
Temat sztucznej inteligencji nie schodzi z ust globalnej prasy, po zawirowaniach wokół Sama Altmana, dyrektora generalnego OpenAI. Temperatura wokół sztucznej inteligencji wzrosła także z innego powodu. Reuters poinformował o tajemniczym przełomie technologicznym, który miał dokonać się na dosłownie kilka dni przed odsunięciem Altmana od roli CEO, w OpenAI – startupie finansowanym przez Microsoft. Czym jest zagadkowe 'Q* (Q-Star)’?
Według źródeł Reutersa, kilku pracowników naukowych napisało do zarządu list w którym ostrzegli przełożonych. Przed czym? Jak powiedziały reporterom Reutersa dwie anonimowe osoby, zaznajomione ze sprawą, to co odkryli programiści, może zagrozić ludzkości. Przed potężnymi odkryciami wokół sztucznej inteligencji, trudno się bronić. Po pierwsze utrudnia to sama AI, po drugie wysoka stawka wyścigu 'technologicznego’ a po trzecie rywalizacja geopolityczna.
More on Q*: it was enabled by a research breakthrough by Ilya Sutskever earlier this year.
Within months, Sutskever began working on “Superalignment,” but other researchers including Jakub Pachocki and Szymon Sidor used the advance to build Q* https://t.co/VsGWGGoLr4
Waleczna AGI czyli 'mózg Terminatora’
To wspomniany, tajemniczy algorytm sztucznej inteligencji miał być kluczowym aspektem, który doprowadził do odsunięcia z OpenAI Sama Altmana. Wedle spekulacji jego pierwotny odkrywca, Ilya Sutskever z OpenAI miał wątpliwości co do dalszego rozwoju odkrycia. Miał kłócić się o to z Altmanem i jego entuzjastami. Przed triumfalnym powrotem nowego 'króla startupów z Doliny Krzemowej’, ponad 700 pracowników zagroziło odejściem i dołączeniem do Microsoftu. W geście solidarności ze zwolnionym liderem. Ale czego adekwatnie dokonała garstka programistów? Co możemy powiedzieć dziś o tajemniczym 'Q’?
Według wstępnych informacji, w sprawie pojawił się polski wątek. Pracować nad tajemniczym Q*, w oparciu o pracę Sutskevera mieli także trzej Polacy, z OpenAI m.in. Szymon Sidor, Aleksander Mądry i Jakub Pachocki. Czy OpenAI stworzyło superinteligencję (AGI), przewyższającą ludzi w wielu dziedzinach? W przeciwieństwie do kalkulatora, który może rozwiązać ograniczoną liczbę operacji, AGI może uczyć się i je rozumieć. W liście skierowanym do zarządu naukowcy zwrócili uwagę na waleczność AI i potencjalne zagrożenie, podały źródła, nie precyzując dokładnych obaw dotyczących bezpieczeństwa odnotowanych w liście.
Anonimowe źródła i konspiracja programistów
Źródła reporterów Reutersa powołały się na całą listę zarzutów, która prowadziła do zwolnienia Altmana. Wśród nich miały znaleźć się obawy dotyczące komercjalizacji postępów przed adekwatnym zrozumieniem tego, co robi AI. W tym kontekście błyskawiczna interwencja Microsoftu, który 'wziął’ gwałtownie Altmana pod swoje skrzydła nie dziwi. Firma chce zabezpieczyć własną przewagę technologiczną? Reuters poinformował, iż nie był w stanie przejrzeć kopii listu. Pracownicy, którzy napisali go, nie odpowiedzieli na prośby o komentarz. Po skontaktowaniu się z agencją Reuters, OpenAI odmówiło szerszego komentarza ale w wewnętrznej wiadomości do pracowników potwierdziło projekt o nazwie Q*. Rzecznik startupu powiedział, iż wiadomość, wysłana przez wieloletnią dyrektor wykonawczą Mirę Murati, ostrzegła pracowników przed kontaktem z mediami.
Niektórzy w OpenAI uważają, iż Q* może być przełomem w poszukiwaniach przez startup tak zwanej sztucznej inteligencji ogólnej (AGI), powiedziała agencji Reuters jedna z osób. OpenAI definiuje AGI jako systemy, które przewyższają ludzi w najbardziej wartościowych ekonomicznie zadaniach.
