Wstęp
Kiedy zaczynasz swoją przygodę z Dockerem, wszystko wydaje się proste i intuicyjne. Pakujesz aplikację w obraz, uruchamiasz kontener, mapujesz porty i… działa! To trochę jak pierwszy projekt, który z dumą pokazujesz zespołowi z komentarzem „u mnie działa”.
Z czasem jednak aplikacja rośnie. Dochodzą kolejne serwisy, baza danych, cache, frontend, zadania batchowe. Wtedy na ratunek przychodzi Docker Compose, który pozwala spinać wiele kontenerów w jedną całość. Na początku to świetna pomoc – jeden plik YAML i odpalasz cały stos poleceniem docker compose up.
Problem w tym, iż i Compose ma swoje ograniczenia. Skalowanie aplikacji? Trzeba ogarniać manualnie. Odporność na awarie? Brak. Aktualizacje bez przestojów czy monitoring? Nie w standardzie. I nagle okazuje się, iż choćby Compose nie rozwiązuje wszystkich problemów.
Właśnie w tym momencie na scenę wchodzi Kubernetes (K8s) – platforma, która przejmuje rolę dyrygenta i ogarnia uruchamianie, skalowanie i utrzymanie kontenerów w spójny, przewidywalny sposób. Możesz myśleć o nim jak o systemie operacyjnym dla całego centrum danych: pilnuje, żeby faktyczny stan aplikacji był zgodny z tym, co zadeklarujesz w konfiguracji.
W tym wpisie pokażę Ci, dlaczego sam Docker to za mało i jakie problemy rozwiązuje Kubernetes. Omówimy jego architekturę i podstawowe obiekty, takie jak Pod, Deployment czy Service. Zastanowimy się też, kiedy Kubernetes faktycznie ma sens, a kiedy to przerost formy nad treścią, porównamy go z Docker Swarm i przygotujemy lokalne środowisko z Minikube lub Kind oraz kubectl, żebyś był gotowy do kolejnej części z praktycznym przykładem.
Mam Dockera, po co mi więcej?
Docker jest fantastycznym narzędziem. Umożliwia nam budowanie i uruchamianie kontenerów w powtarzalny sposób. Do zarządzania kilkoma kontenerami na jednej maszynie świetnie nadaje się Docker Compose. Pozwala w prostym pliku YAML zdefiniować całą aplikację składającą się z backendu, frontendu i bazy danych. Jedną komendą docker compose up stawiamy całe środowisko. To idealne rozwiązanie na potrzeby deweloperskie i dla małych, prostych projektów.
Jednak kiedy przenosimy się do świata produkcyjnego, gdzie liczy się niezawodność, skalowalność i automatyzacja, Docker Compose przestaje wystarczać. Pojawiają się problemy, których nie rozwiązuje on w satysfakcjonujący sposób.
Problem #1: Skalowanie i równoważenie obciążenia (Load Balancing)
Wyobraź sobie, iż Twoja aplikacja zaczyna łapać popularność i jeden kontener z backendem nie daje już rady. Trzeba go przeskalować, czyli odpalić kilka identycznych kopii. W czystym Dockerze gwałtownie robi się pod górkę.
Najpierw musiałbyś manualnie zalogować się na każdą maszynę i uruchomić dodatkowe kontenery. Potem dochodzi kwestia rozdzielania ruchu – jak sprawić, żeby użytkownicy trafiali równomiernie do wszystkich instancji? Do tego potrzebny byłby zewnętrzny load balancer, np. Nginx czy HAProxy, który zna adresy każdego kontenera. A co w momencie, gdy dodasz nowy kontener albo któryś padnie? Konfigurację load balancera trzeba zmienić manualnie. I tak w kółko – czasochłonne, podatne na błędy i mało skalowalne.
Problem #2: Odporność na awarie (High Availability)
Środowisko produkcyjne bywa nieprzewidywalne. Kontener może paść przez błąd w aplikacji, a cała maszyna wirtualna przestać odpowiadać z powodu awarii sprzętu czy sieci. I co wtedy?
