Praca programisty to nie tylko programowanie. To również zorganizowana praca zespołowa, która (podobnie jak u mrówek czy pszczół) polega na tworzeniu mniejszych elementów, które w jakiś sposób trzeba złożyć w większą całość. Jedną z metodyk organizacji pracy na projekcie jest GitFlow, czyli bardzo popularny schemat „branchowania”, o którym dziś coś niecoś opowiem
Kiedy wchodzimy do nowego projektu…
Podczas wdrażania się nowego projektu, zawsze pada pytanie: jak robimy z branchami? Wtedy pojawia się on, leader projektu, cały na biało i wyjaśnia, iż ta funkcja jest na tym branchu, a ta na tym, a ten branch ma w sobie dodatkowo dwie inne funkcje, w tym jedną, która jest rozwijana dalej na całkiem osobnym branchu. Ba, została całkowicie zrefaktoryzowana, o czym branch zależny nic nie wie. Ktoś inny naprawił wyświetlanie przycisku „Dodaj do koszyka” na branchu z poprawkami w panelu administracyjnym. A jeszcze ktoś jedną funkcjonalność rozbił na kilka branchów, bo na jednym jest część admina, na drugim logika kupowania, a na trzecim… testy.
Im więcej developerów pracuje przy projekcie, tym więcej zależności między sobą, które trzeba spamiętać. Problemy, które potencjalnie mogą się pojawić:
- Developer, który rozbił funkcjonalność na kilka branchów mógł zostać zwolniony dwa miesiące temu i właśnie minął jego ostatni dzień w firmie. Niestety, jego wiedza na temat tego, co gdzie i jak, zostaje „zgubiona”.
- Gość od refaktoryzacji przeorał kod w taki sposób, iż nie ma już nic wspólnego z tym, co domergował sobie drugi chłopak. Czyli pewną pracę trzeba zrobić drugi raz.
- Fix przycisku „Dodaj do koszyka” staje się fixem numer jeden, musi zostać zmergowany do mastera w trybie pilnym. Trzeba szukać tego commita pośród wielu na branchu. O zgrozo, o ile na jednym commicie zostało zrobione dużo rzeczy hurtowo.
Ze strony Project Managera, wszystko wygląda prosto: mamy trzy funkcjonalności od siebie niezależne, oprócz tego jedną poprawkę. Niestety, zespół developerski nie jest w stanie przez dłuższy czas tego wypuścić, bo: „ktoś coś zmienił”, „ktoś zrobił mi konflikty”, „mam to na innym branchu z inną rzeczą”. Próba zaplanowania jakiegokolwiek releasu zaczyna graniczyć z cudem.
Posługujmy się jednym językiem
Powyższe problemy, potencjalnie, mogą mieć podłoże w braku jakiegokolwiek spójnego języka na poziomie Gita. I nie, nie chodzi tu tylko o ładne nazywanie branchów . Gdybyśmy rozstrzygnęli, iż poprawki wrzucamy na osobne branche, a jedną spójną funkcjonalność trzymamy na jednym branchu, to połowa tych problemów by zniknęła.
Na szczęście, w historii znaleźli się ludzie, którzy również napotkali podobne problemy. Co więcej, zbudowali oni spójny koncept, który stanowczo pomaga w organizacji pracy developerów – GitFlow.
GitFlow – doświadczenie innych na jednym rysunku
Poniżej znajduje się obrazek wyjaśniający wszystko w kontekście GitFlow. Pod obrazkiem znajdziecie dosyć szczegółowy opis
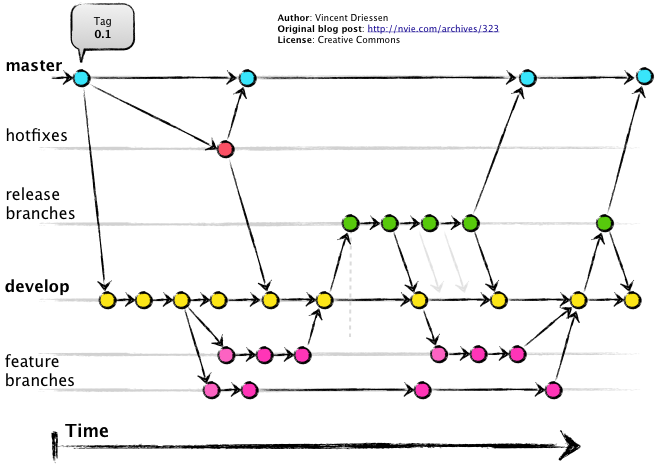 Czytając obrazek, zwróćcie uwagę na kierunki strzałek. Każda z nich ma swoje unikalne (ważne!) znaczenie.