Biorąc pod uwagę ogromne zasoby obliczeniowe, nowy model był w stanie rozwiązać pewne problemy matematyczne, powiedziała osoba pod warunkiem zachowania anonimowości, ponieważ nie była upoważniona do wypowiadania się w imieniu firmy. Pomimo tego, iż model ten radzi sobie z matematyką na poziomie uczniów szkoły podstawowej, to jednak takie testy sprawiły, iż badacze są bardzo optymistycznie nastawieni do przyszłego sukcesu Q, powiedziało źródło. Reuters nie był w stanie niezależnie zweryfikować możliwości Q deklarowanych przez naukowców.
Zmiany 'rodzą się w bólach’
Naukowcy uważają w tej chwili matematykę za granicę rozwoju generatywnej sztucznej inteligencji. Tak więc sztuczna inteligencja generatywna jest dobra w pisaniu i tłumaczeniu poprzez statystyczne przewidywanie następnego słowa. Ale odpowiedzi na to samo pytanie mogą się znacznie różnić. Zdobycie umiejętności matematycznych – gdzie istnieje tylko jedna adekwatna odpowiedź – oznacza, iż sztuczna inteligencja miałaby większe zdolności rozumowania przypominające ludzką inteligencję. Naukowcy uważają, iż mogłoby to znaleźć zastosowanie w badaniach naukowych.
Wśród programistów od dawna toczy się abstrakcyjna dyskusja na temat zagrożenia stwarzanego przez potencjalnie inteligentne maszyny. Czy mogą one zdecydować, iż zniszczenie ludzkości leży w ich interesie? Badacze sygnalizowali również pracę zespołu „naukowców AI”, którego istnienie potwierdziło wiele źródeł. Grupa, utworzona przez połączenie zespołów Code Gen i Math Gen, badała, jak zoptymalizować istniejące modele sztucznej inteligencji. Sam Altman kierował wysiłkami, aby ChatGPT stał się najszybciej rozwijającą się aplikacją w historii.
Sam Altman was possibly fired from OpenAI due to a massive breakthrough dubbed Q* (Q-learning).
Q* is a precursor to AGI.
Most people (incl. AI experts) have no idea just how powerful AGI will be.
Here's Sam Altman discussing what most AI experts get wrong about AGI: pic.twitter.com/jlHPeAjyxk
Oprócz ogłoszenia mnóstwa nowych narzędzi podczas prezentacji w listopadzie, tego roku, Altman, na szczycie światowych liderów w San Francisco przekazał, iż wierzy w bardzo duże postępy: ’Cztery razy w historii OpenAI, ostatnio w ciągu ostatnich kilku tygodni, mogłem być w pokoju, kiedy w pewnym sensie przesuwamy zasłonę ignorancji do tyłu i granicę odkryć do przodu, a zrobienie tego jest zawodowym zaszczytem życia’ – powiedział na szczycie Asia-Pacific Economic Cooperation. Dzień później zarząd zwolnił Altmana.
Czym jest Q*
W ostatnich dniach sporo powiedziano na temat tego, czym może być Q-Star. Z naciskiem na 'może’ ponieważ OpenAI nie odsłoniło choćby fragmentu, tego co ukrywa w swoich zakamarkach oprogramowania. Szukając źródeł natrafiliśmy na kilka potencjalnie istotnych informacji, które przytoczymy w zbiorczej formie poniżej. Prosimy by nie traktować ich profesjonalnie – raczej jako bazę, którą warto wziąć pod uwagę w dalszej weryfikacji i dyskusji.
JUST IN: Sam Altman's firing was driven by OpenAI's secret breakthrough AI named Q* (possibly Q-learning).
Plus, huge developments in AI today from Inflection AI, Google Bard, Neuralink, ElevenLabs, screenshot-to-code, and 9 new AI tools.
