SonarQube - narzędzie do poprawy jakości i bezpieczeństwa kodu
Obecnie wykorzystanie modeli sztucznej inteligencji do wytwarzania systemu stało się niemal codziennością. Bardzo wątpliwe, iż aplikacje działające w środowiskach produkcyjnych zostały napisane w większości z pomocą AI. Natomiast nie zmienia to faktu, iż programiści i nie tylko chętnie korzystają z takowych udogodnień. AI jest w stanie gwałtownie wykonać przed wszystkim te żmudne aspekty programowania – bez większych trudności przygotuje algorytmy, zapisze je dzięki kodu w wybranym języku, a poza tym opracuje dokumentację czy przygotuje testy automatyczne. Na pewno zakres tych zastosowań jest większy i tylko od programisty zależy, jak bardzo wykorzysta sztuczną inteligencję w codziennej pracy.
Rozwój AI nie jest szczególnie spowolniony, więc można spodziewać się, iż jakość pracy modeli będzie wzrastać. Z przekonaniem można powiedzieć, iż najprostsze projekty nie stanowią wyzwania dla AI i dzięki temu praktycznie każdy zainteresowany (nie tylko z technicznymi kwalifikacjami) jest w stanie „napisać” i uruchomić żądane aplikacje. Może to być dla przykładu niewielka strona internetowa. AI wygeneruje kod HTML/PHP, poradzi sobie też ze stylami CSS czy skryptami JS. Co więcej, przedstawi konfigurację do zastosowania na serwerze, która umożliwi hostowanie przygotowanej witryny – oczywiście tak podstawowa konfiguracja nie powinna być stosowana w jakichkolwiek środowiskach produkcyjnych.
Otwarte pozostaje też pytanie o poziom jakości kodu zwróconego przez sztuczną inteligencję. Wiadome jest, iż doświadczony programista znajdzie w takim kodzie ewentualne miejsca do poprawy. Nie ma nic złego w umiejętnym stosowaniu AI. Ważna jest jednak świadomość możliwości popełnienia błędów czy zastosowania różnych niewłaściwych praktyk. jeżeli tylko ktoś jest w stanie skutecznie zweryfikować „mądrości” wytworzone przez AI, to dla takiej osoby możliwość optymalizacji pracy poprzez użycie AI będzie miała pozytywne skutki.
Inna sytuacja jest z osobami dopiero zaczynającymi karierę jako programista, którzy jeszcze nie mieli okazji sprawdzić się w realnych projektach, a już szczególnie tych realizowanych zespołowo. jeżeli zdecydują się na użycie AI – szanse są dość spore – to w przypadku trudniejszych zadań mogą nie znaleźć błędów. Zakładając sensowną praktykę użycia repozytoriów Git, „przygotowane” przez nich jakkolwiek niewłaściwe modyfikacje nie spowodują problemów w działaniu środowisk, bo zwyczajnie zostaną odrzucone przez starszych programistów posiadających większą rolę w repozytorium podczas code review przy okazji merge request.
Są jednak dwa problemy. Przede wszystkim zaawansowane projekty często cechują się jednoczesnymi pracami nad różnymi nowymi funkcjonalnościami czy zwykłymi zmianami w dotychczasowej logice. Lider techniczny czy choćby senior programista mogą być mniej skuteczni w trafnym ocenianiu jakości merge requestów, jeżeli dziennie mają ich dziesiątki. Nieraz wystąpią konflikty podczas próby merge’u brancha, które muszą zostać rozwiązane. jeżeli w końcu uda się zamknąć dany MR, to pewnie i tak będzie musiał poczekać na wykonanie CI/CD, a samo wdrożenie na środowisko testowe może się nie udać, bo na przykład nie zadziała migracja.
Trzeba przy tym pamiętać o różnych zależnościach – przecież zmiana wprowadzona przez programistę może powodować problemy w części kodu, której nie modyfikował. Analogiczne problemy powinny zostać znalezione na etapie testów automatycznych czy manualnych, ale lepiej blokować takie zmiany wcześniej.
SonarQube - wykrywanie nieprawidłowości w kodzie
Z tego powodu zalecane jest stosowanie narzędzi weryfikujących jakość kodu źródłowego. Wiodącym rozwiązaniem w tym zakresie pozostaje SonarQube od szwajcarskiej firmy Sonar. Skutecznie wykrywa wszelkie nieprawidłowości w kodzie napisanych we wszystkich współczesnych językach programowania. Pod względem ilości obsługiwanych technologii nie ma żadnej lepszej alternatywy.
Oprócz analizy typowego kodu źródłowego SonarQube zapewnia też weryfikację definicji serwisów Kubernetes, obrazów Docker (Dockerfile) czy plików TF stosowanych przez Terraform. Oznacza to, iż potrafi zadbać nie tylko o jakość samego oprogramowania, ale również o możliwie najlepsze praktyki w obszarach DevOps. Nie trzeba wyjaśniać, iż aktualne trendy zakładają konteneryzację i pełną automatyzację – warto więc korzystać ze sprawdzonych rozwiązań.
Istotna zaleta SonarQube to bardzo łatwe użycie i integracja z istniejącym CI/CD. Najlepiej dodać job wykonywany przy okazji merge request, aby na możliwie wczesnym etapie określić problemy występujące w kodzie źródłowym.
Nie można pominąć funkcjonalności SAST – są te testy bezpieczeństwa wykonywane na podstawie samego kodu. Możliwe jest wykrycie przykładowo kluczy API czy haseł znajdujących się w repozytorium, ale też ewentualnych podatności SQL injection, XSS itp.
SonarQube na tę chwilę jest oferowanych w trzech planach cenowych. Do nauki podejścia pracy z testami kodu zupełnie wystarczająca będzie edycja community – plan Free.
Wdrożenie SonarQube
Najprostsza, ale przede wszystkim najszybsza metoda uruchomienia SonarQube to użycie kontenera Docker z gotowym, oficjalnym obrazem. W pierwszej kolejności polecam jednak zadbać o konfigurację parametrów kernela i serwera reverse proxy.