Docker sam z siebie nie poradzi sobie z takim scenariuszem. jeżeli kontener padnie, to bez dodatkowej konfiguracji nie zostanie automatycznie uruchomiony ponownie (a choćby proste flagi restartu nie rozwiązują wszystkich problemów). jeżeli padnie cały serwer, kontenery działające na nim przepadają.
W praktyce oznacza to konieczność manualnego odtwarzania środowiska: monitoring zgłasza awarię, Ty logujesz się na serwer, stawiasz nowy kontener – czasem na innej maszynie – i aktualizujesz load balancer. Efekt? Przestój aplikacji i nerwowe godziny dla zespołu.
Problem #3: Zarządzanie i aktualizacje
Samo uruchomienie aplikacji to dopiero początek. Trzeba jeszcze zadbać o jej aktualizacje, konfigurację i bezproblemową komunikację między komponentami.
Weźmy aktualizacje: w idealnym scenariuszu chcielibyśmy wdrażać nową wersję stopniowo, podmieniając kontenery jeden po drugim (rolling update), tak żeby użytkownicy nie odczuli przestoju. W czystym Dockerze wymaga to jednak ręcznych skryptów i sporej koordynacji.
Do tego dochodzi zarządzanie konfiguracją i sekretami. Hasła do baz danych, klucze API czy tokeny wrzucone luzem do plików konfiguracyjnych na kilku serwerach to proszenie się o kłopoty – zarówno z bezpieczeństwem, jak i z utrzymaniem.
No i sieci. Kontenery muszą ze sobą rozmawiać, najlepiej w prosty i bezpieczny sposób. Problem w tym, iż domyślne sieci Dockera działają tylko w obrębie jednej maszyny. jeżeli chcesz, żeby kontenery na różnych hostach widziały się nawzajem, musisz manualnie kombinować z konfiguracją sieciową.
Kubernetes – dyrygent w świecie kontenerów
Gdy już wiemy, jakie wyzwania stoją przed nami przy zarządzaniu aplikacjami na dużą skalę, możemy przedstawić rozwiązanie. Kubernetes, często skracany do K8s (8 liter między „K” a „s”), to otwarty system do automatyzacji wdrażania, skalowania i zarządzania skonteneryzowanymi aplikacjami. Został pierwotnie zaprojektowany przez Google, a w tej chwili jest rozwijany przez Cloud Native Computing Foundation (CNCF).
Co to jest orkiestracja
Orkiestracja to w praktyce zautomatyzowane zarządzanie złożonymi systemami. Najłatwiej porównać ją do orkiestry symfonicznej: każdy muzyk, czyli kontener, gra swoją partię, ale dopiero dyrygent nadaje całości rytm i pilnuje, żeby wszyscy trzymali tempo.
W świecie IT tym dyrygentem jest Kubernetes, który odpowiada za:
- Planowanie (scheduling) – wybiera, na którym serwerze (nodzie) uruchomić kontener, biorąc pod uwagę dostępne zasoby (CPU, pamięć).
- Zarządzanie cyklem życia – dba o ciągłość działania aplikacji; jeżeli kontener padnie, Kubernetes uruchamia nowy.
- Skalowanie – automatycznie zwiększa lub zmniejsza liczbę instancji w zależności od obciążenia.
- Zapewnianie komunikacji – zapewnia, iż kontenery mogą się odnaleźć i komunikować choćby wtedy, gdy działają na różnych maszynach.
- Obsługa aktualizacji – umożliwia wdrażanie nowych wersji krok po kroku (rolling update), bez przestojów dla użytkowników.
Kubernetes to kompletna platforma – dostajemy gotowy zestaw klocków do budowania systemów, które nie padają przy pierwszej awarii i radzą sobie ze wzrostem ruchu.