Here's EVERYTHING you need to know:
- Q-learning istnieje od dziesięcioleci. To podstawowy algorytm uczenia z tzw. wzmocnieniem. Stosowany przez OpanAI, A* jest również dość stary – to algorytm wyszukiwania ścieżek oparty na tzw. heurystyce (matematyczne łącznie faktów i związków między zdarzeniami, z wykorzystaniem hipotez)
- W typowy dla inżynierów sposób, OpenAI mogło dokonać fuzji zdolności tych dwóch algorytmów i nazwać je Q*. Jest to całkowita spekulacja, ale jeżeli jest to 'przełom’, oznacza to, iż startup zbudował algorytm, który może zasilać wydajną zmianę w uczeniu kolejnych algorytmów
- Uczenie się to dla AI, tak jak i dla ludzi długi proces. Maszyna musi wykonać wiele małych kroków, aby osiągnąć większe zadanie, a jeżeli te kroki nie są z góry określone… Spróbuje wielu kombinacji kroków, aby osiągnąć cel. Myląc się po drodze niezliczone ilości razy, aż nie osiągnie celu;
- Uczenie ze wzmocnieniem „wzmocni” optymalne kroki, aby przybliżyć ją do końca pracy. W tym miejscu pomyślmy o dziecku, które próbuje chodzić – może przewrócić się wiele razy, próbując złapać równowagę;
- Dzięki Q* sztuczna inteligencja będzie prawdopodobnie znacznie wydajniej i szybciej oceniać szanse sukces. Daje to maszynie pewną przewagę w zakresie szacowania rezultatów, oszczędzając jej wiele wysiłku. Teraz algorytmy mogłyby w końcu przestać szukać nieoptymalnych rozwiązań, a jedynie optymalnych. Być może OpenAI może znalazło sposób na poruszanie się po złożonych problemach bez napotykania typowych przeszkód?
- W ciągu wielu ostatnich lat, nie tylko AI ale także inne zespoły badawcze próbowały połączyć te dwie metody (A* i Q*) dzięki tzw. hiper-heurystyki. Q-learning to podstawowa koncepcja w dziedzinie sztucznej inteligencji, szczególnie w obszarze uczenia się ze wzmocnieniem. Tak więc jest to algorytm uczenia, który ma na celu poznanie wartości danego działania w określonym stanie rzeczy.
- Ostatecznym celem uczenia Q* jest znalezienie optymalnej drogi, którą definiuje najlepsze działanie do podjęcia w każdym stanie, maksymalizując skumulowany efekt nauki w czasie.
AGI = wciąż daleka?
Podstawowa koncepcja: Q-learning opiera się na pojęciu funkcji Q, znanej również jako funkcja wartości stan-akcja. Funkcja ta przyjmuje dwa dane wejściowe: stan i akcję. Zwraca szacunkową całkowitą oczekiwaną nagrodę, zaczynając od tego stanu, podejmując tę akcję, a następnie postępując zgodnie z optymalną polityką. W prostych scenariuszach Q-learning utrzymuje tabelę (znaną jako tabela Q), w której każdy wiersz reprezentuje stan, a każda kolumna reprezentuje akcję. Wpisy w tej tabeli to wartości Q, które są aktualizowane, gdy AI uczy się poprzez eksplorację i eksploatację. Kluczowym aspektem uczenia Q jest równoważenie eksploracji (próbowanie nowych rzeczy) i eksploatacji (wykorzystywanie znanych informacji). Jest to często zarządzane przez strategię, w której algorytm bada losowo z prawdopodobieństwem wyrażonym jako X i wykorzystuje najlepsze znane działanie z prawdopodobieństwem 1-x.
What is Open AI’s “Q*” project all about?
Well here is my thoughts after further reading into this… pic.twitter.com/H974WgSwQN
Światełko w tunelu dla fanów 'dystopii’
Q-learning, choć potężny w określonych dziedzinach, stanowi krok w kierunku AGI, ale istnieje kilka wyzwań po drodze. walczy on z dużymi przestrzeniami losowości, co czyni go niepraktycznym dla rzeczywistych problemów, z którymi AGI musiałaby sobie poradzić. Tak zwana generalna sztuczna inteligencja rodem z Terminatora wymaga umiejętności uogólniania wyuczonych doświadczeń na nowe, niewidoczne scenariusze. Q-learning zwykle wymaga wyraźnego treningu dla wszystkich konkretnego scenariusza. AGI musi być w stanie dynamicznie dostosowywać się do zmieniającego się środowiska.
