
In May 2024, a preprint titled "Actions talk Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations" [1] was posted by Meta AI researchers to ArXiv. The preprint introduced a fresh recommender, referred to as 'HSTU' which stands for “Hierarchical Sequential Transduction Units” promising fresh state-of-the-art results for sequential advice tasks, as well as scalability to exceptionally large datasets.
Overview of HSTU
HSTU is yet another effort at adapting (modified) Transformers to generative recommendation, after DeepMind’s TIGER model (benchmarked in a erstwhile post). The most interesting properties of Meta AI’s HSTU architecture are:
- Pointwise Aggregated Attention:
- Uses a pointwise normalization mechanics alternatively of softmax normalization, making it suitable for non-stationary vocabularies in streaming settings.
- Captures the strength of user preferences and engagements effectively.
- Leveraging Sparsity:
- Efficient attention kernel designed for GPUs, transforming attention computation into grouped GEMMs.
- Algorithmically increases the sparsity of user past sequences via Stochastic dimension (SL), reducing computational cost without degrading model quality.
- Memory Efficiency:
- Reduces the number of linear layers outside of attention from six to two, reducing activation memory usage significantly.
- Employs a simplified and fused plan that reduces activation memory usage compared to standard Transformers.
- Training and Inference Efficiency:
- Shows up to 1.5x - 15.2x more efficiency in training and inference, respectively, compared to Transformer++.
- Can construct networks over 2x deeper due to reduced activation memory usage.
- Performance:
- Outperforms standard Transformers and popular Transformer variants like Transformer++ in ranking tasks.
- Demonstrates crucial improvements in both conventional sequential settings and industrial-scale streaming settings.
- Stochastic dimension (SL):
- Selects input sequences to keep advanced sparsity and reduce training costs.
- Significantly outperforms existing dimension extrapolation techniques, making it highly effective for large-scale advice systems.
Details of HSTU Architecture
HSTU is utilizes a fewer interesting components:
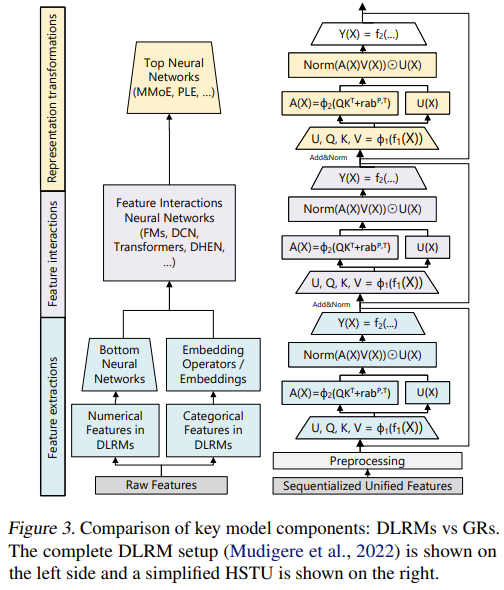 Source: [1]
Source: [1]The HSTU model utilizes an intricate setup of representing categorical features as auxiliary events in a time-series.