Elasticsearch działający w kontenerze z SonarQube nie uruchomi się, jeżeli w systemie hosta nie zostanie ustawiony parametr vm.max_map_count = 262144. Wprowadzenie tej zmiany ogranicza się do poleceń
Odpowiednie ustawienia dla wybranych serwerów reverse proxy zostały przedstawione na stronie https://docs.sonarsource.com/sonarqube-server/server-installation/network-security/securing-behind-proxy. W moim środowisku testowym korzystam z HAProxy i dlatego wymagane jest jedynie dodanie poniższej, bardzo prostej konfiguracji do pliku haproxy.cfg:
Nie można zapomnieć o umożliwieniu połączenia do kontenera nazwanego tutaj sonarqube. Odpowiednim sposobem jest zastosowanie tej samej Docker network, którą trzeba wcześniej utworzyć poleceniem
Treści pliku docker-compose.yml zawierającego definicję usługi haproxy także nie musimy znacząco komplikować.
W katalogu ssl znajduje się plik PEM – „połączenie” certyfikatu i klucza dla wybranej przez nas domeny. HAProxy obsługuje wyłącznie tę formę zapisu, ale jest to wygodne, bo ostatecznie potrzebna jest mniejsza ilość plików do utrzymania. Warto dodać, iż jeżeli reverse proxy ma kierować do różnych domen (z osobnymi certyfikatami), to podajemy je w tym samym frontend – HAProxy na podstawie SNI będzie wiedzieć, którego certyfikatu użyć dla danej domeny. jeżeli chodzi o wygodę korzystania, to w mojej ocenie nie ma lepszej alternatywy oferującej funkcjonalność load balancingu.
docker-compose.yml dla SonarQube jest znacznie bardziej złożony. Mocno polecam jednak dostosowanie zawartych w nim definicji do pewnego standardu pracy. Na początek zmieńmy hasło do bazy danych, bo „sonar” nie jest zbyt złożone.
Istniejące volumes ustawmy jako mount bind. Zapewni to możliwość podglądu zapisywanych danych bez konieczności „wchodzenia” (docker exec) do kontenera, a poza tym jest to lepsze podejście w kontekście wykonywania kopii zapasowych.
Usuwamy też całe bloki volumes (będziemy korzystać z mount bind), networks i ports (nie ma potrzeby, aby wystawiać port, na którym działa SonarQube, skoro ruch będzie obsługiwany przez reverse proxy). Zmieniamy nazwę sieci w definicjach serwisów.
Na koniec dodajmy poniższy blok, który informuje silnik Docker, iż zdefiniowana sieć powinna już istnieć – nie może więc tworzyć osobnej. Dzięki temu wszystkie wymagane przez nas kontenery będą mogły komunikować się ze sobą. Zdecydowanie rekomenduję to podejście, gdy nasze usługi są zdefiniowane w osobnych plikach compose.
Ostatecznie powinniśmy otrzymać zawartość zbliżoną do poniższej.
Musimy jeszcze zadbać o odpowiedniego właściciela katalogów wykorzystywanych przez SonarQube, które podaliśmy jako volumes. Aplikacja w kontenerze jest uruchomiona na prawach użytkownika sonarqube, który rzecz jasna nie istnieje w naszym systemie – dlatego parametr polecenia chown musimy podać jako ID (użytkownika i grupy), czyli 1000:0 (gdy jest używana nazwa użytkownika, to wystarczy podać np. www-data:). Jak ustalić UID/GID użytkownika z obrazu? Zwyczajnie uruchomić kontener (np. docker run -it <obraz> bash) i wykonać polecenie id. Na koniec usunąć kontener, aby nie działał bez potrzeby i jedynie wykorzystywał zasoby.
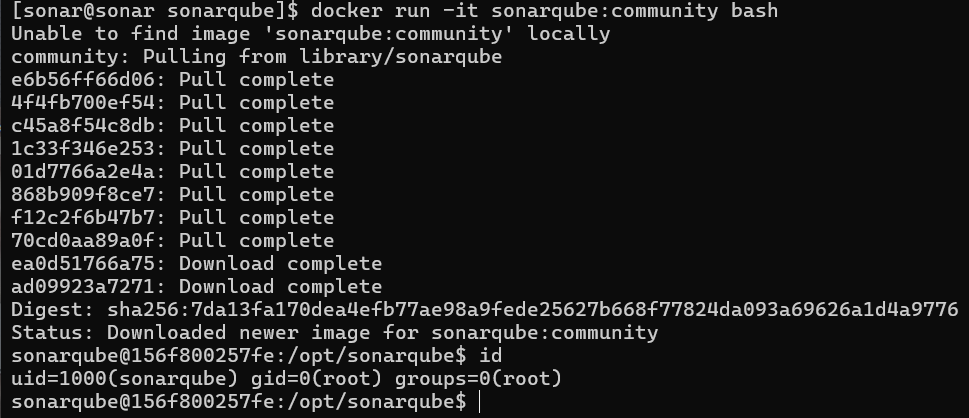 Sprawdzenie UID użytkownika w kontenerze
Sprawdzenie UID użytkownika w kontenerze
Tworzymy więc te katalogi i nadajemy odpowiedniego właściciela.
Uruchamiamy kontener z SonarQube.
Można teraz sprawdzić logi, aby upewnić się, iż proces uruchomienia przebiega poprawnie. jeżeli zobaczymy wpis SonarQube is operational, to uruchamiamy kontener z HAProxy tym samym poleceniem. Sam start SonarQube może chwilę potrwać. Po uruchomieniu obu kontenerów można w przeglądarce przejść pod adres domeny obsługiwanej przez HAProxy. Powinniśmy wtedy zobaczyć ekran logowania do SonarQube.
