– Hej tato, pobawisz się z nami? – przybiegły z pytaniem Jagódka i Otylka.
– Jeszcze chwilkę Księżniczki. Dokończę tylko jedną bardzo istotną rzecz i się pobawimy – odpowiedziałem.
– A co lobisz tatusiu? – zapytała Otylka.
– Buduję model do wykrywania anomalii w transakcjach, aby uratować naszych klientów przed oszustami.
Dziewczyny spojrzały na siebie z krzywym wyrazem twarzy dając mi do zrozumienia, iż nie wiedzą, o co chodzi.
– Spójrzcie na tę półeczkę z waszymi pracami z przedszkola. Czy jest tutaj coś, co wam nie pasuje? – zapytałem.
– Tak! Ten obrazek po prawej! Bo to obrazek narysowany nie przez nas, tylko przez nasze kuzynki Nadusię i Wiki!
– Brawo! Znalazłyście waszą pierwszą anomalię – uśmiechnąłem się!
Wykrywanie anomalii znajduje bardzo szerokie zastosowanie w wielu różnych dziedzinach (więcej o tym za chwilę).

Często zamiast o wykrywaniu anomalii mówimy o wykrywaniu wartości odstających. Dla większości te terminy są synonimami, ale jednak jest między nimi drobna różnica.
Co to jest anomalia?
W data science anomalie są często określane jako punkty danych niezgodne z oczekiwanym wzorcem innych elementów w zestawie danych. Czyli możemy określić, iż anomalie są innym rozkładem występującym w ramach dystrybucji danych.
Nadal nie jest to jasne? Pomyśl o zwykłych transakcjach kartowych wykonywanych przez przeciętnego Kowalskiego. Mają one swój rozkład zachowania: wpływ wynagrodzenia, opłaty za rachunki, opłaty w sklepach. A tutaj nagle pojawia się przelew na 2.000$ do Dubaju, w którym Kowalski nigdy nie był i nigdy nic tam nie kupił. To właśnie ta transakcja miała całkiem inny rozkład niż pozostałe.
Zatem wykrywanie anomalii odnosi się do problemu znajdowania wzorców w danych niezgodnych z oczekiwanym zachowaniem.

Co to jest wartość odstająca?
Wartość odstająca (ang. outlier) to obserwacja posiadająca nietypową wartość zmiennej. Inaczej mówiąc, jest to punkt danych oddalony od innych obserwacji.
Obserwacje odstające mogą odzwierciedlać rzeczywisty rozkład lub być rezultatem przypadku. Na przykład mogą być błędnym pomiarem, być pomyłką przy wprowadzaniu danych lub wynikać ze zmienności pomiaru.
Należy uważać na wartości odstające, ponieważ jeżeli ich nie wykryjesz i nie obsłużysz, mogą znacząco wpłynąć na przewidywania i dokładność użytego modelu.
Wartość odstająca vs anomalia
Dla mnie różnica między anomalią i wartością odstającą jest bardzo subtelna i zwykle nie ma znaczenia. Oba pojęcia odnoszą się do punktów danych mających wyjątkowo niskie prawdopodobieństwo wystąpienia.
Subtelna różnica polega na tym, iż nazwanie czegoś anomalią sugeruje, iż masz hipotezę wygenerowania jej przez inny proces niż ten generujący normalne dane. Nazywanie tego wartością odstającą jest bardziej opisowe i nie wyklucza, iż jest to statystyczny przypadek. Można również powiedzieć, iż anomalia odbiega od oczekiwań modelu, podczas gdy wartość odstająca odbiega od większości danych.
Nazywanie obserwacji lub wartości odstającą sugeruje, iż masz plan jak sobie z nią poradzić, tj. iż zamierzasz ją traktować jako odstającą.
Ciekawostką jest, iż analitycy danych chętniej korzystają z pojęcia wartości odstającej, a eksperci z anomalii.

Co to jest wykrywanie anomalii?
Wykrywanie anomalii to techniki używane do identyfikowania i znajdowania nietypowych wzorców niezgodnych z oczekiwanym zachowaniem. Mówiąc prościej są to metody pozwalające określić, co w zbiorze danych jest „normalne” a co nie.