Architektura Kubernetes
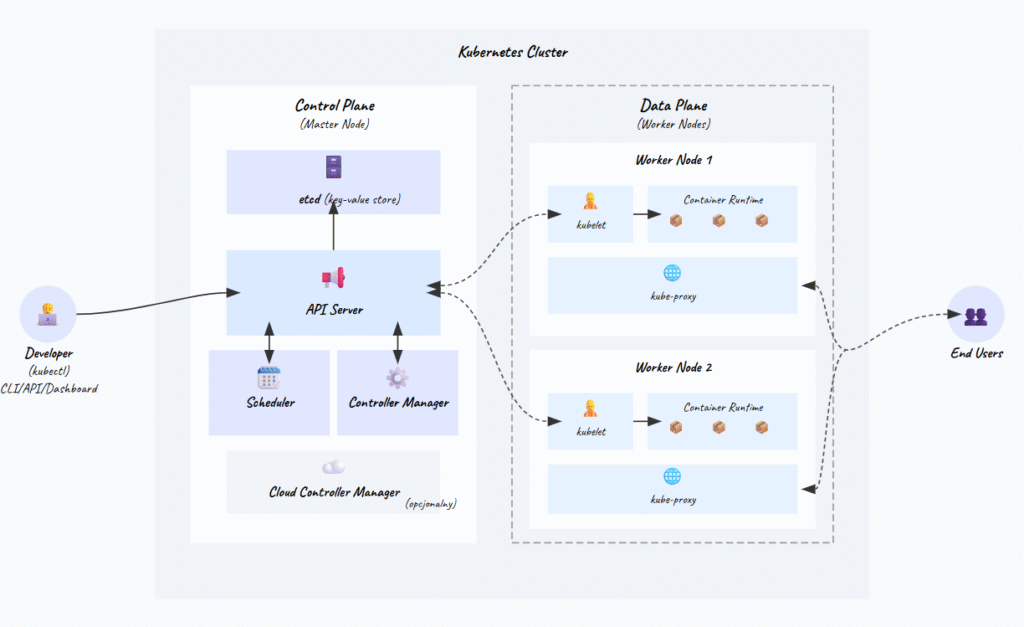
Kubernetes działa na zasadzie klastra, czyli grupy połączonych ze sobą maszyn (fizycznych lub wirtualnych), które współpracują, aby uruchamiać Twoje aplikacje. Każdy klaster składa się z co najmniej dwóch głównych typów komponentów: Control Plane (płaszczyzna sterowania) oraz Worker Nodes (węzły robocze).
Control Plane (Master Node)
Control Plane to centrum dowodzenia klastrem. To on decyduje, gdzie uruchomić nowe kontenery i reaguje, gdy coś się wysypie. Składa się z kilku kluczowych elementów, które zwykle działają na dedykowanej maszynie (albo na kilku, jeżeli chcemy wysoką dostępność):
- API server (kube-apiserver) – serce komunikacji. Wszystkie operacje – czy to od użytkownika, czy od innych komponentów – przechodzą przez API server. Udostępnia on REST-owe API, przez które komunikujemy się z klastrem (np. dzięki narzędzia kubectl).
- etcd – To niezawodna, rozproszona baza danych typu klucz-wartość. Pełni rolę „jedynego źródła prawdy” dla całego klastra. Przechowuje w sobie całą konfigurację i stan klastra – informacje o wszystkich uruchomionych aplikacjach, węzłach, konfiguracjach sieciowych itp. Komunikacja odbywa się poprzez kube-apiserver.
- Scheduler (kube-scheduler) – Jego zadaniem jest przydzielanie nowo utworzonych „jednostek pracy” (zwanych Podami, o których za chwilę) do konkretnych węzłów roboczych (Worker Nodes). Scheduler analizuje wymagania poda (np. zapotrzebowanie na CPU i pamięć) oraz dostępność zasobów na poszczególnych węzłach i wybiera najlepsze miejsce do jego uruchomienia.