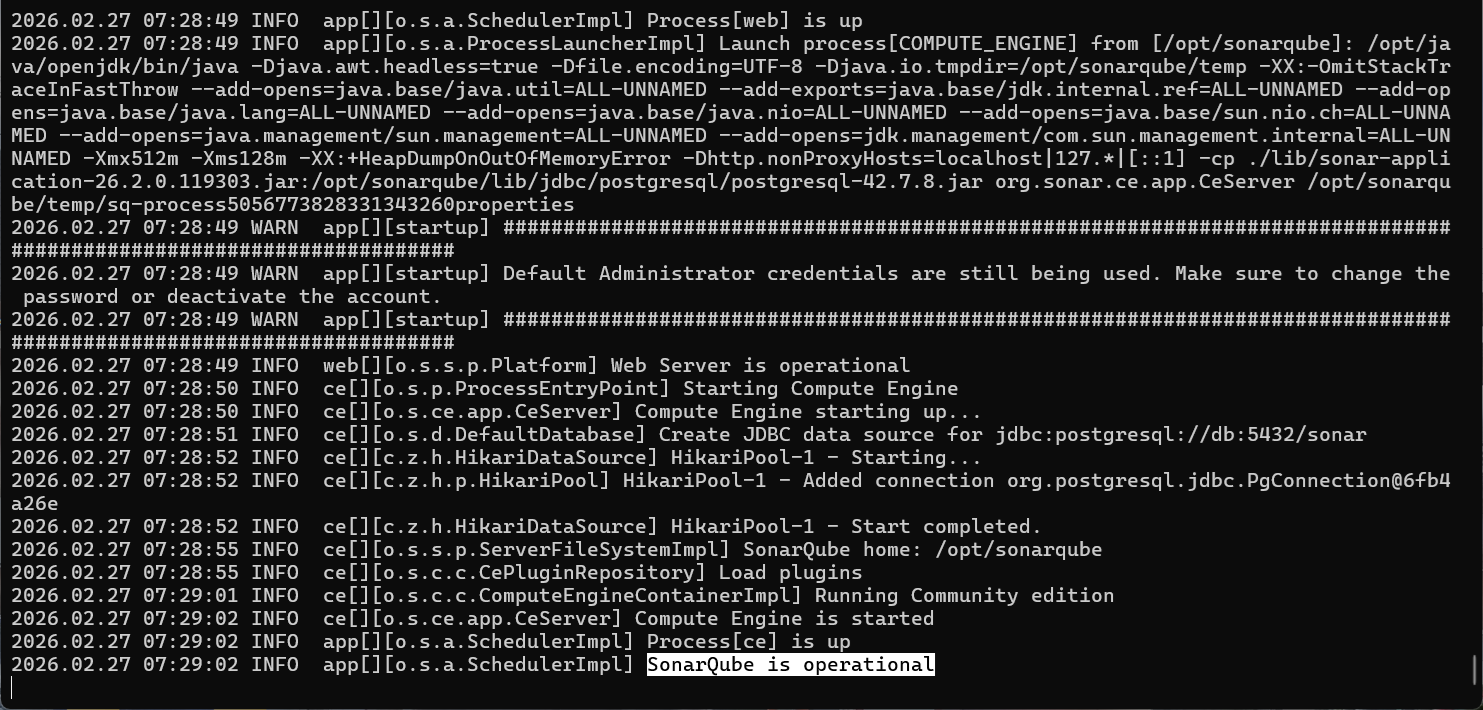 Komunikat o pomyślnym uruchomieniu SonarQube
Komunikat o pomyślnym uruchomieniu SonarQube
 Ekran logowania SonarQube
Ekran logowania SonarQube
Zalecana konfiguracja startowa
Domyślne poświadczenia to admin/admin. Po pierwszym udanym logowaniu zostanie wymuszona zmiana hasła.
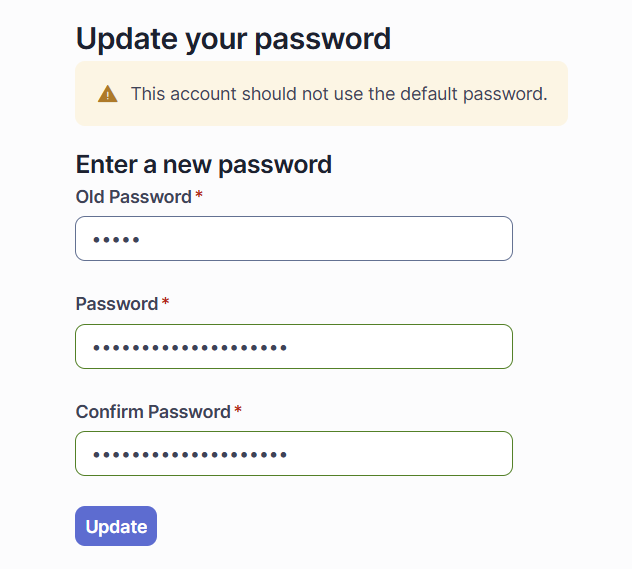 Zmiana hasła dla użytkownika admin
Zmiana hasła dla użytkownika admin
Jeśli wykonamy ten krok, to zobaczymy adekwatny panel SonarQube. Odpowiednie ustawienia zostały logicznie poukładane w menu, więc choćby jeżeli nigdy nie mieliśmy okazji pracować z tym rozwiązaniem, wciąż nie powinniśmy napotkać problemów z odnalezieniem potrzebnych funkcji.
Pokażę najbardziej uniwersalny sposób korzystania z SonarQube. Na początku trzeba wiedzieć, iż każdy kod (repozytorium) jest osobnym projektem. Do konkretnego projektu możemy nadać uprawnienia wybranym osobom – pewnie będzie to zespół pracujący nad daną aplikacją. Nie chcemy jednak, aby dowolna osoba mogła tworzyć własne projekty, bo w krótkim czasie takie podejście doprowadzi do nieuporządkowanego stanu.
