Temat bezpieczeństwa aplikacji, na całe szczęście, staje się coraz bardziej widoczny i brany pod uwagę. W dużej mierze przyczyniają się do tego kolejne ataki, w których atakujący są coraz bardziej kreatywni. Oczywiście, nie zasługują oni na wdzięczność. Gdyby nie oni to w ogóle nie trzeba byłoby dbać o tego typu zagadnienia. Na uczciwość całego świata nie ma co liczyć. Trzeba więc obrać inny kierunek. A tym kierunkiem jest tworzenie wystarczająco bezpiecznych aplikacji.
Wystarczająco, to znaczy jak? Prawda jest taka, iż nie da się osiągnąć bezpieczeństwa na poziomie 100%. Poza tym, im bardziej bezpieczna aplikacja, tym mniej przyjazna w użyciu. Przynajmniej od strony nieświadomego użytkownika, które wszystkie tego typu zabezpieczenia traktuje jak dodatkową robotę, którą musi wykonać. Należy jednak zabezpieczyć się przed najpopularniejszymi atakami i wyeliminować podstawowe podatności, tak by nie zostać skompromitowanym przez przypadkowego lamusa.
Tego wszystkiego jest tyle, iż nie da się być specjalistą w każdej dziedzinie. Nie w każdej organizacji istnieją osoby, które mają wiedzę na temat bezpieczeństwa. Mimo wszystko, na koniec dnia, liczy się czy aplikacja jest względnie bezpieczna, a nie ile osób i kto nad tym pracował. Pozostaje więc pytanie, czy programiści również powinni być obeznani w tej tematyce? Moim zdaniem jak najbardziej. Nie twierdzę, iż muszą być specjalistami, ale są odpowiedzialni za wszystko, co związane z kodem. A spora część dziur bezpieczeństwa wynika właśnie z błędnych implementacji.
Skąd jednak wiedzieć, kiedy znajomość tematu bezpieczeństwa jest wystarczająca? Okazuje się, iż istnieją różne organizacje, które próbują w tym pomagać. Tworzą bowiem różnego rodzaju standardy i dobre praktyki. Jedną z popularniejszych, o której prawdopodobnie słyszeliście, jest OWASP. Być może macie w swoich organizacjach inne wytyczne, ale jestem prawie przekonany, iż bazują one na rzeczach wypracowanych przez nich.
Dlaczego warto opierać się o tego rodzaju materiały? Bazują one na statystyce. Najczęstsze błędy oraz najskuteczniejsze ataki – jak się przed nimi zabezpieczyć? W kontekście API, czyli codziennej pracy programisty PHP, pomocne mogą okazać się wytyczne zawarte w API Security Top 10 2019. I to na nich się skupię w tym materiale. Postaram się jak najbardziej dopasować je do realiów PHP, ale prawda jest taka iż są to reguły uniwersalne dla każdej technologii, choć oczywiście niektóre podatności są bardziej widoczne w konkretnych ekosystemach.
10 zasad, które wcale nie są takie skomplikowane. Problem istnieje w świadomości. Ciężko dbać o coś, o czym nie ma się pojęcia. Nic nie szkodzi. Po przeczytaniu tego wpisu, powinniście uzyskać podstawową wiedzę w tym zakresie. Dodatkowo, na samym końcu, wrzucam linki do innych ciekawych materiałów na ten temat. I oczywiście, warto zajrzeć do samego źródła.
Autoryzacja na poziomie zasobu
Problem: Broken Object Level Authorization
To, iż użytkownik posiada uprawnienie do konkretnego endpointu, nie świadczy o tym, iż API jest adekwatnie zabezpieczone. Normalne są sytuacje, w których użytkownik powinien mieć dostęp tylko do niektórych obiektów. Chociażby tych, które dotyczą jego albo jest on ich właścicielem. Uprawnienie może wynikać też z logiki samej aplikacji.
