Generator został wprowadzony do PHP stosunkowo dawno. adekwatnie to został dodany wraz z wersją PHP 5.5.0 w roku 2013. Wychodzi więc na to, iż jest z nami już od niemal dekady!
A wiesz, kiedy został wprowadzony Iterator? W wersji 5.0.0 beta 3, czyli w 2003 roku! Oznacza to, iż Iteratora możemy używać od niemal dwudziestu lat!
Przyznasz mi chyba rację, iż brzmi to jak totalna prehistoria, prawda? Wydawałoby się, iż zupełnie nie ma sensu w ogóle poruszać takiego tematu. Nic bardziej mylnego.
W trakcie mojej pracy jako Tech Lead oraz Konsultant zauważyłem, iż wielu developerów ma spory problem z poprawnym opisaniem Iteratora i Generatora na poziomie teoretycznym. Okazuje się, iż nie każdy dev wie, czym te byty się charakteryzują oraz jakich korzyści mogą nam dostarczyć.
W tym poście opowiem Ci trochę o Iteratorach i Generatorach. Pokażę Ci czym się różnią oraz jak możesz ich użyć na swoją korzyść przy adresowaniu problemów natury optymalizacyjnej!
Iterable
Na początku warto byłoby opowiedzieć sobie o tym, czym jest Iterable. Otóż jest to tzw. pseudo-typ w PHP, który stanowi alias na typy takie jak array i Traverasble. Został on wprowadzony w PHP 7.1.
Iterable może być używany jako deklaracja typu, czyli może zostać użyty jako type-hint oraz jako return type.
Co ważne, iterable służy do tego, aby zidentyfikować, czy dana zmienna może zostać użyta w pętli foreach.
Spójrz na poniższy przykład użycia pseudo-typu iterable:
Traversable
Przy okazji omawiania pseudo-typu iterable, wspomnieliśmy o tym, iż jest to alias an typy takie jak array i Traversable. O ile każdy PHP dev powinen wiedzieć czym jest array, to nie każdy może wiedzieć, czym jest Traversable.
W kontekście programowania słowo Traversable w języku angielskim oznacza po prostu, iż dana struktura danych może być przechodzona (czyli traversed), w celu przetworzenia jej elementów.
Traversable, to interfejs wbudowany w PHP, służący do zidentyfikowania, czy obiekt danej klasy może posłużyć do użycia w pętli foreach.
Traversable stanowi swoisty „interfejs abstrakcyjny”, który nie może zostać samodzielnie zaimplementowany. Oczywiście pamiętaj, iż w PHP nie mamy czegoś takiego jak „interfejsy abstrakcyjne” – to tylko taki skrót myślowy. ¯\_( ツ )_/¯
Spójrz na poniższy przykład:
Jak widzisz bezpośrednia próba implementacji Traversable, zakończy się otrzymaniem brzydkiego fatal errora na klatę. To, co możesz zrobić, to zaimplementować interfejs, który rozszerza już Traversable (np. Iterator) lub możesz rozszerzyć sobie Traversable swoim własnym interfejsem.
Iterator interface
Wspomnieliśmy sobie o tym, iż istnieje coś takiego jak Iterator iterface. Jest to wbudowany w PHP interfejs do użycia zewnętrznego, z którego możemy skorzystać, implementując nasze własne iteratory. Spójrz na poniższą implementację:
Jak widzisz, iterfejs ten wymaga od nas zaimplementowania następujących metod:
- current – jest to metoda, która zwróci bieżący element w ramach iteracji
- next – jest to metoda, która jest odpowiedzialna za przejście do kolejnego elementu, w celu kontynuowania iteracji
- key – metoda, która zwróci nam klucz bieżącego elementu.
- valid – metoda, która sprawdzi, czy element, który jest rozważany w ramach iteracji, jest prawidłowy. o ile zostanie zwrócony tutaj false, to jest to dla PHP informacja, żeby taką iterację po prostu przerwać.