Czytając obrazek, zwróćcie uwagę na kierunki strzałek. Każda z nich ma swoje unikalne (ważne!) znaczenie.Zasady panujące w GitFlow
Podstawą podejścia GitFlow jest utrzymywanie dwóch branchów – głównego (master/main) oraz developerskiego (najczęściej nazywanego develop). Ten pierwszy powinien nam być doskonale znany jako branch produkcyjny, który powinien być odzwierciedleniem aplikacji działającej na produkcji. o ile mamy coś na masterze, to znaczy, iż powinno jak najszybciej wejść na środowisko produkcyjne. Drugi branch – develop – jest branchem, który posiada funkcjonalności, nad którymi w tej chwili pracujemy, a które chcemy, aby zostały wydane w najbliższym czasie. Obydwa te branche (jako jedyne) będą istniały w sposób ciągły, przez cały proces developmentu.
Kiedy rozpoczynamy pracę nad funkcjonalnością (nową, bądź rozszerzeniem już istniejących rzeczy), to znak, iż należy utworzyć feature branch z developa. Oznacza to, iż nasz branch funkcjonalnościowy będzie potencjalnie posiadał wszystkie rzeczy, które jeszcze nie weszły na mastera. W momencie, kiedy stwierdzamy, iż nasza funkcjonalność jest gotowa, przechodzi proces Code Review i zostaje zmergowana z powrotem do developa. o ile okaże się, iż coś jeszcze trzeba tam dorobić, to tworzymy nowego feature brancha i dokodowywujemy resztę. Następnie z powrotem mergujemy to do developa i tak w kółko.
Kiedy zakodowaliśmy i przetestowaliśmy wszystkie funkcjonalności, następuje pora na utworzenie brancha releasowego. Bazą tego brancha będzie develop. W momencie, kiedy tworzymy release branch, następuje tzw. „uwolnienie developa”, czyli moment, w którym możemy zacząć pracować nad nowym zestawem funkcjonalności. Ważne jest to, abyśmy nie mergowali developa do brancha z releasem, ponieważ potencjalnie możemy wrzucić coś zupełnie niegotowego. o ile chcemy, aby coś zostało zawarte w branchu releasowym, to powinniśmy commitować bezpośrednio do niego. Pamiętajmy, iż brancha releasowego możemy mergować tzw. „z powrotem” do developa w każdej chwili. Bo nowo powstające funkcjonalności mogą potrzebować tego, co zostało naprawione na branchu releasowym.
Następnym etapem developerskim jest merge(1) brancha releasowego do brancha głównego. W tym samym momencie mergujemy release z powrotem do developa, aby upewnić się, iż tam wszystko jest najbardziej aktualne. W tym momencie kończy się życie brancha releasowego. o ile mamy taką potrzebę, to możemy go usunąć.
Z jednej strony, wydaliśmy nasze funkcjonalności i jest git. Z drugiej strony, istnieje jednak nieustanna potrzeba wrzucania czegoś na produkcję z dużym priorytetem, poza standardowym procesem developerskim (bo np. coś nie działa). Aby sprostać tej potrzebie, tworzymy tzw. branch hotfixowy z mastera. Naprawiamy, co mamy naprawić, przechodzimy proces Code Review, a następnie mergujemy naszego hotfixa do mastera (bo tam chcemy, aby działało) oraz do developa (bo tam ma być zawsze najbardziej aktualne). Pamiętajmy, iż to flow dotyczy produkcji. o ile znaleźliśmy błąd na developie, a na masterze wszystko działa, to wtedy flow hotfixowe (master) przełącza się na flow developerskie (develop).
Standardy nazewnictwa branchów
Najgorszą sytuacją, jaka może wydarzyć się w pracy z GitFlow, jest przypadkowe zmergowanie developa do mastera. Dzieje się tak najczęściej przez merge do mastera brancha, który wydawał nam się hotfixem. Aby zapobiec tego typu sytuacjom, zwykło się stosować pewne konwencje nazewnictwa branchów:
- hotfix/name-of-thing – prefix służący rozróżnieniu branchów dla rzeczy, które mogą wejść do mastera w dowolnej chwili
- feature/name-of-thing – prefix służący rozróżnieniu branchów dla rzeczy, które muszą przejść pełen proces developerski
- release/20230528 – prefix służący rozróżnieniu branchów releasowych. Dodatkowo, po prefixie zwykło się umieszczać datę utworzenia brancha, aby można było łatwo zlokalizować najnowszy, niewypuszczony release. Ze względu na możliwość niedomknięcia scope releasu, nie powinniśmy tutaj zastosować numeru wersji aplikacji, bo ta może zmienić się po utworzeniu brancha releasowego.
Dodatkowo, o ile korzystacie z jakiegokolwiek systemu ticketowego, pomocne może okazać się umieszczenie numeru ticketu w nazwie brancha. Można wtedy łatwo znaleźć odpowiedni branch, dzięki polecenia grep.
Problem, na który musimy uważać
GitFlow nie jest narzędziem doskonałym. Jest to wzorzec, który ma swój zestaw standardowych problemów, które dobrze jest poznać, zanim podejmiemy decyzję co do wykorzystania go w projekcie.