Łatwo unaocznić sytuację, w której użytkownik odczytuje dane należące do kogo innego lub co czasem gorsze, może je zmieniać. Wyobraźcie sobie dość standardową akcję w aplikacji, pozwalającą na zmianę danych pracownika, w tym jego adresu e-mail. Użytkownik ma dostęp do danego endpointu, bo może zmieniać swoje dane. W prosty sposób może jednak podmienić identyfikator i zmodyfikować dane innego użytkownika. A to samo w sobie jest sporym zagrożeniem. Dostanie się on do danych wrażliwych, których nie powinien widzieć. Bardziej zaawansowanym atakiem, który można sobie wyobrazić to zmiana adresu e-mail na swój, w celu późniejszego odzyskania hasła albo otrzymywania wiadomości e-mail dedykowanych innemu pracownikowi.
Rozwiązanie: Broken Object Level Authorization
Sprawdzenie na poziomie samego obiektu, czy użytkownik ma do niego dostęp powinno być powszechną praktyką. W końcu rzadko istnieją obiekty, które mogą być modyfikowane i odczytywane przez wszystkich (choć takie też się zdarzają). Wystarczającym zabezpieczeniem okaże się najzwyczajniej sprawdzenie wynikające z logiki aplikacji, czy użytkownik posiada dostęp do zasobu. Dla przykładu można założyć, iż administrator może edytować wszystkich pracowników, a pracownik może edytować tylko swoje dane, czyli te których jest właścicielem. Tego rodzaju logikę prezentuję w poniższym kodzie. Oczywiście dla czytelności wrzuciłem to w kontrolerze, ale normalnie taką logikę często powinno się wyciągnąć w inne miejsce.
Dodatkowym zabezpieczeniem może okazać się używanie identyfikatorów, które nie są przewidywalne np. UUID. przez cały czas nie gwarantuje to bezpieczeństwa, ale je zwiększa, jako iż dużo trudniej jest odgadnąć identyfikator innego zasobu. Nie tak jak w przypadku numerycznego autoinkrementowanego identyfikatora.
Uwierzytelnienie użytkownika
Problem: Broken User Authentication
Dużo można by tu wymieniać. Sporo jest opcji błędnego zaimplementowania mechanizmu uwierzytelniającego. Co na przykład? Największy problem to jego brak, czyli publicznie dostępne API zawierające wrażliwe dane. Ale choćby kiedy jest, to może być zepsute i należy zwrócić uwagę na:
- dane dostępowe przesyłane w adresie URL,
- brak wymaganej długości haseł,
- hasła przechowywane w niezaszyfrowanej formie,
- brak zabezpieczenia przed atakiem typu bruteforce,
- stałe tokeny dostępowe bez czasowego ograniczenia,
- niepodpisany JWT,
- błędnie zaimplementowany 2FA,
- i wiele innych tego typu…
Rozwiązanie: Broken User Authentication
W zależności od problemu, rozwiązanie może być różne. Warto pamiętać przede wszystkim, iż jest to bardzo istotny aspekt bezpieczeństwa. Trzeba mu poświęcić sporo uwagi oraz na bieżąco kontrolować jego stan i dostosowywać do aktualnych standardów.
Kilka rozwiązań, które na pewno usprawnią ten proces. Przede wszystkimi, większość frameworków dostarcza potrzebne mechanizmy, które można dostosować do własnych potrzeb. Nie ma sensu implementować wszystkiego od zera. A już na pewno, nie warto pisać własnych mechanizmów kryptograficznych, ale lepiej wykorzystać gotowe algorytmy. Nie ma czegoś takiego jak wewnętrzne API, którego nie trzeba zabezpieczać. jeżeli są tam przechowywane jakiekolwiek wrażliwe dane to należy to zrobić.
Hasła to temat wałkowany już tyle razy, iż aż wstyd kolejny raz o tym wspominać. Oczywiście trzeba przechowywać je w postaci zaszyfrowanej. Mechanizmy walidacyjne powinny wymuszać odpowiedni stopień skomplikowania. Hasła nie powinny być przesyłane w jawnej metodzie GET. jeżeli hasło jest generowane to powinno być zmienione przy pierwszym logowaniu.