This is best illustrated by the following diagram from the first preprint:
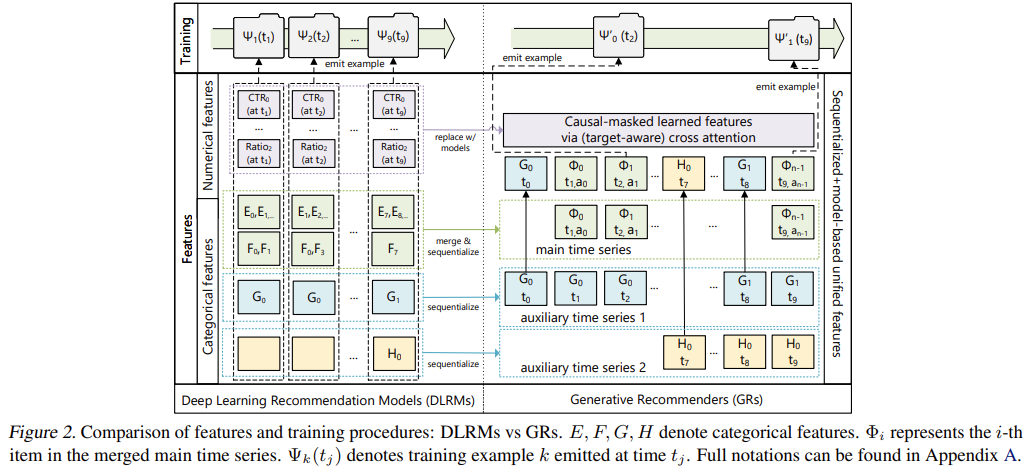 Source: [1]
Source: [1]On the left-hand side is simply a classical Deep Learning Recommender Model, while on the right side is the generative causal setup proposed by Meta AI. It can be seen how categorical features are transformed into auxiliary events which are then incorporated into the main time-series.
HSTU’s Benchmark Results
HSTU was benchmarked on 3 public datasets: MovieLens-1M, MovieLens-20M and Amazon Books.
HSTU outperformed prior strong baselines on the datasets used. Results below:
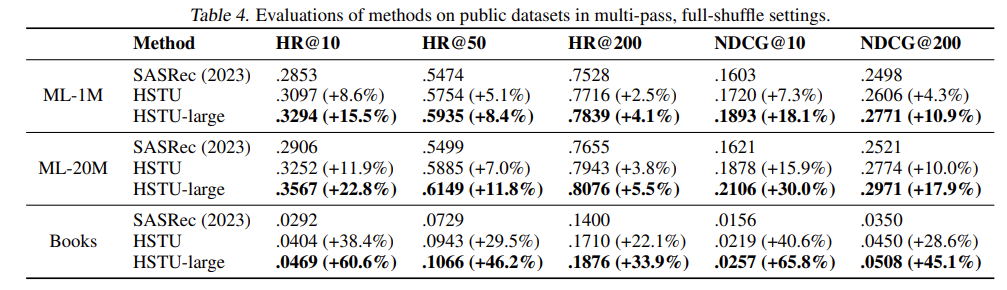 HSTU vs SASRec consequence comparison [1]
HSTU vs SASRec consequence comparison [1]HSTU was able to accomplish crucial improvements over prior state-of-the-art (SASRec) on all metrics on all datasets.
It is worth noting that based on our own experiments at Synerise AI, MovieLens is an atypical dataset that should not be utilized as a benchmark for sequential recommendations due to the underlying data generation process. The temporal ordering of movies rated is very loosely correlated with the order of consumer choices – 1 may rate a movie seen a long time ago. Reviews are frequently done in short bursts, even though the movies were watched by the reviewer sequentially prior to the review or even many years in the past.
BaseModel vs HSTU Performance
To measure BaseModel against HSTU, we replicated the exact data preparation, training, validation, and investigating protocols described in the HSTU paper. The exact same implementations of HitRate and NDCG metrics were utilized for consistency.