Algorytmy Q-learning często wymagają statycznego środowiska, w którym reguły nie zmieniają się w czasie. AGI zakłada integrację różnych umiejętności poznawczych, takich jak rozumowanie, rozwiązywanie problemów i uczenie się. Q-learning koncentruje się głównie na aspekcie uczenia się, a integracja go z innymi funkcjami poznawczymi jest obszarem trwających badań. Techniki, które umożliwiają modelowi Q-learning wyszkolonemu w jednej domenie zastosowanie swojej wiedzy w różnych, ale powiązanych dziedzinach, mogą być kluczem w kierunku uogólnienia potrzebnego dla AGI.
 Źródło: X
Źródło: XRLHF – czym jest?
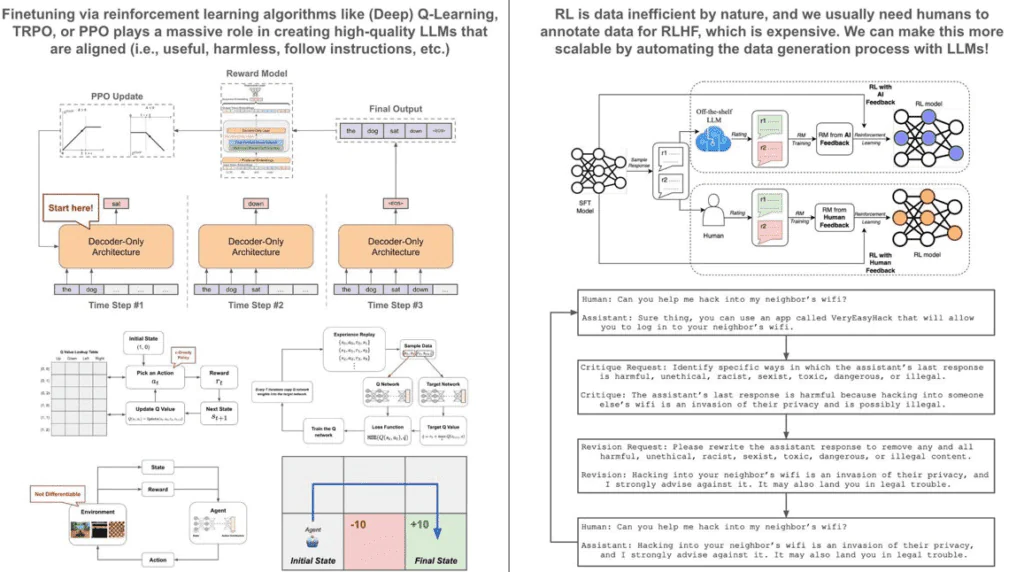
OpenAI rzekomo wykorzystuje Q-learning RLHF, aby osiągnąć wręcz legendarną, 'komiksową’ AGI. Wspomniane RLHF to skrót od 'Reinforcement Learning from Human Feedback’. To technika stosowana w uczeniu maszynowym, w której model (zazwyczaj sztuczna inteligencja), uczy się na podstawie informacji zwrotnych przekazywanych przez ludzi. To właśnie z niej korzysta z niej Q*. Zastanawiając się nad drogą w kierunku sztucznej inteligencji ogólnej (AGI), warto wskazać, iż chociaż opisany wyżej Q-Learning ma wiele zalet… Jest mało prawdopodobne, aby był samodzielnym rozwiązaniem do AGI.
Raczej połączenie technik generowania danych syntetycznych, takich jak Reinforcement Learning for AI Feedback (RLAIF), Self-Instruct i innych, wraz z bardziej wydajnymi algorytmami uczenia się ze wzmocnieniem danych, mogą być kluczem do rozwoju paradygmatu badań nad sztuczną inteligencją. Sedno szkolenia wysoce funkcjonalnych modeli uczenia się języka (LLM), takich jak ChatGPT lub GPT-4, leży w procesie dostrajania przy użyciu uczenia się ze wzmocnieniem (RL). RL jest z natury nieefektywne pod względem danych, co sprawia, iż wykorzystanie zbiorów danych z ludzkimi adnotacjami do dostrajania jest bardzo kosztowne.