Same projekty będą tworzone automatycznie po pierwszym uruchomieniu skanowania – SonarQube posiada własne API, które obsługuje „skaner”. W katalogu z kodem musi znajdować się jedynie plik sonar-project.properties z dosłownie czterema liniami, które wskażą ścieżkę do projektu, jego „przyjazną” nazwę, adres instancji SonarQube i klucz API. Niektóre narzędzia powiązane z językami programowania posiadają wbudowaną obsługę SonarQube (m.in. Maven i plugin sonar-maven-plugin) i wtedy wymienione parametry definiuje się w sposób adekwatny do danej technologii – tutaj jednak ograniczmy się do zupełnie podstawowej metody użycia SonarQube.
Najpierw przechodzimy do zakładki Administration i dalej Security -> Global Permissions. Przy wpisie dla grupy sonar-users odznaczamy wartości w kolumnach Execute Analysis i Create – aby nie działało żadne dziedziczenie uprawnień. Będziemy nadawać je konkretnym użytkownikom.
 Ograniczenie grupy sonar-users
Ograniczenie grupy sonar-users
Teraz przechodzimy do zakładki Security -> Permission Templates. Wybieramy jedyny dostępny szablon, czyli Default template. Analogicznie odbieramy wszystkie uprawnienia dla grupy sonar-users.
 Odebranie uprawnień grupie sonar-users
Odebranie uprawnień grupie sonar-users
Przygotowanie do testów
Kolejnym etapem jest uruchomienie dowolnego serwera HTTP i repozytorium Git. Serwer HTTP będzie potrzebny do hostowania archiwum ZIP zawierającego skaner i wszystkie jego zależności – w kontekście CI/CD zalecane jest unikanie (w miarę możliwości) korzystania z zewnętrznych zasobów. jeżeli w danej chwili zdalny zasób nie będzie dostępny, to nie wykona się job – pipeline będzie zablokowana, a to oznacza przestoje i słuszną frustrację zespołu. O takich szczegółach należy pamiętać.
Z kolei repozytorium Git jest standardem w pracy z kodem źródłowym. Prawdopodobnie Gitea okaże się rozwiązaniem, które można uruchomić najszybciej. Praktycznie zaraz po starcie jest gotowe do pracy. Z kolei jako serwer HTTP polecam nginx – w celach testowych wystarczy sama instalacja i zapisanie archiwum w katalogu /var/www/html.
Odnośnik do najnowszej wersji SonarScanner znajdziemy na stronie https://docs.sonarsource.com/sonarqube-server/analyzing-source-code/scanners/sonarscanner.
 Strona pobierania SonarScanner
Strona pobierania SonarScanner
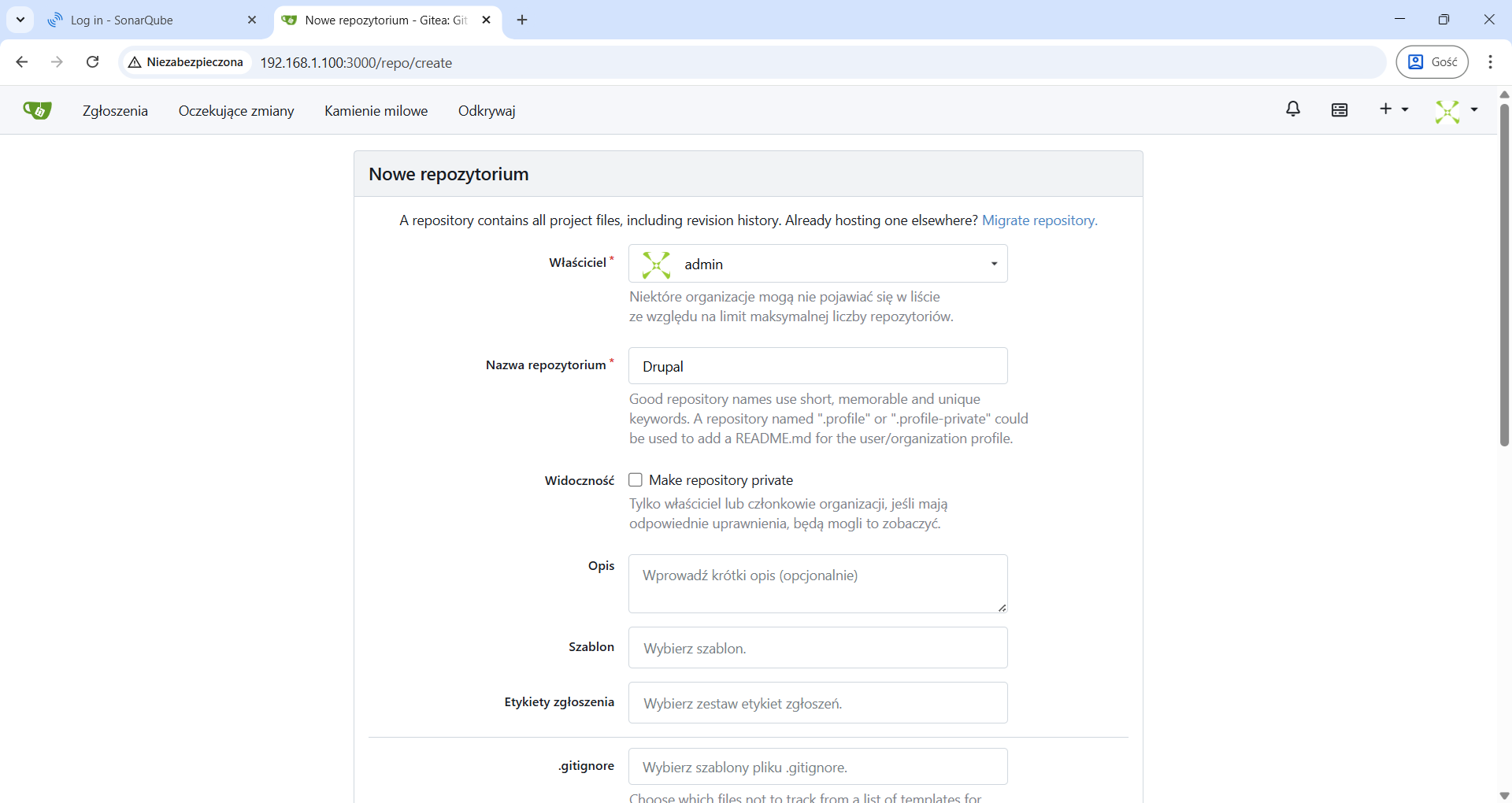 Tworzenie repozytorium w Gitea
Tworzenie repozytorium w Gitea
Dla przykładu utworzyłem cztery repozytoria dla aplikacji, które będziemy testować narzędziem SonarQube – Drupal, NodeBB, Redmine i framework Django.