For comparison of the models a fewer steps were performed:
- Implementation of the exact data preparation protocol as per HSTU paper
- Implementation of the exact training, validation, and investigating protocol as per HSTU paper
- Sourcing the exact implementations of HitRate and NDCG metrics utilized in HSTU and incorporation into BaseModel
- model training and evaluation (on all 3 datasets)
The full process took 5 hours from scratch to finish. The parameters of BaseModel were default for the Amazon Books dataset, and somewhat modified for MovieLens datasets, to reflect their not-really-sequential structure. The results look as follows:
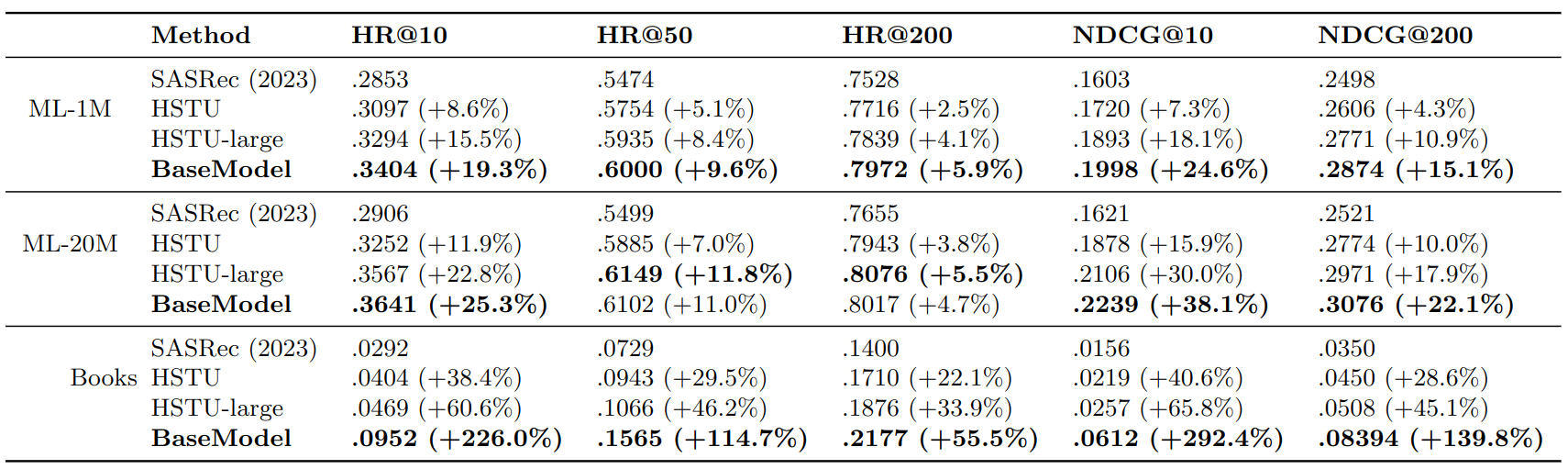 BaseModel vs HSTU and SASRec
BaseModel vs HSTU and SASRecDespite limited optimization of BaseModel’s parameters, the results are remarkably interesting. BaseModel achieved an +55.5% to +292.4% improvement over SASRec’s results on Amazon Books, importantly outperforming HSTU.
On MovieLens-1M, BaseModel had a clear advantage over both SASRec and HSTU, and on MovieLens-20M both BaseModel and HSTU were tied, while SASRec remained far behind.
We have internally confirmed MovieLens is simply a pathologically constructed dataset, and its sequential/temporal structure does not correspond to typical series advice scenarios in another public and private datasets. We hypothesize that both BaseModel and HSTU scope near-perfect achievable scores on MovieLens-20M.
While exact HSTU training and inference times are not reported, the model is based on a modified Transformer architecture. Meta AI’s squad has optimized the architecture importantly allowing training 2-15x faster than Transformer++. Yet, even with those optimizations BaseModel’s training and inference processes are orders of magnitude faster.
Conclusion
The comparison between BaseModel and HSTU reveals crucial differences in their architectural choices and performance. While HSTU represents a notable advancement in generative retrieval recommender systems, BaseModel’s approach demonstrates superior efficiency and effectiveness in sequential advice tasks. In addition, we conclude that usage of MovieLens datasets should be discouraged for sequential recommendations, as the sequential/temporal information contained therein is very noisy.
We are continuously improving our methods to push the boundaries of what behavioral models can achieve, comparisons with alternate approaches are a vital part of our work.
References
[1] Zhai, et al., “Actions talk Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations”, https://arxiv.org/abs/2402.17152