Wykrywanie anomalii polega na zdefiniowaniu granicy wokół normalnych punktów danych tak, aby można było je odróżnić od wartości odstających.
Wykrywanie anomalii oparte na sztucznej inteligencji pozwala nam gwałtownie analizować ogromne ilości danych i podkreśla przydatne informacje!
Dlaczego wykrywanie anomalii jest ważne?
Moim zdaniem bardzo ważne jest to, abyśmy zawsze byli w stanie zidentyfikować zmieniającą się rzeczywistość i podjąć na podstawie tego działania. Zmiany mogą być nieistotne… ale mogą stanowić szkodliwe wydarzenie w firmie lub pozytywną okazję do rozwoju! A nie chcemy takich rzeczy przeoczyć!
Otrzymując alerty o anomaliach, użytkownicy mogą odróżnić nieistotne zmiany od tych nietypowych. Dzięki temu można zaoszczędzić mnóstwo czasu, ponieważ eksperci domenowi skupią się na najciekawszych i najważniejszych przypadkach, zamiast przeglądać wszystkie dane.
Niedawno w pracy przygotowałem model do wykrywania transakcji fraudowych. Dzięki niemu eksperci otrzymywali alerty tylko z wysokim prawdopodobieństwem fraudu i mogli się skoncentrować tylko na tych przypadkach. Zatem ważne jest, aby model prawidłowo odróżnił sygnał od szumu i skupił się na tym, co naprawdę istotne dla danego zadania.

Przykłady zastosowania wykrywania anomalii
Wydaje mi się, iż nie ma dziedziny, w której nie znaleźlibyśmy jakiegoś zastosowania dla wykrywania anomalii. Poniżej kilka przykładów:
- znajdowanie wadliwych przedmiotów,
- wykrywanie zużytych części maszyn w celu wcześniejszego wykrycia ich potencjalnego zniszczenia,
- wyszukiwanie włamań w systemie w celu zapewnienia cyberbezpieczeństwa,
- wykrywanie oszustw (na szczęście są rzadkie i możemy je potraktować jako anomalie) czy to na kartach kredytowych, czy we wnioskach kredytowych lub ubezpieczeniowych,
- w marketingu do wyłapywania zmian w konwersji działań marketingowych,
- znajdowanie guzów na zdjęciach rentgenowskich,
- wyszukiwanie niestandardowych wzorców w logach produkcyjnych,
- monitorowanie systemów administracyjnych,
- wykrywanie złośliwego oprogramowania,
- monitorowanie pacjentów w szpitalach,
- wykrywanie fałszywych dokumentów np. dowodów osobistych,
- znajdowanie anomalii w raportach,
- wykrywanie anomalii po aktualizacji systemu, np. w celu znalezienia czy dana bramka płatności na stronie przestała działać,
- przewidywanie katastrofalnych zdarzeń pogodowych,
- wykrywanie błędów w systemach o znaczeniu krytycznym dla bezpieczeństwa,
- i wiele innych.
Podziały wykrywania anomalii
Czytając literaturę o wykrywaniu anomalii znalazłem dwa sposoby ich podziału.
Podział czy mamy oznaczone anomalie
Uczenie nadzorowane (Supervised learning)
W tym kontekście anomalie zostałyby oznaczone w danych historycznych, co może zająć dużo czasu i wysiłku. Jednak dzięki temu znacznie łatwiej jest określić, co stanowi anomalię w przyszłości! Z doświadczenia powiem, iż najlepiej w przypadku moich danych i zadań działały algorytmy typu gradient boosting (np. XGBoost).
Uczenie nienadzorowanane (Unsupervised learning)
W tym kontekście anomalie nie są oznaczane w danych treningowych bardziej odzwierciedlając stan rzeczywistych systemów operacyjnych. W takim przypadku system musi sam inteligentnie ocenić punkt danych, który może być anomalią i zwrócić o tym informacje. Z mojego doświadczenia wynika, iż w tym przypadku dla moich danych świetnie zadziałały autoencodery i las izolacji.