Zarządzanie użytkownikami i uprawnieniami
Teraz dodamy użytkowników, którzy będą posiadać uprawnienia pozwalające na dostęp do wybranych projektów. Po otwarciu karty Administration przechodzimy kolejno do Security -> Users. Przyciskiem Create User otworzymy formularz dodawania użytkownika. Obowiązkowe do wypełnienia pola to login, hasło (wpisane dwukrotnie) oraz nazwa – jak poniżej.
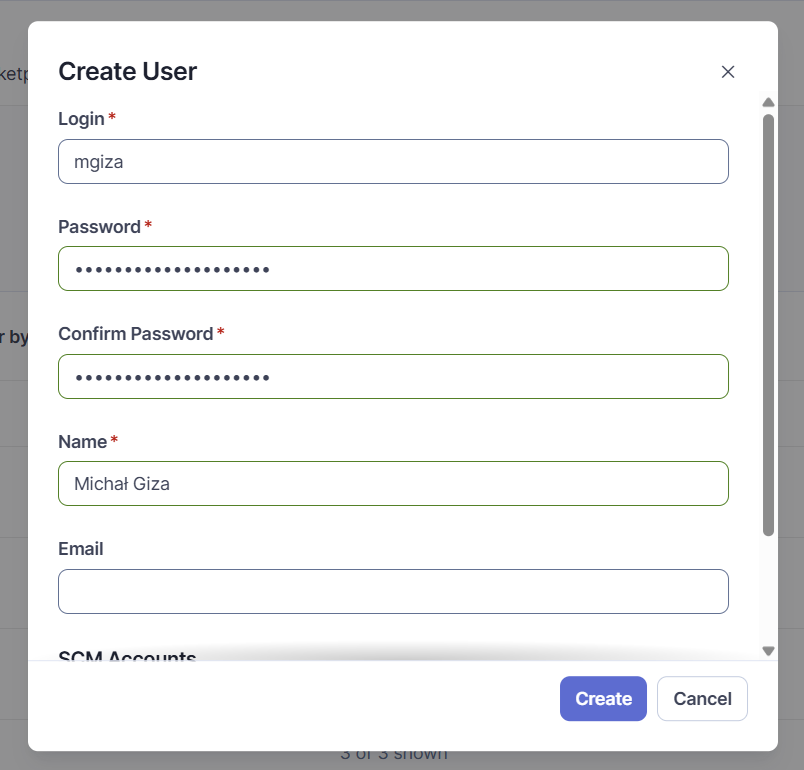 Formularz dodawania użytkownika
Formularz dodawania użytkownika
Polecam wykorzystywać konta „techniczne” do celów komunikacji skanera z API. W tej samej zakładce tworzymy kolejno konto nazwane przykładowo drupal_api (nazwaprojektu_api). Umożliwi to wygodne zarządzanie dostępami i łatwe blokowanie konta w przyszłości. Po dodaniu takiego konta należy przejść do Security -> Global Permissions i zaznaczyć przy danym użytkowniku uprawnienia z kolumny Execute Analysis i Create – przy czym uprawnienie Create zalecam odbierać niezwłoczenie po zakończeniu pierwszego skanowania.
 Uprawnienia użytkownika technicznego
Uprawnienia użytkownika technicznego
Teraz logujemy się standardowo utworzonym kontem *_api i po kliknięciu w prawym górnym rogu ikony z inicjałem użytkownika wybieramy My Account. Tutaj w zakładce Security tworzymy klucz API (User Token) do zastosowania przez skaner. Wygenerowany token (początek tego ciągu zawsze zaczyna się od squ_) należy bezpiecznie przechowywać. W przypadku CI/CD może sprawdzić się ukryta zmienna, która będzie podstawiana do pliku sonar-project.properties.
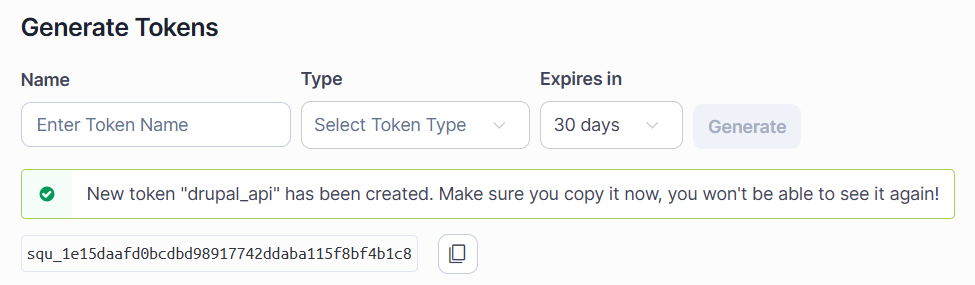 Tokeny do użycia API
Tokeny do użycia API
Uruchomienie skanowania
Proces przygotowania skanowania nie jest trudny. W katalogu root sklonowanego repozytorium tworzymy plik sonar-project.properties o analogicznej zawartości (można użyć polskich znaków w projectName).