API najczęściej zabezpieczane jest dzięki tokenów przesyłanych w nagłówkach. Oprócz tego, można jeszcze spotkać można uwierzytelnienie typu Basic Auth. Jest nieco mniej bezpieczne, ale proste w implementacji. Tokeny powinny mieć swoją ważność i być odpowiednio zaszyfrowane. Najczęściej korzysta się z JWT. Należy zadbać, aby był podpisany w odpowiedni sposób. Niepodpisany JWT to żadne zabezpieczenie.
Logowanie powinno być limitowane. Brak takiego mechanizmu spowoduje, iż atakujący może atakiem typu bruteforce próbować odgadnąć dane uwierzytelniające. To samo w przypadku uwierzytelnienia wieloskładnikowego (2FA / MFA). jeżeli nie ma ograniczonych liczby prób wpisania kodu wysyłanego wiadomością SMS, czy e-mail to kilku-cyfrowy kod to kwestia maksymalnie kilku minut aby go znaleźć bruteforcem.
Poniżej konsolowy skrypt napisany w 5 minut pozwalający uskutecznić tego typu operację. Oczywiście roboczy i pewnie wymagałby optymalizacji, ale chciałem pokazać, iż choćby tak prymitywny skrypt to kwestia maksymalnie kilku minut, aby spróbować maksymalnie 10000 kombinacji. A uwierzcie, iż tego typu gotowe narzędzia są znacznie skuteczniejsze.
Ekspozycja danych
Problem: Excessive Data Exposure
Problemem API REST-owych zawsze była zbyt duża ilość danych zwracana w odpowiedzi. Łatwo wyobrazić sobie przykład, w którym potrzebna jest tylko nazwa danego zasobu, ale przy żądaniu zwracany jest cały obiekt. O ile ma to konsekwencje tylko wydajnościowe to w niektórych przypadkach może nie stanowić problemu. Gorzej, jeżeli pytający w ogóle nie powinien mieć dostępu do tych danych. Filtrowanie danych na widokach nie rozwiązuje problemu. W prosty sposób można podejrzeć odpowiedź samego API.
Z czego wynika problem? Łatwiej jest zserializować cały obiekt. Reużywalność – tworzenie kilku endpointów dla tego samego zasobu jest bardziej czasochłonne i nie raz trudniejsze w utrzymaniu. No i problem samego nazewnictwa – jak nazywać endpointy które dotyczą tego samego zasobu, ale zwracają różne dane.
Rozwiązanie: Excessive Data Exposure
Widzę tutaj dwa podejścia. Osobne endpointy dla różnych aktorów, tak by otrzymywali tylko odpowiednie dla siebie dane lub jeden endpoint zwracający inną odpowiedź w zależności od aktora. Drugi pozwala zachować pewną reużywalność, ale wcale nie jest prostszy w utrzymaniu. Samo dokumentowanie endpointu, który może zwrócić odpowiedź o różnym schemacie jest trudniejsze i bywa nieczytelne. W praktyce jednak to często spotykane rozwiązanie i warto je rozważyć.
Pierwsza opcja będzie lepsza dla mniej REST-owych endpointów. One też przecież się zdarzają, czyli różnego rodzaju dedykowane tabele czy raporty. Tak jak mówię, zostaje problem nazewnictwa. Można zrobić na przykład przedrostek zależny od roli aktora np. /admin/employees i /manager/employees, ale nie jest to najlepsze i stabilne rozwiązanie. Poza tym w ramach jednej roli mogą też istnieć dwie listy jednego zasobu. Taki problem może też sygnalizować, iż warto pochylić się nad jednym z zagadnień DDD, czyli kontekstami ograniczonymi. Skoro coś serwuje inne dane, to być może powinny to być osobne obiekty i osobne endpointy. W jednym kontekście użytkownik może być pracownikiem, a w innym nauczycielem i może niekoniecznie powinny to być te same końcówki.