Podział ze względu na działanie metody
Wykrywanie anomalii w podejściu statystycznym
Wykorzystanie metod statystycznych, które zostały wymyślone i opracowane dawno temu jest najłatwiejszym sposobem na wykrycie wartości odstających. Jedną z najpopularniejszych jest tzw. przedział międzykwartylowy (IQR) lub odchylenia standardowe w rozkładzie normalnym.
Wykrywanie anomalii w oparciu o klastry
Podejście to skupia się na wykorzystaniu algorytmów klasteryzacji do łączenia punktów do tych samych grup (klastrów). Natomiast obserwacje najmniej pasujące do klastrów określamy jako wartości odstające.
Wykrywanie anomalii w oparciu o gęstość
Normalne punkty danych powinny występować w gęstym sąsiedztwie, a nieprawidłowości są zwykle bardzo odległe. Aby zmierzyć najbliższy zbiór punktów danych, możemy użyć odległości euklidesowej lub podobnej miary w zależności od typu posiadanych danych.
Sposoby wykrywania anomalii i wartości odstających
Poniżej przedstawiłem najczęściej wykorzystywane sposoby do wykrywania anomalii czy wartości odstających.
1. Odchylenie standardowe
W statystyce dla w przybliżeniu normalnych rozkładów danych:
- ~68% wartości mieści się w ramach jednego odchylenia standardowego średniej,
- ~95% mieści się w zakresie dwóch odchyleń standardowych,
- ~99,7% mieści się w ramach trzech odchyleń standardowych.
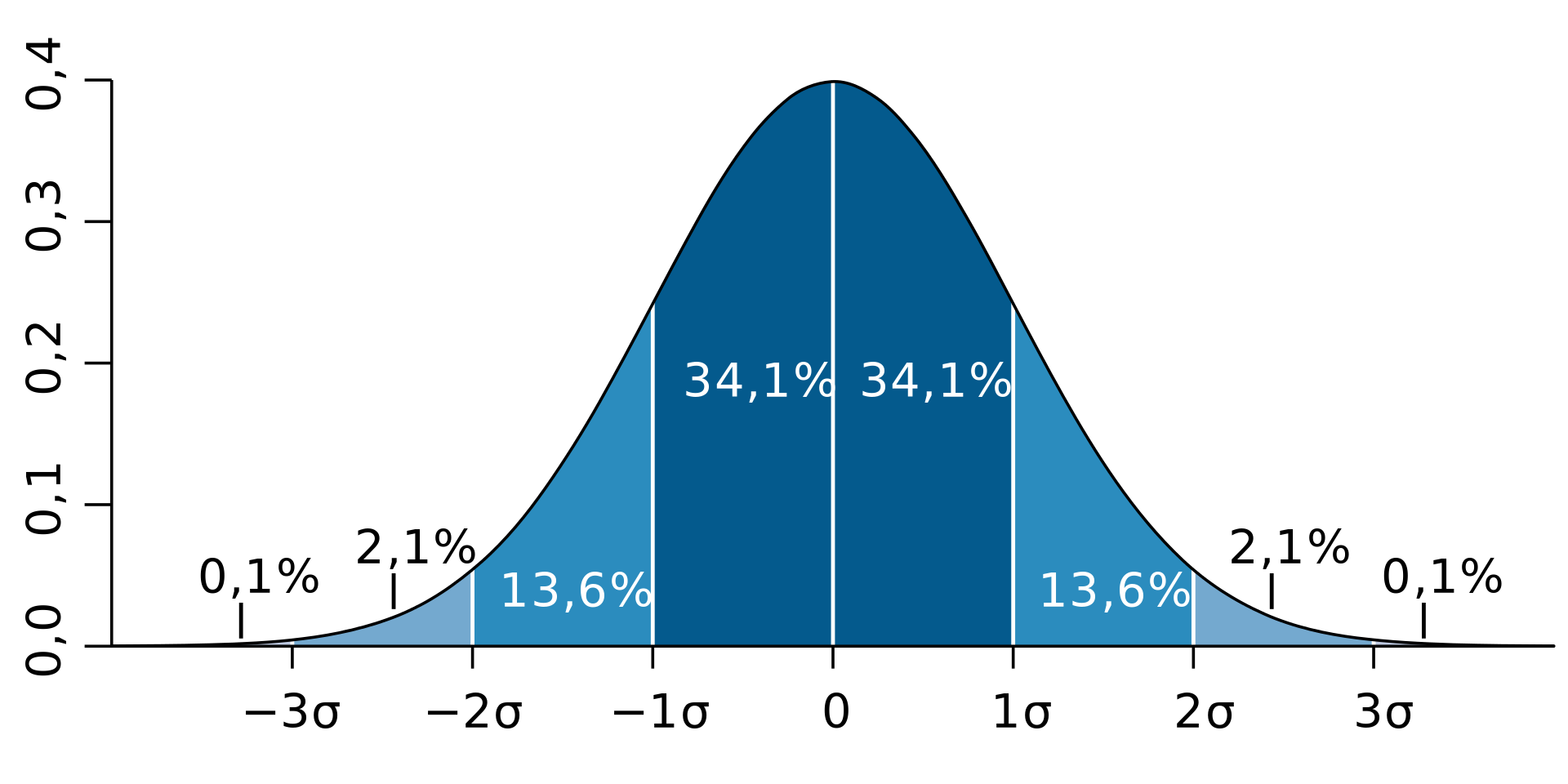 źródło
źródłoDlatego też, jeżeli jakiś punkt danych jest ponad 3 razy większy od odchylenia standardowego, wówczas będzie on najprawdopodobniej wartością odstającą.
2. Klastrowanie DBSCAN-em
DBSCAN jest algorytmem klastrowania używanym również jako metoda wykrywania anomalii na odstawie gęstości z danymi jedno- lub wielowymiarowymi. Algorytm wyszukuje tak zwane punkty podstawowe i punkty graniczne w ramach danych klastrów. Wszystko poza nimi nazywa się punktami szumu i może być traktowane jako obserwacje odstające.