- Controller Manager (kube-controller-manager) – To zestaw różnych kontrolerów, które działają w tle i pilnują, aby aktualny stan klastra zgadzał się ze stanem pożądanym, zapisanym w etcd. Przykładowo, jeżeli zdefiniujesz, iż Twoja aplikacja ma zawsze działać w 3 kopiach, a jedna z nich ulegnie awarii, to właśnie jeden z kontrolerów zauważy tę rozbieżność i zleci schedulerowi uruchomienie nowej kopii.
- Cloud Controller Manager (Opcjonalny) – Ten komponent integruje klaster z API konkretnego dostawcy chmury (jak AWS, Google Cloud czy Azure). Zarządza zasobami specyficznymi danej chmury, takimi jak load balancery, wolumeny dyskowe czy sieci. Dzięki oddzieleniu tej logiki od głównego kube-controller-manager, Kubernetes pozostaje niezależny od platformy, na której działa. Można go porównać do specjalistycznego tłumacza, który pozwala dyrygentowi (klastrowi) komunikować się z obsługą techniczną konkretnej sali koncertowej (dostawcy chmury), aby zamówić dodatkowe oświetlenie (load balancer) czy krzesła (dyski).
Data Plane (Worker Nodes)
Węzły robocze (Worker Nodes) to maszyny, na których faktycznie uruchamiane są Twoje aplikacje w kontenerach. Każdy węzeł jest zarządzany przez Control Plane i zawiera kilka niezbędnych komponentów:
- kubelet – To agent działający na każdym węźle. Komunikuje się z Control Plane i wykonuje jego polecenia. Kubelet pobiera specyfikacje podów z API Servera i upewnia się, iż kontenery są uruchomione i zdrowe.
Kubelet to jak brygadzista na budowie – dostaje plany z centrali i pilnuje, żeby robotnicy (kontenery) wykonali robotę. Regularnie raportuje status do Control Plane, wykonuje health checki, restartuje kontenery jeżeli trzeba. - kube-proxy – Zarządza regułami sieciowymi na węźle. Odpowiada za to, iż pody mogą komunikować się między sobą i ze światem zewnętrznym. Implementuje część abstrakcji Service – przekierowuje ruch do odpowiednich podów.
Kube-proxy może działać w różnych trybach (iptables, IPVS), ale cel jest ten sam – zapewnić, iż pakiety trafiają tam, gdzie powinny. To jak centralka telefoniczna – przekierowuje połączenia do adekwatnego odbiorcy. - Container Runtime – To oprogramowanie odpowiedzialne za faktyczne uruchamianie kontenerów. Kubernetes jest elastyczny i wspiera różne środowiska uruchomieniowe, które implementują jego interfejs (Container Runtime Interface – CRI). Najpopularniejsze z nich to containerd i CRI-O. W przeszłości Kubernetes korzystał z dockershim do komunikacji z Docker Engine, ale od wersji 1.24 ten adapter został usunięty na rzecz bezpośredniej komunikacji z containerd.
Runtime pobiera obrazy, tworzy kontenery, zarządza ich cyklem życia. To jak silnik w samochodzie – możesz mieć różne marki, ale wszystkie robią to samo – napędzają pojazd.
Podstawowe elementy budujące aplikacje w Kubernetes
Teraz gdy znamy już architekturę, przyjrzyjmy się podstawowym obiektom (klockom), z których budujemy aplikacje w Kubernetes. Na tym etapie opiszemy je krótko, tak, żeby chociaż było wiadomo, iż takie elementy/nazwy istnieją, a w kolejnych wpisach będziemy się w nie zagłębiać.
Node
Jak już wiemy, to maszyna robocza (fizyczna lub wirtualna) w klastrze, na której uruchamiane są Pody.
Pod
To najmniejsza i podstawowa jednostka, jaką można wdrożyć w Kubernetes. Pod reprezentuje pojedynczą instancję Twojej aplikacji. Co ważne, Pod może zawierać jeden lub więcej kontenerów. Wszystkie kontenery w ramach jednego Poda działają na tym samym węźle, współdzielą tę samą sieć i mogą komunikować się ze sobą przez localhost. zwykle jednak w jednym Podzie umieszczamy jeden główny kontener aplikacji.