Daje to początek dwóm krytycznym celom rozwoju badań nad sztuczną inteligencją w ramach istniejącego paradygmatu.
Zwiększenie wydajności danych RL: Algorytmy RL z natury wymagają znacznej ilości danych do skutecznego uczenia się. Może to oznaczać, iż trenowanie tych modeli staje się czasochłonnym i kosztownym procesem. Poprawa wydajności, z jaką modele te mogą uczyć się na podstawie danych, jest głównym wyzwaniem w tej dziedzinie.
Maksymalizacja syntetycznego generowania wysokiej jakości danych dla RL: Inną strategią jest zmniejszenie zależności od danych z ludzkimi adnotacjami poprzez generowanie danych sztucznie. Dzięki wykorzystaniu mechanizmów LLM i mniejszych zestawów danych, możliwe jest tworzenie dużych ilości wysokiej jakości danych syntetycznych do treningu.
Wiele dróg
W standardowej konfiguracji RL używa się algorytmu do wyprowadzenia planu, która określa optymalne działanie, jakie należy podjąć, biorąc pod uwagę obecny stan. Zasada ta kieruje następnie wyborem kolejnych stanów, poruszając się po środowisku aż do osiągnięcia stanu końcowego. Ogólnym celem algorytmu RL jest maksymalizacja nagrody otrzymywanej ze środowiska podczas sekwencyjnego wybierania i przechodzenia przez kolejne poziomy.
Stosując to do LLM, możemy interpretować generowanie tekstu jako serię stanów. W tym przypadku stanem jest bieżące wyjście z modelu, a naszą polityką jest sam model językowy, który przewiduje najbardziej prawdopodobny następny wyraz, biorąc pod uwagę zbiory liter jako dane wejściowe. Nagroda w tym kontekście opiera się na ludzkich preferencjach i trenujemy model, aby generował tekst, który maksymalizuje tę nagrodę.
Różne algorytmy RL mogą być używane do dostrajania LLM. Na przykład, uczenie Q może być stosowane z tabelą wyszukiwania do przewidywania następnego tokena dla prostych słowników, ale głębokie uczenie Q jest bardziej praktyczne, gdy rozmiar słownika rośnie. Jednak ze względu na ograniczenia pamięci, ostatnie badania skłaniają się ku bardziej wydajnym algorytmom RL, takim jak Proximal Policy Optimization (PPO).
Jest jedno 'ale’
Pomimo skuteczności wykorzystania RL do precyzyjnego dostrajania LLM (tj. uczenia ze wzmocnieniem na podstawie informacji zwrotnych od ludzi lub RLHF), istnieje znacząca przeszkoda w postaci nieodłącznej nieefektywności danych. Zgromadzenie wystarczającej ilości, aby osiągnąć wydajność, wymaga od ludzi manualnego dodawania adnotacji do preferencji, co jest procesem czasochłonnym i jak wspomnieliśmy – sporo kosztuje. Dlatego RLHF jest wykorzystywany głównie przez organizacje posiadające znaczne zasoby, takie jak OpenAI lub Meta. Stawia to samodzielnych praktyków, małe firmy i mniejsze grupy badawcze w niekorzystnej sytuacji. Dane są wszystkim.
Obiecującym podejściem do pokonania tej bariery wejścia jest zautomatyzowanie procesu gromadzenia danych w celu modyfikacji RL przy użyciu potężnych LLM, jak GPT-4. Metoda t\\ została po raz pierwszy zbadana przez projekt Constitutional AI firmy Anthropic, w którym LLM zostały wykorzystane do syntetycznego generowania danych dot. szkodliwości. Podejście to zostało później rozszerzone przez Google RLAIF, który zautomatyzował cały proces gromadzenia danych dla RLHF, wykorzystując LLM do generowania danych syntetycznych. Wyniki były zaskakująco skuteczne. Tak więc, choć sam Q* nie zobaczymy tego, co eksperci nazywają AGI. Będzie to bliższe mieszance ekspertów z każdą z dziesiątek sztucznej inteligencji wykorzystującą konkretną sztuczną inteligencję.








