT-4 czy Gemini.
Potwierdzeniem tych deklaracji mają być wyniki z warsztatów WMT2025 (Workshop on Machine Translation) – jednego z najważniejszych wydarzeń w branży, gdzie zespoły badawcze porównują swoje systemy. Modele Tencenta zajęły tam pierwsze miejsce w 30 z 31 testowanych par językowych.
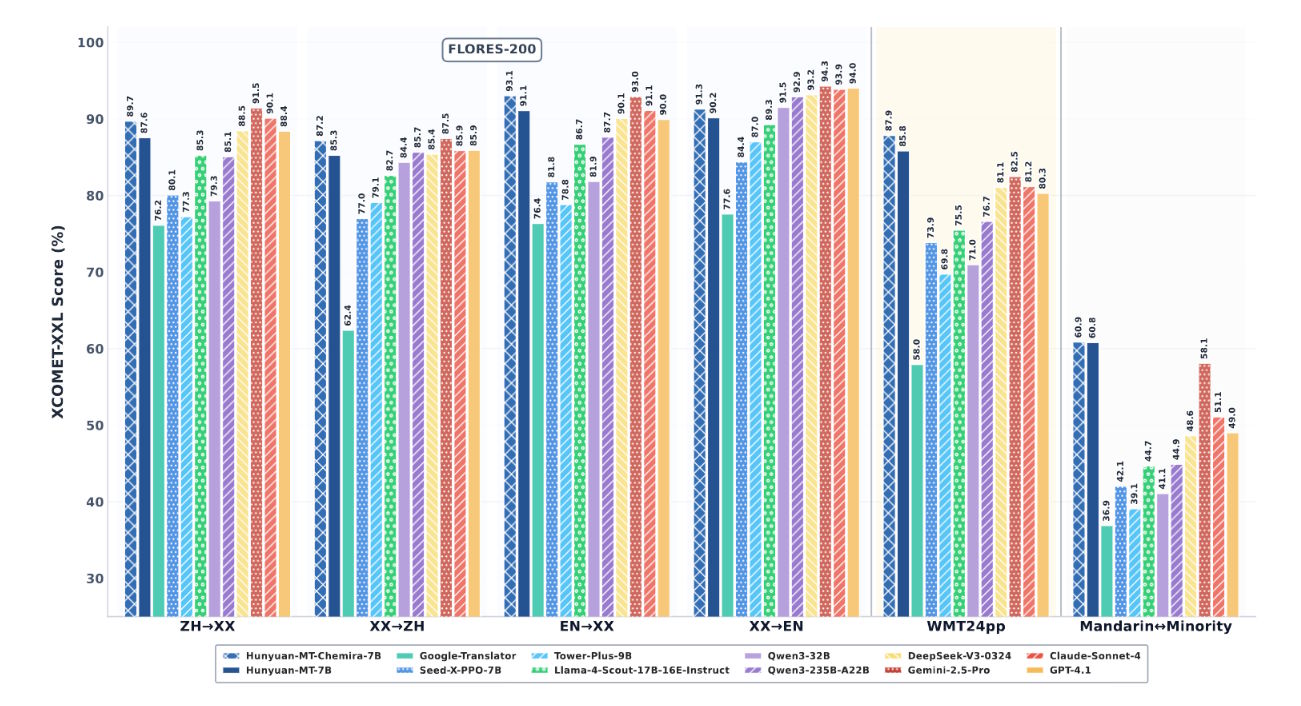
Modele Tencenta (niebieskie słupki) przewyższają najlepsze systemy AI w wielu zadaniach tłumaczeniowych, z wyjątkiem tłumaczeń na język angielski.
Oba modele obsługują dwukierunkowe tłumaczenia w 33 językach. Co ważne dla polskich użytkowników, na liście wspieranych języków, obok tak popularnych jak chiński, angielski czy japoński, znalazł się również język polski. Modele radzą sobie także z językami rzadziej spotykanymi w cyfrowym świecie, jak czeski, estoński, islandzki czy marathi. Co istotne dla Tencenta, skupiają się również na tłumaczeniach między mandaryńskim a językami mniejszości narodowych w Chinach (kazachskim, ujgurskim, mongolskim i tybetańskim).
Tym, co wyróżnia modele Hunyuan, jest ich relatywnie niewielki rozmiar. Posiadają “tylko” 7 miliardów parametrów, co sprawia, iż wymagają znacznie mniejszej mocy obliczeniowej i mogą działać na słabszym sprzęcie niż konkurencyjne, często wielokrotnie większe modele. Mimo to, w bezpośrednich porównaniach z systemami takimi jak Gemini 2.5 Pro, modele Tencenta osiągnęły wyniki lepsze o około 4,7%. W zestawieniu z Tłumaczem Google poprawa wynosiła od 15% do choćby 65%, w zależności od języka i kryteriów oceny.
Sukces ma tkwić w zaawansowanym, pięciostopniowym procesie trenowania oraz wykorzystaniu ogromnych zbiorów danych (1,3 biliona tokenów tylko dla języków mniejszości). Model Chimera dodatkowo wykorzystuje innowacyjne podejście, łącząc kilka propozycji tłumaczeń z różnych systemów w jeden, ostateczny i najlepszy jakościowo wynik. Modele są już dostępne na platformie Hugging Face, a ich kod źródłowy został opublikowany na GitHubie, co pozwala deweloperom i badaczom na całym świecie na ich swobodne wykorzystanie i dalszy rozwój.