Szczególny przypadek, w którym trzeba o to zadbać to nadmiarowe dane wrażliwe. Najłatwiej mieć obiekty reprezentujące rezultat konkretnej odpowiedzi. Wtedy nie ma miejsca na pomyłkę tego typu. Nie ma sensu też zwracać nadmiarowych danych, bo może się przydadzą. Odpowiedź powinna być tak okrojona, jak tylko może być. Nie wyklucza to reużywalności – nie chodzi o to żeby tworzyć pod każdą akcję osobny endpoint, chociaż oczywiście będzie ich więcej, niż w klasycznym podejściu REST, gdzie każdy zasób ma tylko kilka podstawowych metod. Tam gdzie dane są nadmiarowe, ale publiczne spokojnie można reużywać standardowych endpointów.
Zużycie zasobów
Problem: Lack of Resources & Rate Limiting
Wysycenie zasobów to rzecz o którą wcale nie tak trudno. Trzeba więc zadbać o to, by nasze API było jak najbardziej odporne na tego typu scenariusze. Niektóre aspekty są tu kwestią implementacji i kodu, a inne dotyczą hostowania aplikacji.
Pod atakami DoS padały największe technologiczne firmy, więc prawdopodobnie nie ma szans zabezpieczyć się przed wszystkim, ale przynajmniej podstawowe mechanizmy odstraszające i utrudniające. Na co trzeba zwrócić uwagę? Szczególnie wysycenie pamięci, zbyt długi czas wykonywania skryptu, zbyt duży payload lub wgrywany plik.
Rozwiązanie: Lack of Resources & Rate Limiting
Warto mieć adekwatnie ustawione limity w zgodzie ze sprzętem na którym pracuje aplikacja. Należy zainteresować się takimi ustawieniami jak: memory_limit, max_execution_time, post_max_size, upload_max_filesize.
Kolejny istotny temat to odpowiednie limitowanie liczby żądań. Można to zrobić dla konkretnego tokenu, ale dodatkowo trzeba zabezpieczyć też samo uwierzytelnianie, tak by ustrzec się przed atakiem bruteforce. Dodatkowo należy monitorować, jako iż ciężko oszacować potrzebne zasoby i limitowanie na czuja. Przy tych wszystkich ograniczeniach nie można spowodować błędów w działaniu aplikacji. Ma to być działanie prewencyjne. Wiele z tych rzeczy można zrobić na poziomie infrastruktury, ale w części aplikacyjnej także. Na przykład warto sprawdzić rate limiter od Symfony, który dostarcza gotowy mechanizm pozwalający ograniczyć liczbę żądań.
Autoryzacja na poziomie żądania
Problem: Broken Function Level Authorization
Wydawać by się mogło, iż tego rodzaju błędy nie występują – a jednak. Na początku wszystko wydaje się klarowne. Projekt startuje, każdy wie jak wygląda system uprawnień. W miarę rozwoju aplikacji dołączają nowe osoby albo stare nie pamiętają jak to już działało. W pewnym momencie okazuje się, ze istnieje kilka końcówek, które dostępne są dla użytkowników z nieodpowiednią rolą albo, co gorsza, dla wszystkich uwierzytelnionego. Szczególnym przypadkiem jest sytuacja, w istnieje dostęp do jednej z metod np. DELETE, a pozostałe są adekwatnie zabezpieczone.
Rozwiązanie: Broken Function Level Authorization
Przede wszystkim system uprawnień powinien być prosty w założeniach. Nie ma sensu komplikować go tak, by jego zrozumienie, a później użycie, było wyzwaniem. Oprócz tego, należałoby zastosować regułę maksymalnego ograniczenia. jeżeli nie skonfigurowano uprawnień dla jakiegoś endpointu to nikt nie powinien móc go użyć. Nie może być tak, iż domyślnie dostęp mają wszyscy. Trzeba to odwrócić i kiedy dodawana jest nowa akcja to jeszcze nikt nie ma do niej uprawnień, więc siłą rzeczy nikt jej nie użyje. Dla poniższej mapy uprawnień, w momencie kiedy dojdzie możliwość usuwania pracownika, to jeszcze nikt nie będzie miał tego uprawnienia. Dopóki nie zostanie dodany wpis employees.delete.