Deployment
To obiekt wyższego rzędu, który zarządza Podami. W definicji Deploymentu określasz stan pożądany, np. „chcę, aby działały 3 identyczne Pody z obrazem mojej aplikacji w wersji 1.0”. Deployment dba o to, aby ta liczba podów zawsze była utrzymana. Co więcej, to właśnie Deployment pozwala na realizację aktualizacji bez przestojów (rolling updates) – wystarczy, iż zmienisz wersję obrazu w jego definicji, a on sam zajmie się stopniową podmianą starych Podów na nowe.
Service
Pody są nietrwałe – mogą być niszczone i tworzone na nowo, za każdym razem otrzymując nowy adres IP. Jak w takim razie inne części aplikacji (lub użytkownicy z zewnątrz) mają się z nimi komunikować? Tutaj z pomocą przychodzi Service. Service tworzy stabilny, wirtualny punkt dostępowy (stały adres IP i nazwa DNS wewnątrz klastra) dla grupy Podów. Przekierowuje on ruch do aktualnie działających, „zdrowych” Podów zarządzanych np. przez Deployment.
Ingress
Wyobraź sobie, iż Twoja aplikacja działa w klastrze, a Service nadał jej wewnętrzny adres. Tylko iż to za mało – użytkownicy muszą móc wejść na stronę pod normalnym adresem, np. www.mojastrona.pl. Tutaj wchodzi Ingress. To on przyjmuje ruch z zewnątrz i na podstawie zdefiniowanych reguł kieruje go do odpowiednich usług wewnątrz klastra. Możesz np. ustawić, iż zapytania na mojastrona.pl/sklep trafią do serwisu sklepu, a mojastrona.pl/blog do serwisu bloga. Żeby Ingress działał, w klastrze musi być zainstalowany Ingress Controller (np. Nginx), który te reguły egzekwuje.
Namespace
Wyobraź sobie, iż jeden klaster Kubernetes jest używany przez kilka zespołów deweloperskich. Jak zapobiec konfliktom nazw, np. gdy każdy zespół chce wdrożyć swoją bazę danych o nazwie postgres-db? Do tego właśnie służą Namespace’y. Działają jak wirtualne klastry wewnątrz fizycznego klastra, pozwalając na logiczne odizolowanie zasobów. Każdy zespół może pracować we własnym Namespace, nie martwiąc się o kolizje z innymi.
ConfigMap
Jak zarządzać konfiguracją aplikacji (np. adresem URL do zewnętrznego API, flagami funkcjonalności) bez konieczności przebudowywania obrazu Dockera za każdym razem, gdy coś się zmieni? ConfigMap to obiekt służący do przechowywania danych konfiguracyjnych w formie par klucz-wartość. Konfigurację tę można następnie wstrzyknąć do Podów jako zmienne środowiskowe lub pliki, co oddziela konfigurację od kodu aplikacji.
Secret
To obiekt bardzo podobny do ConfigMap, ale przeznaczony specjalnie do przechowywania wrażliwych danych, takich jak hasła, tokeny API czy certyfikaty SSL. Dane w Secretach są przechowywane w sposób, który Kubernetes traktuje jako poufny (np. domyślnie są kodowane w base64 i można kontrolować dostęp do nich). Używanie Secretów to standardowa praktyka pozwalająca uniknąć umieszczania haseł w kodzie źródłowym czy obrazach kontenerów.
Kiedy Kubernetes ma sens, a kiedy to overkill?
Kubernetes jest niezwykle rozbudowanym narzędziem, ale jak każda technologia, nie jest rozwiązaniem wszystkich problemów. Jego wdrożenie i utrzymanie wiąże się z pewną złożonością i krzywą uczenia. Zanim zdecydujesz się na jego użycie, warto zadać sobie pytanie: czy naprawdę go potrzebuję?
Kiedy Kubernetes jest świetnym wyborem?