- rewind – metoda, która „przesunie” nasz iterator do pierwszego elementu. Ta metoda jest zawsze wywoływana przed rozpoczęciem pierwszej iteracji.
Warto zdawać sobie sprawę, iż silnik PHP używa tych wszystkich metod w trakcie pętli foreach. Poniżej przedstawiam diagram, który pokazuje kolejność wywołania tych metod:
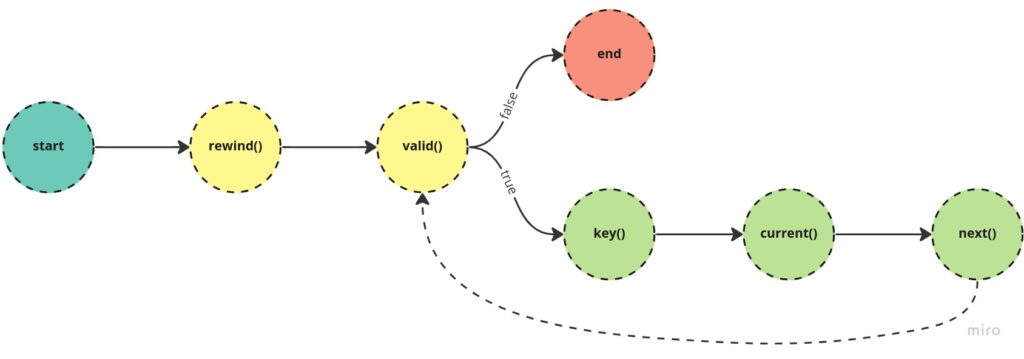 Diagram przedstawiający kolejność wywołania metod Iteratora w ramach iteracji
Diagram przedstawiający kolejność wywołania metod Iteratora w ramach iteracji- Na początku każdej iteracji wywoływana jest metoda rewind(). Gwarantuje ona to, iż dany iterator zostanie przesunięty do początkowego elementu.
- Następnie wywoływana jest metoda valid(). Sprawdza ona, czy możemy przeiterować po danym elemencie
- Jeżeli dostaniemy tutaj false – pętla zostaje przerwana.
- Jeżeli dostaniemy true, następuje kontynuacja uruchomienia Iteratora i przejście do adekwatnej iteracji.
- Jeżeli element jest prawidłowy, to następuje wywołanie metody key(), która zwiera informację na temat klucza danego elementu.
- Później wywoływana jest metoda current(). Zwraca ona bieżący element w ramach iteracji.
- Następuje wywołanie metody next(). Zmienia ona bieżący element. Po wywołaniu metody next() wracamy do pkt. 2.
IteratorAggregate interface
W kontekście iteratorów warto wspomnieć również o interfejsie o nazwie IteratorAggregate. Jest to kolejny wbudowany w PHP iterfejs, którego zadaniem (w dużym uproszczeniu) jest zwrócenie obiektu, który jest Traversable. Spójrz na poniższy przykład:
Klasa implementująca ten interfejs musi zawierać metodę getIterator(), która musi zwrócić obiekt implementujący klasę Traversable. Jak widzisz na przykładzie – ja zwróciłem po prostu jeden z wbudowanych w PHP iteratorów o nazwie ArrayIterator. Następnie obiekt klasy UserIteratorAggregate został użyty bezpośrednio w pętli foreach.
Jaki z tego wniosek? Ano taki, iż jest to bardzo przyjemny sposób na oddelegowanie sobie procesu wytwórczego naszego iteratora. Co ważne, dzięki IteratorAggregate nie mamy tego samego narzutu implementacyjnego jak w przypadku Iteratora, co sprawia, iż możemy gwałtownie go sobie zaimplementować. Niestety, przez szybkość tracimy również elastyczność, ponieważ nie będziemy mogli wpłynąć na implementację iteratora.
Iteratory dostępne w SPL
W SPL, czyli Standard PHP Library, posiadamy całą gammę wbudowanych iteratorów, z których możemy skorzystać.