Dobrze też mieć przemyślane w jaki sposób realizowane są uprawnienia. Może wymagać to będzie sensownego pogrupowania np. poprzez role. Zdarza się też wprowadzenie hierarchii i dziedziczenia ról albo możliwość posiadania więcej, niż jednej. Wszystkie te przypadki to miejsca potencjalnych błędów.
Co z tego, iż endpointy mają odpowiednio nadane uprawnienia, skoro niewłaściwi użytkownicy posiadają owe uprawnienia. Problem ten występuje najczęściej przy dużych aplikacjach, gdzie uprawnień i możliwych akcji do wykonania jest tak dużo, iż ciężko to kontrolować. Mimo wszystko, warto tę funkcjonalność testować.
Wydawać by się mogło, iż problem ten wcale nie jest taki poważny. Dotyczy przecież uwierzytelnionego uczestnika. OK, to wyobraźcie sobie, iż uwierzytelniliście się w banku jako klient, a otrzymaliście dostęp do pieniędzy innego klienta albo raportów finansowych dla dyrektora.
Walidacja schematu
Problem: Mass Assignment
Payload przesyłany przez użytkownika powinien sprowadzać się tylko do danych, które są potrzebne do wykonania operacji. Niestety czasem bazuje się na całych obiektach, które powstają bezpośrednio z przesyłanych danych. Oczywiście programista zakłada, iż nikt w tym wypadku nie prześle szerszego kontekstu, aniżeli narzuca kontrakt. Ale takie założenie okazuje się niewłaściwe. Jakie mogą być konsekwencje? Zależy, co niepożądanego da się ustawić, wykorzystując tego rodzaju słabość. Przykładami mogą być przypisanie sobie roli administratora albo nadanie rabatu przy zakupach.
W PHP problem ten nie jest aż tak widoczny jak chociażby w JS, gdzie JSON staje się bezpośrednio obiektem. Nie oznacza to jednak, iż można go całkowicie pominąć. W PHP można polegać na serializacji i wówczas da się wyobrazić sobie sytuację, kiedy tego rodzaju atak uda się przeprowadzić. Innym przypadkiem, może być, co interesujące nazywający się tak samo, Mass Assigment w Laravel Eloquent.
Klasa User pozwala na masową edycję obiektu. W jednym z miejsc istnieje potrzeba edycji własnych imienia, nazwiska i adresu e-mail przez zwykłego użytkownika. W innym, administrator może zmienić e-mail i rolę.
Tak prezentuje się oczekiwany payload dla żądania pozwalającego na edycję własnych danych.
W kodzie aplikacji $payload to dane w postaci array, który wcześniej w tle framework zserializował.
I w ten sposób atakujący może przesłać payload z dodatkową wartością roli otrzymując tym samym uprawnienia administratora.
Rozwiązanie: Mass Assignment
Zabezpieczenie przed tego rodzaju atakiem nie jest takie trudne. Zawsze należy walidować przychodzące dane z zewnątrz. Nie inaczej w tym przypadku. Sprawdzenie schematu przesyłanego ładunku to podstawa. To jednak nie wszystko, bo nie można wymusić braku addytywnych pól. Inaczej… można, ale raczej się tego nie stosuje. Po prostu bierze się pod uwagę istotne pola i ich wartości, a nieistotne pomija. Dla tego przykładu poniższy payload powinien być w porządku.
Przypisanie zawsze powinno być jawne. jeżeli serializacja to do konkretnego obiektu DTO posiadającego tylko te pola które są wymagane. Rozwiązaniem problemu z przykładu byłoby na przykład jawne przypisanie wartości. Wówczas rola w tej operacji nie jest brana pod uwagę.