Kiedy więc Kubernetes naprawdę ma sens? Nie zawsze warto sięgać po tak rozbudowaną platformę, ale są scenariusze, w których jego użycie po prostu się broni.
- Architektura mikroserwisów – jeżeli Twoja aplikacja składa się z wielu małych, niezależnych usług, K8s daje Ci środowisko, w którym łatwo nimi zarządzać, skalować je osobno i zapewnić im sprawną komunikację.
- Wysoka dostępność i skalowalność – gdy Twoja aplikacja musi działać bez przerw i być gotowa na nagłe wzrosty ruchu, mechanizmy samo naprawiania i automatycznego skalowania w K8s są nieocenione.
- Standaryzacja wdrożeń – w dużych organizacjach, gdzie wiele zespołów pracuje nad różnymi projektami, Kubernetes pozwala na ujednolicenie procesu wdrażania, monitorowania i zarządzania aplikacjami.
- Przenośność między chmurami – Kubernetes działa tak samo na AWS, Google Cloud czy Azure. Dzięki temu nie przywiązujesz się do jednego dostawcy i możesz swobodnie przenosić aplikacje.
Kiedy Kubernetes może być przesadą (overkill)?
Nie zawsze jednak Kubernetes to dobry wybór. W wielu przypadkach sięgnięcie po niego oznacza więcej problemów niż realnych korzyści.
- Proste aplikacje monolityczne – jeżeli masz jedną, spójną aplikację, która nie wymaga skomplikowanego skalowania, prostsze rozwiązania jak Docker Compose na jednej maszynie lub platformy typu PaaS (Platform as a Service) jak Heroku mogą być w zupełności wystarczające i znacznie prostsze w obsłudze.
- Małe projekty i wczesny etap startupu – na początku drogi ważniejsza jest szybkość iteracji i dostarczania produktu. Złożoność K8s może spowolnić rozwój. Lepiej zacząć od czegoś prostszego i migrować na Kubernetesa, gdy projekt dojrzeje i pojawią się realne problemy ze skalowaniem.
- Brak wiedzy w zespole – zarządzanie klastrem Kubernetes wymaga specjalistycznej wiedzy. jeżeli w zespole nie ma nikogo z doświadczeniem w tej dziedzinie, koszty nauki i potencjalnych błędów mogą przewyższyć korzyści. W takiej sytuacji lepszym wyborem mogą być zarządzane usługi Kubernetes oferowane przez dostawców chmurowych (np. EKS w AWS, GKE w Google Cloud), które zdejmują z nas część obowiązków administracyjnych.
Kubernetes vs Docker Swarm
Kiedy mówimy o orkiestracji, obok Kubernetesa często pojawia się nazwa Docker Swarm. To rozwiązanie twórców Dockera, które miało być prostszym sposobem na zarządzanie wieloma kontenerami. Ale jak te dwa światy naprawdę się różnią?
Krzywa uczenia. Kubernetes jest zdecydowanie bardziej złożony i wymaga zrozumienia sporej liczby pojęć, jak Pody, Deploymenty czy Serwisy. Swarm działa jak naturalne rozszerzenie Dockera, więc wejście w niego jest dużo prostsze.
Jeśli chodzi o możliwości, Kubernetes bije Swarma na głowę. Oferuje ogromne API, tysiące opcji konfiguracji i potężny ekosystem narzędzi. Swarm skupia się na podstawowych zadaniach i nie wychodzi zbytnio poza ten zakres.
Pod względem skalowalności, Kubernetes został zaprojektowany z myślą o gigantach i działa w naprawdę ogromnych klastrach. Swarm daje radę, ale generalnie uchodzi za mniej wydajny.
Dochodzi jeszcze społeczność i ekosystem. Kubernetes to dziś standard branżowy, wspierany przez wszystkie duże firmy technologiczne. Swarm ma mniejszą, mniej aktywną społeczność, a jego rozwój mocno spowolnił.
No i wysoka dostępność – Kubernetes ma wbudowane mechanizmy samo naprawiania i radzenia sobie z awariami. Swarm oferuje tylko podstawy.