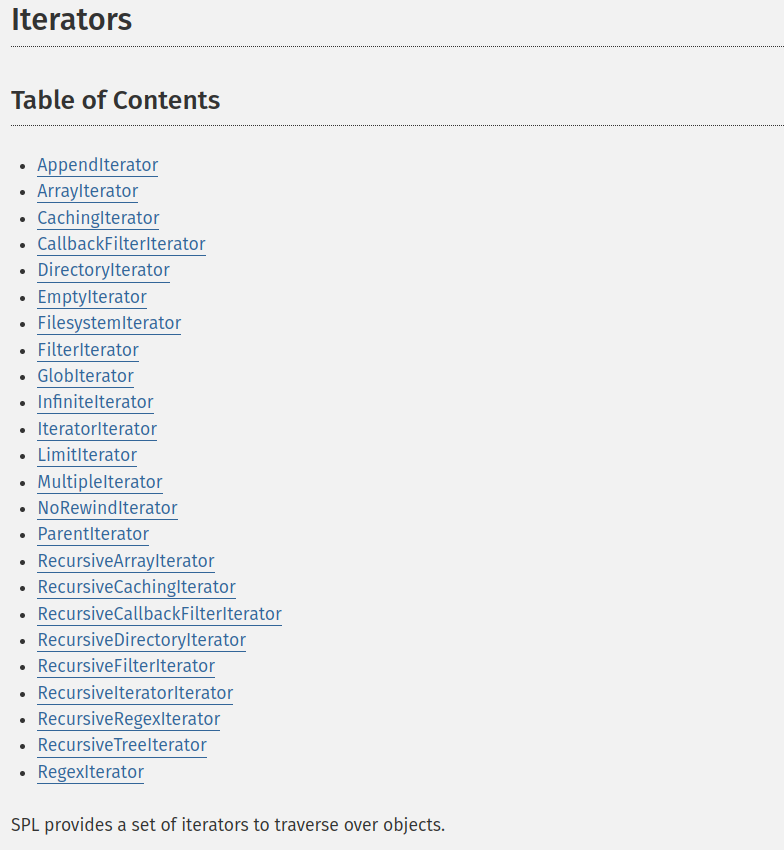 https://www.php.net/manual/en/spl.iterators.php
https://www.php.net/manual/en/spl.iterators.phpJak widzisz, jest ich całkiem sporo. Z tego względu nie omówimy ich w dzisiejszym poście. Warto jednak pamiętać, iż istnieją i mogą nam pomóc w rozwiązaniu wielu specyficznych case’ów. Zachęcam Cię do zapoznania się z dokumentacją.
Po co używać iteratorów?
Powiedzieliśmy sobie trochę o iteratorach. Po co ich adekwatnie używać? Przecież możemy używać sobie po prostu klasycznego arraya i zapomnieć o całej sprawie. Okazuje się, iż zalet jest całkiem sporo:
- Enkapsulacja – dzięki iteratorom możemy zamknąć cały proces iteracji przez daną kolekcję, tak, aby „świat zewnętrzny” nie był świadomy wewnętrznych operacji.
- Kompozycja – Możemy wpłynąć na zachowanie całej iteracji poprzez komponowanie wielu obiektów iteratora. Umożliwia nam to np. OuterIteratorInterface, który pozwala nam na zdefiniowanie InnerIteratora. Dzięki temu możemy łatwo zaimplementować uruchomienie kilku następujących po sobie iteratorów.
- Lepsza organizacja danych – nasze dane przestają być „anonimową arrayką” i zaczynają mieć jakąkolwiek tożsamość w naszym kodzie
- Dostępność SPL Iteratorów – SPL zawiera wiele iteratorów dostępnych od ręki. Out of the box dostajemy rozwiązanie na wiele specyficznych i powtarzalnych problemów
- Obiektowy interfejs – Dostajemy w pełni obiektowy interfejs, do procesowania naszych kolekcji danych. Koniec z posługiwaniem się brzydkimi funkcjami typu array_xyz().