3. Błąd rekonstrukcji w autoenkoderach
Na podstawie danych wejściowych można skonstruować autoencoder, a następnie wyliczyć błąd rekonstrukcji, czyli jak dobrze udało nam się odtworzyć pierwotne dane. Im większy błąd rekonstrukcji, tym większa anomalia. Przykład takiego wykorzystania znajdziesz TUTAJ.
4. Lokalny czynnik odstający (Local Outlier Factor)
Lokalny czynnik odstający, to technika wykorzystująca ideę najbliższych sąsiadów do wykrywania wartości odstających. Każdemu przykładowi przypisywana jest punktacja określająca, jak prawdopodobne jest wystąpienie wartości odstających na podstawie wielkości jego lokalnego sąsiedztwa. Im wyższy wynik, tym większe prawdopodobieństwo, iż są to wartości odstające.
5. Jedno klasowy SVM (One-Class SVM)
Maszyna wektorów nośnych (SVM) była algorytmem opracowanym do klasyfikacji binarnej, jednak może być używana także do klasyfikacji jednoklasowej. Zatem znajduje zastosowanie do wykrywania wartości odstających w danych wejściowych zarówno dla zestawów danych regresji, jak i klasyfikacji.
6. Las izolacji (ang. Isolation Forest)
Isolation Forest to nienadzorowany algorytm uczenia się należący do rodziny drzew decyzyjnych. To podejście wykorzystuje fakt, iż anomalie mają wartości zmienne bardzo różniące się od wartości normalnych. Ten algorytm działa świetnie z bardzo dużymi zbiorami danych wymiarowych i okazał się bardzo skutecznym sposobem wykrywania anomalii.
Podsumowanie
Jak widzicie wykrywanie anomalii możemy zastosować w wielu zagadnieniach i również mamy do dyspozycji wiele algorytmów. A jaki jest Twój ulubiony algorytm? Daj znać w komentarzu. Następnym razem rozwinę temat któregoś z algorytmów w szczegółach!
Pozdrawiam serdecznie z całego serducha,

Image by Pascal Laurent from Pixabay









.svg){kind=link}