Podsumowując: Swarm jest prostszy w obsłudze, ale Kubernetes wygrał wojnę o orkiestrację. To on stał się branżowym standardem i jeżeli dziś zaczynasz naukę, a myślisz o pracy w nowoczesnych firmach technologicznych, to postawienie na K8s będzie znacznie lepszą inwestycją w przyszłość.
Przygotowanie lokalnego środowiska
Wiadomo, teoria jest ważna, ale najlepsza nauka to praktyka. Zanim w kolejnym wpisie uruchomimy naszą pierwszą aplikację, musimy przygotować lokalne środowisko. Będziemy potrzebować dwóch rzeczy:
- kubectl : To narzędzie wiersza poleceń (CLI), które służy do komunikacji z klastrem Kubernetes. Za jego pomocą będziemy wydawać wszystkie polecenia, np. tworzyć Deploymenty czy sprawdzać status Podów.
- Lokalny klaster Kubernetes: Potrzebujemy działającego klastra, z którym kubectl będzie mógł się połączyć. Utrzymywanie pełnoprawnego, wielowęzłowego klastra jest kosztowne i skomplikowane, dlatego na potrzeby nauki i dewelopmentu użyjemy narzędzi, które pozwalają uruchomić prosty, jednowęzłowy klaster na naszym komputerze. Trzy najpopularniejsze to Minikube, Kind lub MicroK8s.
Minikube tworzy maszynę wirtualną (lub używa kontenera Docker) na Twoim komputerze i instaluje w niej wszystkie komponenty Kubernetesa. Jest bardzo dojrzałym i bogatym w funkcje projektem.
Kind (Kubernetes in Docker) to nowsze podejście, które uruchamia każdy węzeł klastra jako kontener Dockera. Jest lżejszy i szybszy w uruchamianiu niż Minikube, ale wymaga działającego Dockera na maszynie.
MicroK8s to lekka dystrybucja od Canonical (twórców Ubuntu), dostarczana jako pojedynczy pakiet, co upraszcza instalację. Dedykowana pod Linuxa.
Z każdego z tych narzędzi moglibyśmy skorzystać do utworzenia lokalnego klastra, ale na potrzeby naszej serii wykorzystamy najprostsze narzędzie jakim jest Docker Desktop (jeśli nie masz lokalnie zainstalowanego to opisałem to tutaj jak zainstalować Docker Desktop lokalnie). Z jego poziomu zainstalujemy sobie lokalnie wersje Kind.
Konfiguracja Docker Desktop pod klaster Kubernetes
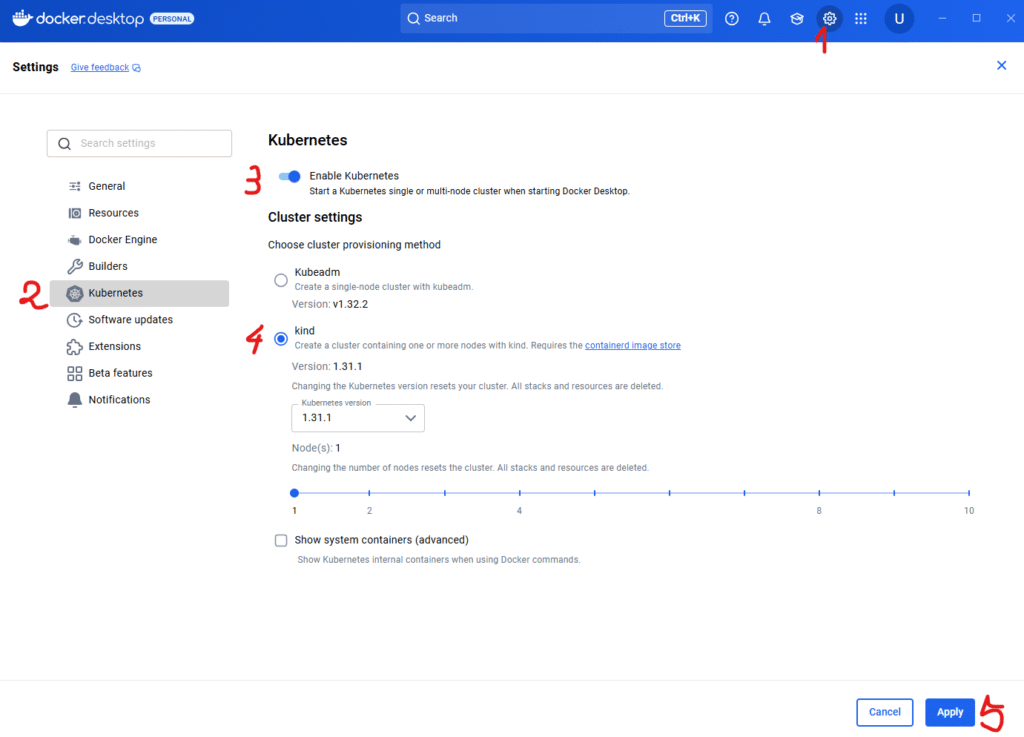
W celu konfiguracji Kubernetsa na Docker Desktop wykonujemy:
- W prawym górnym rogu wybieramy zakładkę z zębatki, aby wejść w ustawienia Docker Desktop.