Pierwszym problemem (chociaż chyba bardziej wyzwaniem) jest obowiązkowe planowanie scope releasów. Ciągłe dorzucanie nowych rzeczy do developa spowoduje, iż develop będzie zablokowany, dopóki wszystko w nim zawarte nie zostanie ustabilizowane. Najgorsza sytuacja jest wtedy, kiedy wszyscy jesteśmy gotowi ze swoimi funkcjami, ale nie możemy zrobić release, ponieważ ktoś wrzucił do developa zalążek kolejnej funkcji. Funkcji, która nie jest gotowa do wypuszczenia.
Aby zapobiec tego typu sytuacjom, powinniśmy w jakiś sposób kontrolować to, co wchodzi do developa i w pewnym momencie odciąć nowe rzeczy, przynajmniej do momentu utworzenia brancha releasowego. Po utworzeniu release brancha, develop zostaje odblokowany – możemy mergować nowe rzeczy, dając równocześnie możliwość innym naprawiania rzeczy, które już prawie weszły, na branchu releasa.
Alternatywne podejście do GitFlow
Czasami zdarza się, iż develop zbyt często jest zablokowany. Może to być spowodowane wieloma czynnikami: złym zarządzaniem projektem, bardzo wstępną fazą projektu, zbyt zachłannym refactoringiem… Efekt jest taki sam: klient (bądź szef) piekli się, iż prawie nic nie wypychamy. A my wiemy, iż to wszystko przez ciągle zblokowanego developa…
W moim doświadczeniu pojawiła się podobna sytuacja. Udało się nam przełamać ten niedobry trend poprzez modyfikację GitFlow, która później okazała się… dosyć popularną (przynajmniej w moim kręgu) rzeczą.
Pierwszą rzeczą, która ulega zmianie, jest źródło brancha. Zarówno hotfix jak i feature branch jest tworzony z mastera. Zmiana ta powoduje, iż developujemy naszą funkcjonalność w oderwaniu od pozostałych, w tej chwili developowanych, rzeczy.
Drugą zmianą jest przestawienie źródła prawdy developmentu. W standardowym GitFlow jest to branch develop. Kiedy potrzebujemy poprawić coś na developie, to tworzymy z niego brancha, robimy kilka commitów, mergujemy brancha do developa. W modyfikowanej wersji, o ile potrzebujemy poprawić coś w obrębie funkcjonalności, to robimy to cały czas na feature branchu. Po poprawkach, domergowujemy feature branch do developa, aby zintegrować naszą funkcję z pozostałymi.
Kolejną modyfikacją jest proces tworzenia brancha releasowego. Tutaj główną rolę ma system ticketowy, który bardzo mocno powinien pilnować tego, co jeszcze nie zostało wypuszczone. Release branch robimy z mastera, po czym – na podstawie informacji o niewypuszczonych ticketach – mergujemy do niego wszystkie rzeczy do zreleasowania.
Wady zmodyfikowanego GitFlow
Dzięki powyższym modyfikacjom znika problem związany z nieustannie zablokowanym developem. Zwinność wypuszczania nowych rzeczy zwiększa się. Pomimo tego, mamy kilka kwestii, które mogą przeważyć w drugą stronę:
- Zwiększona ilość sytuacji z konfliktami do rozwiązania. Bo rozwiązujemy konflikty podczas merge do developa, a następnie do release brancha.
- Branch develop stosunkowo często rozjeżdża się w stosunku do mastera. Spowodowane jest to sytuacją z punktu pierwszego. Może okazać się, iż co jakiś czas będziemy robić developa na nowo z mastera.
- Trochę więcej pracy do zrobienia wokoło wypuszczania nowych wersji. o ile wersje będą duże, to będziemy mieli dużo rzeczy do re-mergowania. No, ale skoro o zwinność tutaj chodzi, to trochę to się gryzie z dużymi releasami.
Każdą z opcji wybieraj świadomie
Ani GitFlow, ani jego wersja zmodyfikowana, nie są idealne. Z jednej strony mamy narzędzie, za pomocą którego mamy możliwość regularnego wypuszczania zaplanowanego scope (GitFlow), z drugiej strony mamy potencjał na bardzo zwinny development produkcyjny (wersja zmodyfikowana). o ile by odwrócić sytuację i kalkulować wadami, to mamy potencjalnie zblokowane release kontra rozjazdy developa wraz z dodatkowym nakładem pracy podczas wypuszczania nowej wersji. Dobrze jest znać ten zestaw zalet i wad obydwu rozwiązań i na ich podstawie coś wybrać.
Idealnie by było oczywiście mieć możliwość samemu spróbować obydwu opcji, zanim się wybierze. Tak idealnie nie jest, zawsze musi być ten pierwszy raz na wdrożenie nowego flow. Na szczęście, to nie jest tak, iż po wybraniu jednej z opcji zamykamy się na drugą. Możemy przez kilka miesięcy poćwiczyć z jedną z nich, po czym przejść na inne rozwiązanie.
—
(1) Jako merge, mam na myśli jakikolwiek sposób na połączenie ze sobą dwóch branchów. Możemy to robić zarówno dzięki polecenia git merge jak i git rebase. W tym miejscu nie chcę wypowiadać się na temat tego, które z nich jest lepsze i dlaczego.