Ogólne bezpieczeństwo
Problem: Security Misconfiguration
To spory worek z problemami. Tak naprawdę zakwalifikować można tutaj wszystko. W praktyce, chodzi o wszystkie te sytuacje, w których mechanizm nie działa tak jak powinien z uwagi na nieodpowiednią konfigurację. Spora część tych problemów to kwestie serwerowe. Czasem więc jako programiści nie musicie się nimi przejmować. Przykłady problemów istotnych z perspektywy programisty:
- nieaktualizowane biblioteki zewnętrzne,
- niezabezpieczone pliki i katalogi,
- brak odpowiedniego zarządzania nagłówkami HTTP,
- brak lub zła konfiguracja polityki CORS,
- zbyt ekspozycyjne treści błędów,
- błędnie wypełnione pliki konfiguracyjne.
Rozwiązanie: Security Misconfiguration
Niełatwo o konkretne metody radzenia sobie z tymi kłopotami. Przede wszystkim automatyzacja. W przeciwieństwie do komputerów, człowiek nie jest nieomylny. Wszystkie konfiguracje można zaprząc do swojego flow CI/CD. Regularne aktualizowanie paczek Composera oraz usuwanie kodu potencjalnie niebezpiecznego i niewspieranego. Odpowiednie zarządzanie nagłówkami i implementacja CORS. (jej wyłączenie wcale nie jest rozwiązaniem). No i wreszcie, logowanie treści błędów, ale nie zwracanie ich w odpowiedzi API.
Zabezpieczenie przed wstrzyknięciami
Problem: Injection
Chyba jeden z popularniejszych ataków. Nie chodzi tylko o sławne SQL Injection, które mam nadzieję, iż w dzisiejszych czasach już nie występuje… Ale istnieją jeszcze inne wstrzyknięcia np. XML Injection, Command Injection, File Injection, czy NoSQL Injection. Na czym polega wstrzyknięcie? Chodzi o to, żeby wstrzyknąć kod, który wykona się niejako w bonusie podczas wykonywania skryptu.
W poniższym przykładzie błędny kod do liczenia plików w katalogu. Użytkownik ma podać nazwę katalogu i otrzymuje liczbę plików, które się w nim znajdują.
Zamiast nazwy katalogu można podać w parametrze dowolną złośliwą metodę: https://koddlo.pl?documents | count=cat /etc/passwd; ls.
Rozwiązanie: Injection
Jak zwykle walidacja i sanityzacja danych. Czas zadbać o swoje podwórko i nie wpuszczać wszystkiego, co tylko się da. Dodatkowo, nie powinno się używać metod exec i innych podobnych tego typu operujących bezpośrednio na systemie operacyjnym. Jest to ostateczność, bo PHP ma wiele wbudowanych i co ważne bezpiecznych metod, którymi można obsłużyć tego typu funkcjonalności. jeżeli już faktycznie nie ma innego wyjścia, to taki kod trzeba zabezpieczyć w odpowiedni sposób.
Przykład z problemu może być rozwiązany poprzez użycie dedykowanej funkcji scandir jak poniżej. Oczywiście sam parametr directory też należałoby zabezpieczyć, ale dla uproszczenia przekazuję go bezpośrednio.
Przed wszystkimi wstrzyknięciami można bronić się w ten sam sposób. Wcale nie ma tego tak dużo, a w zależności od tego, co akurat jest używane to należy zwrócić na to uwagę. Podstawą jest zabezpieczenie przed SQL Injection, które jest proste, ale niedopatrzenie może być opłakane w skutkach. Inne wstrzyknięcia są bardziej specyficzne i wymagają konkretnych funkcjonalności. jeżeli akurat są one częścią aplikacji to wówczas powinny być wzięte pod uwagę.
Zarządzanie środowiskami
Problem: Improper Assets Management
Im większe API, tym trudniej nad nim zapanować. Problem z zarządzeniem środowiskami może objawić się przynajmniej w dwóch obliczach.
Mogą istnieć martwe endpointy, czyli takie które nie są używane lub utrzymywane. Z jakich powodów? Przychodzą mi na myśl dwa bardzo realne scenariusze:
- Funkcjonalność została usunięta, ale endpoint nie został skasowany.