Następnie przechodzimy katalog wyżej i pobieramy oraz wypakowujemy archiwum z SonarScanner. Paczka ta zawiera wszystkie potrzebne komponenty, w tym JDK do wykonania skanera. Przechodzimy ponownie do katalogu projektu i uruchamiany binarkę sonar-scanner.
Dokładnie to samo podejście może zostać z powodzeniem wykorzystane w CI/CD.
W zależności od ilości kodu skanowanie może trwać przez dłuższy czas. Postęp będzie regularnie aktualizowany.
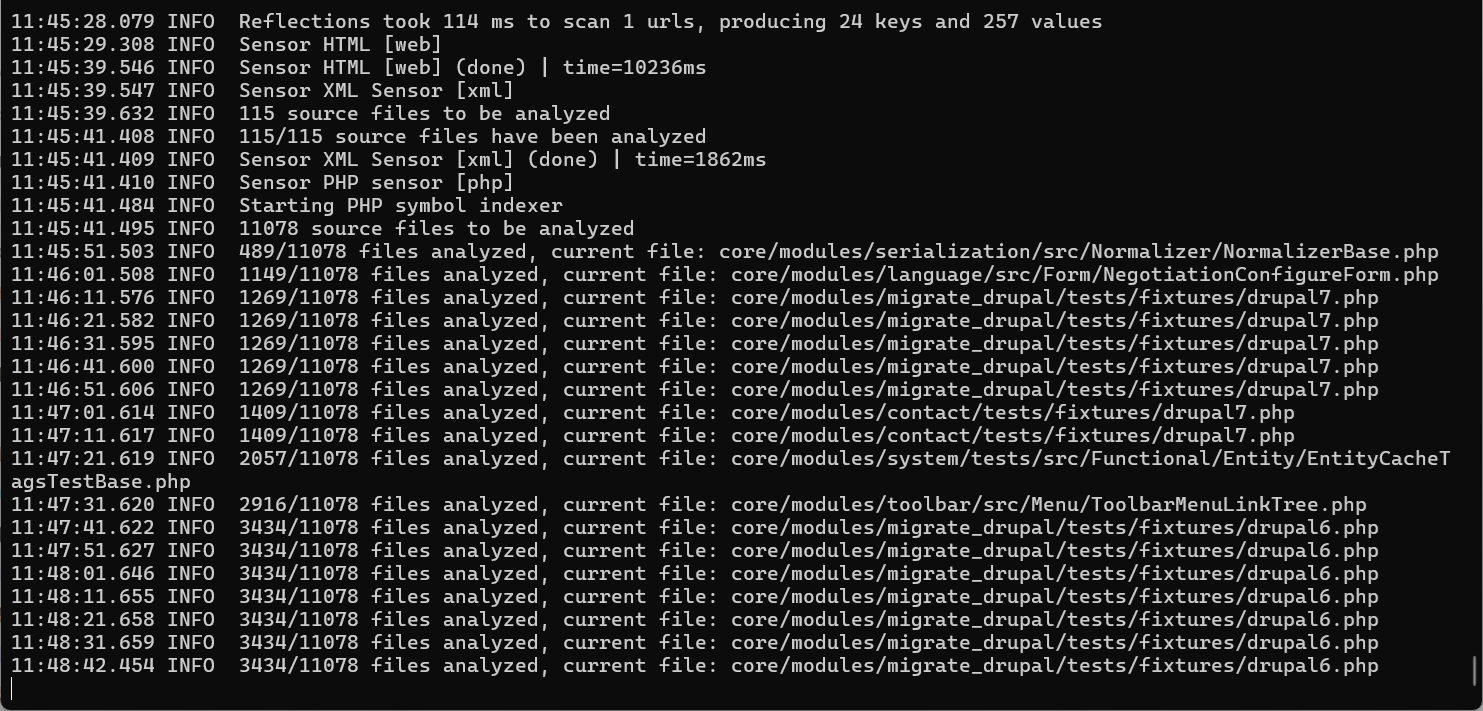 Postęp skanowania kodu
Postęp skanowania kodu
Konieczne może okazać się również oczekiwanie na załadowanie wyników testu – SonarQube musi „uporządkować” dane przesłane przez skaner. Ostatecznie jednak po wejściu na adres https://sonar.avlab.pl/dashboard?id=<nazwaprojektu> zobaczymy widok zbliżony do poniższego.