- W menu po lewej wybieramy zakładkę Kubernetes.
- Ustawiamy na włączony przełącznik. Umożliwia on obsługę Kubernetes w Docker Desktop. Dzięki temu Docker może działać jako lokalny klaster K8s.
- W tym miejscu decydujemy, jak Docker Desktop ma utworzyć klaster Kubernetes:
- Kubeadm – tworzy prosty, jedno-nodowy klaster z wykorzystaniem narzędzia kubeadm. To bardziej „surowa” opcja, przydatna jeżeli chcesz poznać podstawy konfiguracji Kubernetesa i zobaczyć, jak działa od środka. Zwykle wybierają ją osoby, które chcą bardziej zbliżonego do produkcji środowiska testowego.
- Kind (Kubernetes in Docker) – uruchamia klaster w postaci kontenerów Dockera. To szybki i lekki sposób na postawienie K8s lokalnie, idealny do nauki, testów i eksperymentów. Możesz wybrać wersję Kubernetes oraz liczbę nodów, jakie mają działać w tym klastrze. W naszym przykładzie wybraliśmy tę opcję.
- Po skonfigurowaniu wszystkiego w prawym dolnym rogu klikamy Apply, żeby Docker Desktop zrestartował się i uruchomił Kubernetesa z wybranymi ustawieniami.
Po restarcie Dockera powinniśmy już móc korzystać z Kubernetsa. W celu weryfikacji. odpalmy terminal i sprawdźmy czy możemy wykonywać komendy z kubectl. Wykonajmy przykładową komendę np. sprawdźmy jakie Nody nam się utworzyły:

Jeśli dostałeś podobny wynik to oznacza, iż udało Ci się zainstalować Kubernetsa!
Podsumowanie
Dotarliśmy do końca wprowadzenia do Kubernetesa. Zobaczyliśmy, dlaczego sam Docker w produkcji gwałtownie okazuje się niewystarczający, jak orkiestracja rozwiązuje problemy ze skalowaniem i niezawodnością, poznaliśmy architekturę klastra z Control Plane i nodami roboczymi oraz podstawowe klocki – Pody, Deploymenty i Serwisy. Na koniec przygotowaliśmy lokalne środowisko z kubectl i uruchomiliśmy klaster w Kind przy pomocy Docker Desktop, budując solidny fundament pod dalszą praktykę.
W kolejnym wpisie na tym przygotowanym środowisku postawimy naszą pierwszą aplikację. Przygotujemy pierwszy deployment i service w Kubernetes, a także uruchomimy aplikację krok po kroku.
Daj znać, czy ten wpis Ci się podobał i czy chciałbyś więcej wpisów na blogu w tematyce Kubernetsa.