- Została wydana nowa wersja endpointu, a stary nie został skasowany. Pierwotnie miał istnieć tymczasowo dopóki klienci nie przerzucą się na nową wersję. A wiadomo jak to bywa z tymczasowymi rozwiązaniami – endpoint istnieje nadal, mimo tego, iż nikt go już nie utrzymuje.
Drugie, kiedy istnieją inne środowiska poza produkcyjnymi (dev, test, stagging), które nie są odpowiednio skonfigurowane. Być może są niewłaściwie zabezpieczone albo istnieją jakieś odstępstwa na potrzeby łatwiejszego wytwarzania oprogramowania. Problem staje się szczególnie istotny, gdy owe środowiska korzystają z danych produkcyjnych. Kompromitacja owych środowisk może prowadzić do łatwiejszej kompromitacji środowiska produkcyjnego.
Jak mogłyby wyglądać potencjalne dziury w zabezpieczeniach:
- nowa wersja endpointu rozwiązuje znaczący problem, ale przez cały czas istnieje stara wersja, której atakujący może użyć,
- wszystkie środowiska korzystają z tego samego serwera uwierzytelniającego, więc sekrety ze środowisk deweloperskich i testowych działają też dla produkcyjnego.
Rozwiązanie: Improper Assets Management
Całkowicie odseparowanie środowisk. Nie zawsze jest to możliwe, bo chociażby nie istnieją sandboxy dla integracji. Na ile się da, na tyle wypada się na tym skupić. a kiedy się nie da to chociaż działać na innych danych uwierzytelniających, może z jakimiś ograniczeniami albo używać z mocków, a nie na realnej integracji. Ponadto, nie przystoi używać danych produkcyjnych na innych środowiskach, które mogą być obszarem ataku. Aktualizacja do najświeższych wersji wszystkich środowisk to obowiązek.
Inny obszar do poprawy to aktualność API. Usuwanie kodu bywa niejednokrotnie trudniejsze, niż jego dodawanie. Czasem trudno to zrobić, tak by niczego nie zepsuć po drodze. W związku z tym, programiści idą na łatwiznę i zostawiają nieużywane funkcjonalności: „A może jeszcze kiedyś się przydadzą”. Ale więcej kodu to trudniejsze utrzymanie, a poza tym właśnie kwestia bezpieczeństwa.
Istotną kwestią jest tutaj dokumentacja API. W dzisiejszych czasach, dosyć łatwo można ją generować, chociażby z pomocą Open API. Bez niej nikt nie jest w stanie ogarniać wszystkich endpointów. To, na czym się też trzeba skupić to jej aktualizacja – nieaktualna dokumentacja bywa gorsza, niż jej brak. W związku z tym, przydałoby się dbać o jej aktualność i regularnie robić jej przegląd, tak by pozbywać się już nieużywanych endpointów i ich starych wersji. Wersjonowanie API to kolejny temat – nie zawsze można pozwolić sobie na całkowitą zmianę konktraktu. Trzeba dać czas na dostosowanie się, ale ważne żeby był to rozsądnej długości okres, a tuż po nim należy się pozbyć zaszłości.
Zakładając, iż wersja v1 endpointu do pobierania informacji o pracowniku zwracała zbyt dużo danych, których potrzebował tylko administrator. Niektóre z tych danych nie powinny być publikowane dla innych typów użytkowników. Niestety nie da się z dnia na dzień zmienić odpowiedzi, bo niektóre aplikacje mogą przestać działać, gdyż opierają się o te parametry – mimo, iż nie powinny. Zmiana zakłada stworzenie kolejnej końcówki z nową wersją v2. Jeszcze przez chwilę v1 będzie utrzymywany. Warto w kodzie oznaczyć go jako depracated i zawrzeć informację, kiedy można go usunąć. Dodatkowo ma sens oznaczenie go także w dokumentacji jako depracted. Dla Swaggera jest to po prostu flaga depracted: true i prezentuje się jak na obrazku poniżej. Przy przeglądzie dokumentacji od razu widać, iż nie powinien być używany.