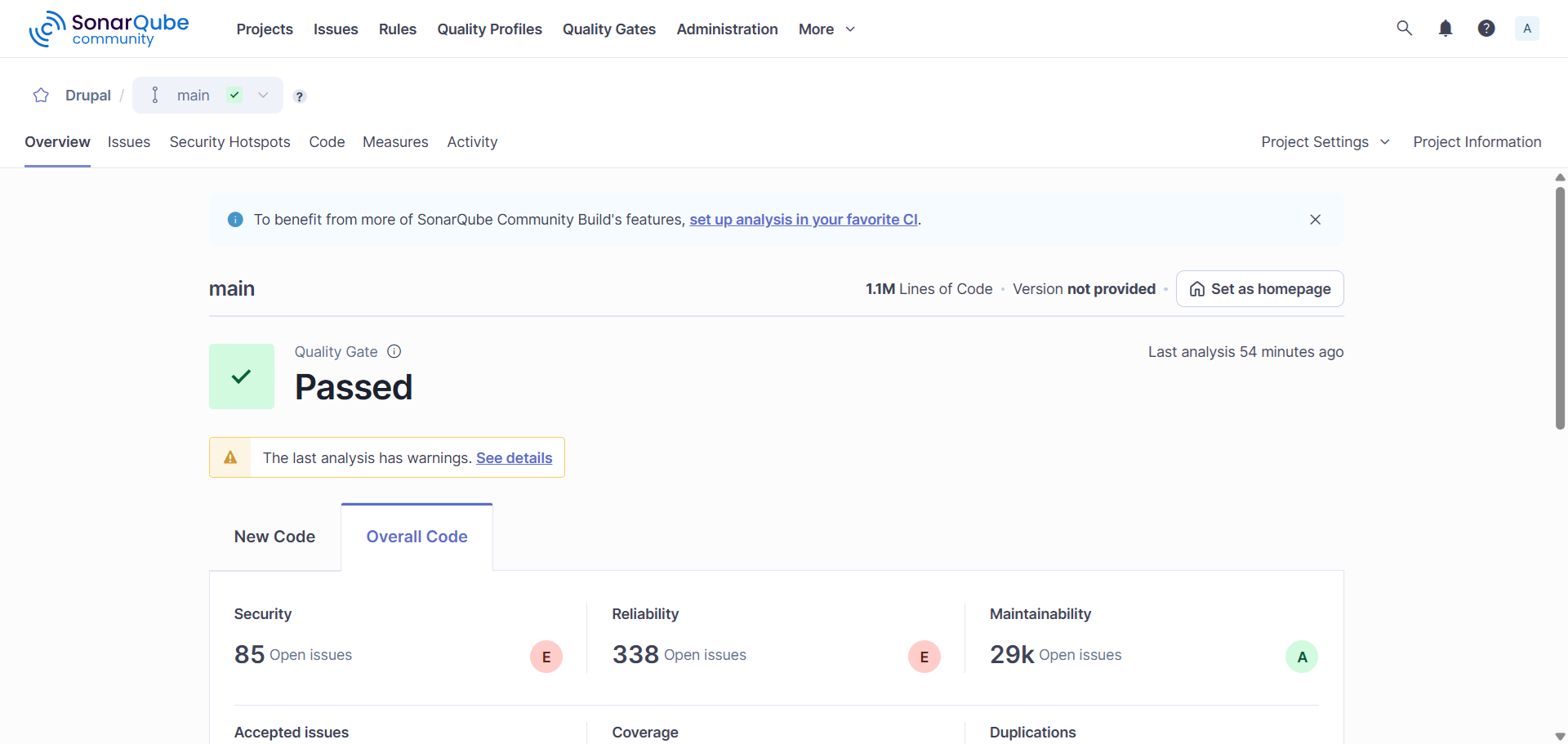 Podsumowanie wyników testu w SonarQube
Podsumowanie wyników testu w SonarQube
Nadawanie dostępów do projektu
Należy teraz zmienić zakres dostępu do projektu. Na początku przechodzimy do Administration i kolejno Security -> Global Permissions. Użytkownikowi technicznemu odbieramy uprawnienie do tworzenia projektów (kolumna Create). Wracamy do projektu, po czym rozwijamy menu Project Settings i wchodzimy do Permissions. Ustawiamy widoczność na Private.
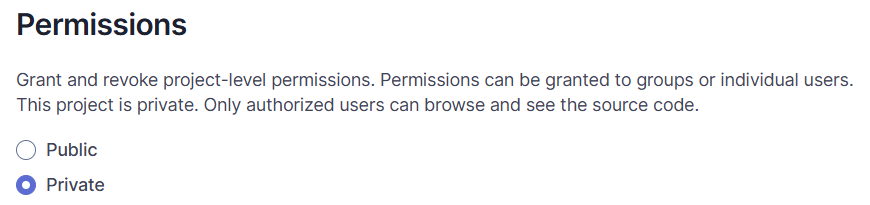 Zmiana zakresu widoczności projektu
Zmiana zakresu widoczności projektu
Po tej operacji zmienimy uprawnienia użytkowników i grup w zakresie dostępu do projektu. Powinno wyglądać to następująco:
- grupa sonar-administrators – zaznaczona pozycja w kolumnie Administer
- użytkownik techniczny *_api – zaznaczona pozycja w kolumnie Execute Analysis
- wszystkie osoby z zespołu – zaznaczone pozycje w kolumnach Browse, See Source Code, Administer Issues, Administer Security Hotspots
Przeglądanie wyników testu
Osoby z zespołu powinny od tego momentu mieć widoczny projekt na liście. Kluczowa jest zdecydowanie karta Issues, bo zawiera pogrupowane wszystkie wykryte błędy.
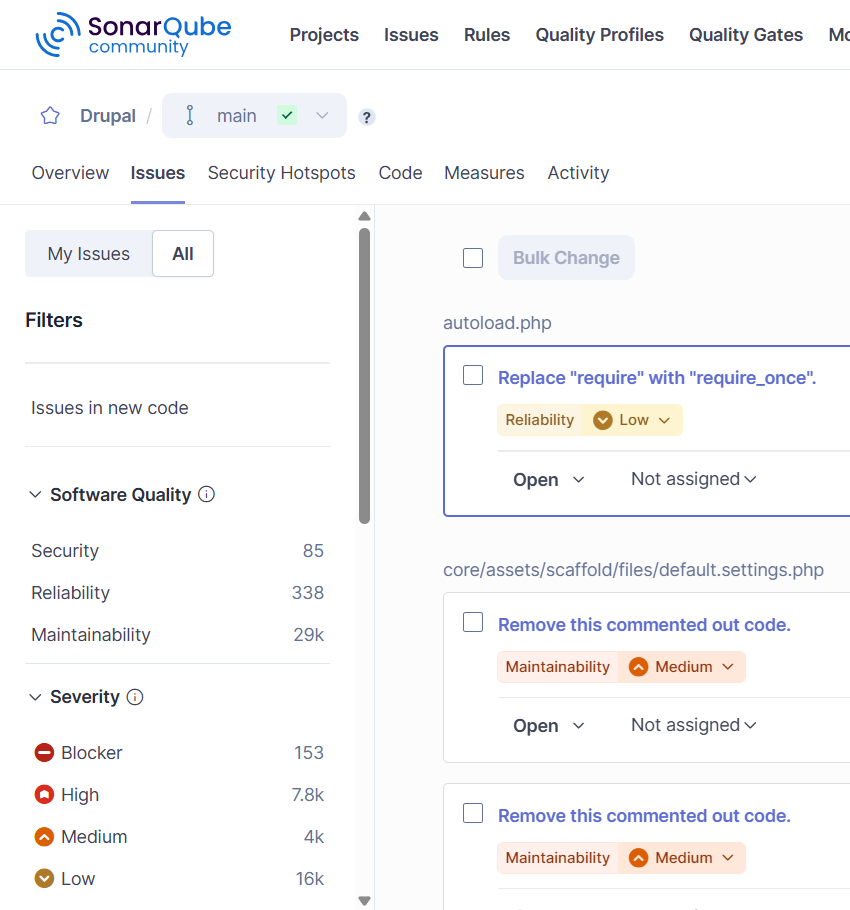 Wykryte błędy w kodzie aplikacji Drupal
Wykryte błędy w kodzie aplikacji Drupal
Po otwarciu danego błędu zostanie wyświetlona także instrukcja „naprawy”. Do wykrytych problemów należy podchodzić uważnie, bo nie ma doskonałych narzędzi – SonarScanner też popełnia błędy. Dodatkowo nie każda poprawa jest możliwa. jeżeli zastosowany „fix” usunie problem wykryty przez SonarScanner, ale jednocześnie spowoduje błąd w działaniu aplikacji, to raczej nie można tego uznać za skuteczną technikę programowania. Zresztą podobna zasada obowiązuje w przypadku raportów z testów bezpieczeństwa. Tester nie musi znać całej logiki biznesowej i wszelkich zależności – funkcja będąca dla niego podatnością jednocześnie może stanowić obejście problemu w samej aplikacji.
Dla odmiany użytkownik nieprzypisany do żadnego projektu nie będzie miał żadnego wyboru.
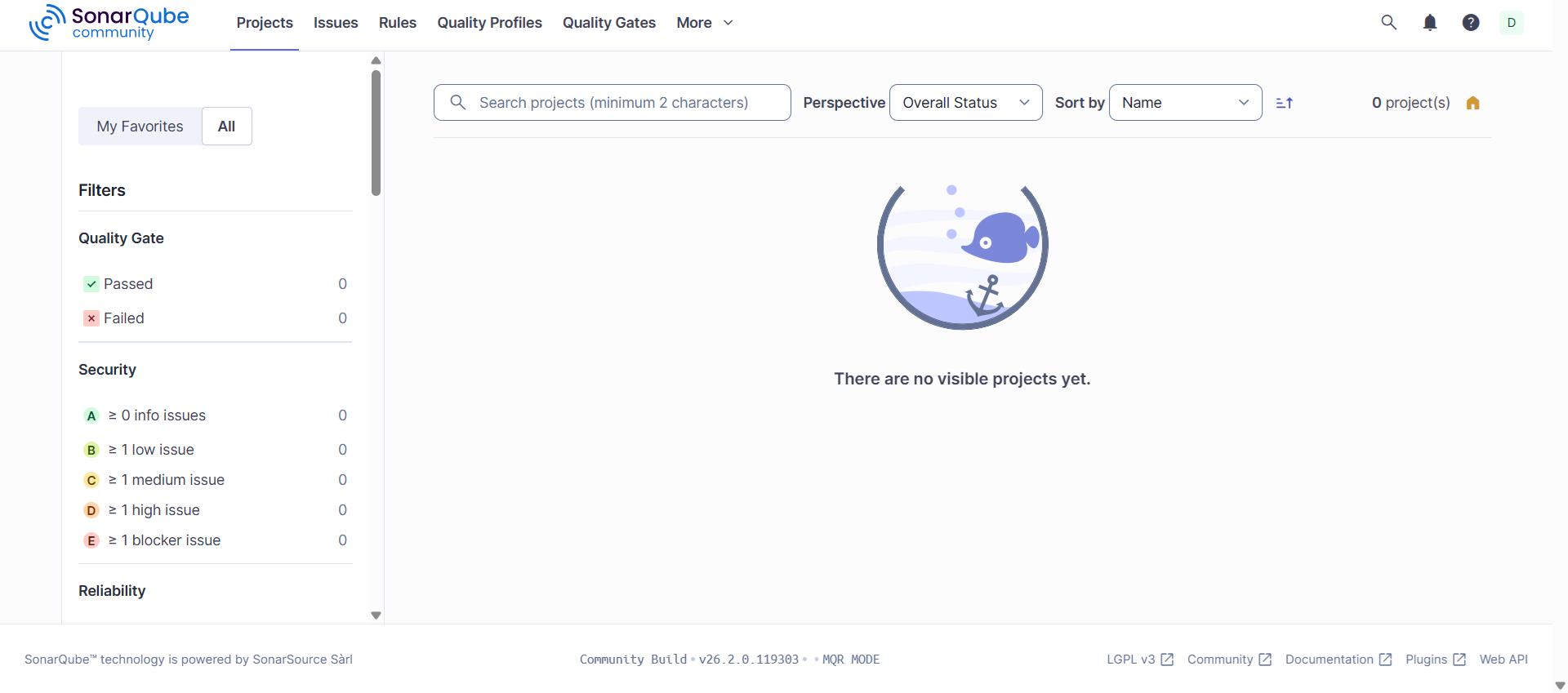 Widok użytkownika bez uprawnień w projektach
Widok użytkownika bez uprawnień w projektach
Podobne czynności możemy wykonać dla pozostałych testowanych aplikacji.
Podsumowanie
SonarQube jest współcześnie standardowym rozwiązaniem do analizy kodów źródłowych. Biorąc pod uwagę prostotę używania, możliwość obsługi w zasadzie dowolnej technologii oraz przejrzystość interfejsu, jego rozpoznawalność u nikogo nie powinna budzić wątpliwości. Warto znać sposób użycia SonarQube i regularnie audytować jakość wytwarzanego kodu. Budowanie swojej wiedzy w oparciu o znaczące narzędzia jest doskonałym podejściem.