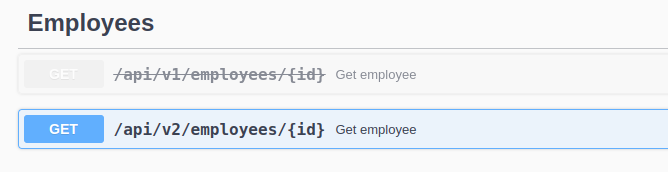 Swagger documentation – depracated flag
Swagger documentation – depracated flagLogowanie i monitorowanie zdarzeń
Problem: Insufficient Logging & Monitoring
Monitorowanie to istotny aspekt każdej aplikacji. A monitorowanie nie istnieje bez odpowiedniego logowania. Niektóre branże regulowane są choćby prawnie w tym zakresie. Niezależnie od tego, dla adekwatnego utrzymywania aplikacji trzeba zaopatrzyć się w odpowiednie narzędzia. Jakie problemy mogą tutaj wystąpić? Brak odpowiedniego formatu, nieczytelne albo wręcz nic nie mówiące logi, brak logowania dla kluczowych zdarzeń, niezabezpieczone logi i wycieki danych.
Rozwiązanie: Insufficient Logging & Monitoring
Przede wszystkim, wypada logować i monitorować. Niektórzy podchodzą do tematu w ten sposób, iż więcej znaczy lepiej. Coś w tym jest, ale nie zawsze. Logowanie dla logowania – nie ma sensu. Logi muszą być używalne i czytelne. Czasem wykorzystuje się do tego kilka narzędzi, ale warto mieć jedno źródło prawdy.
Do monitorowania i logowania istnieje sporo gotowego oprogramowania, dlatego rzadko jest sens tworzenia własnych. Należy też pamiętać o wycinaniu wrażliwych danych, szczególnie jeżeli korzysta się z zewnętrznego dostawcy. Tutaj wchodzą kwestie prawne. Ale choćby kiedy logujemy do pliku na serwerze, czy czegokolwiek… przez cały czas nie jest to najlepszy sposób, aby wrzucać tam wszystko. Słyszałem o sytuacji (nie pytajcie), gdzie na produkcji logowane było hasło do bazy danych. Brzmi abstrakcyjnie, ale kiedy wszystko działa, nikt nie zagląda w te logi, a automaty logują wszystko jak popadnie, kiedy nie ma odpowiedniej polityki wycinania wrażliwych danych. Można się zdziwić, co uda się tam znaleźć.
Oczywiście logi muszą być identyfikowalne, ale można to zrobić opierając się na identyfikatorach. Co więcej, dostęp do monitoringu powinien być możliwie jak najlepiej zabezpieczony. To centralne miejsce, w którym znajduje się bardzo dużo informacji o działaniu aplikacji.
Podsumowanie OWASP TOP10 API
Myślę, iż do wytwarzania systemu powinno się podchodzić z należytą jakością. Jednym z aspektów jakości jest właśnie bezpieczeństwo. Jak wspomniałem wcześniej, nie twierdzę, iż trzeba tutaj robić doktorat, ale szczerze – wstyd nie znać podstaw. Błędy się zdarzają. Wycieki i kompromitacje się zdarzają. Ale naprawdę, nie można dać się oszukać w najprostszy sposób.
OWASP to chyba nalpopularniejszy zbiór reguł bezpieczeństwa. Istnieją też inne, ale w zasadzie muszą one być podobne. Niezależnie od wyboru – podstawowe podatności i możliwości przeciwdziałania to obowiązek. To zagadnienia całkiem szerokie, ale starałem się je pokazać w możliwie jak najbardziej przystępny sposób. Od siebie dodam dwa linki, które warto sprawdzić: apisecurity.io (teoria) i kontra (praktyka).
Życzę Wam bezpiecznego API!
Wpis Bezpieczne API w PHP – OWASP Top10 API Security pojawił się pierwszy raz pod Koddlo.