Yield
Omówiliśmy sobie iteratory. Teraz czas na generatory. Aby to zrobić, musimy sobie omówić, czym jest yield.
Yield to słowo najważniejsze w PHP, które podobnie jak return służy do zwracania wartości z funkcji. To, co warto powiedzieć, o ile chodzi o różnice między tymi dwoma słowami kluczowymi to:
- Return zawsze kończy wykonanie funkcji.
- Yield pozwala nam na wielokrotne zwracanie wartości z tej samej funkcji, bez zakończenia jej wywołania.
Generator
Czas teraz na generator. Jest to funkcja, która pozwala na iterowanie po zbiorach danych. Jest to prosty sposób na implementację iteratora, ponieważ Generator jest Iteratorem. Stanowi on również wydajny sposób na iterowanie po elementach bez konieczności ładowania ich do pamięci.
W kontekście Generatora warto powiedzieć sobie jeszcze dwie rzeczy:
Funkcja generatora
Po pierwsze – wyróżniamy coś takiego jak funkcja generatora. Funkcją generatora, nazywamy funkcję, która zwraca wartść dzięki słowa kluczowego yield (użytego np. w ramach jakiejś iteracji) lub dzięki yield from (użytego np. na jakiejś kolekcji danych np. array).
Aby zacząć używać funkcji generatora wystarczy w danej funkcji użyć po prostu słowa kluczowego yield zamiast return.
Obiekt klasy Generator
Po drugie – wynikiem wspomnianej wcześniej funkcji generatora jest obiekt klasy Generator. Jest to wbudowana w PHP klasa, która implementuje już za nas Iterator interface. Warto wspomnieć również, iż jest to tzw. forward-only iterator. Oznacza to, iż naszego generatora możemy użyć jedynie raz w ramach iteracji. o ile chcemy go użyć ponownie – należy ponownie wywołać funkcję generatora.
Podsumowanie wiadomosći teoretycznych
Zanim przejdziemy dalej, chciałbym podsumować, to, co do tej pory sobie powiedzieliśmy. Spójrz na poniższy diagram:
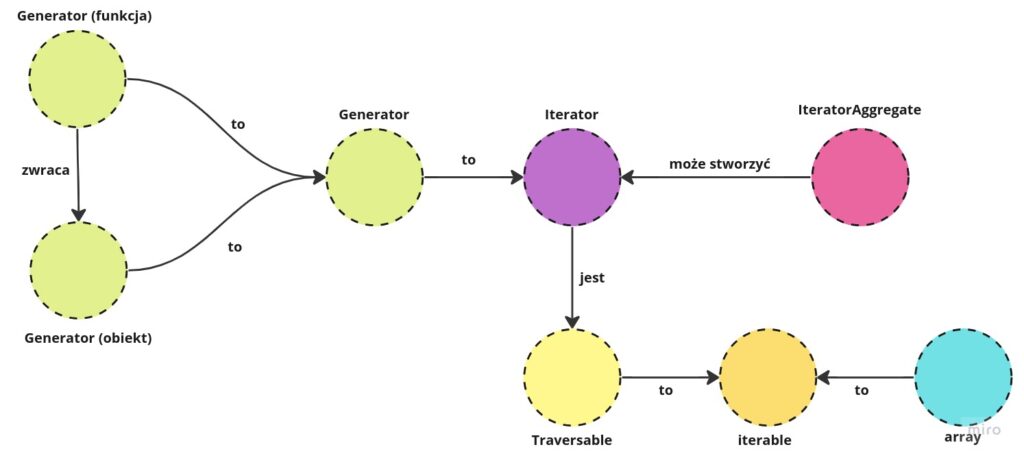 Diagram
Diagram- Wyróżniamy funkcję generatora, która zwraca wartości dzięki słowa kluczowego yield
- Funkcja generatora zwraca nam obiekt klasy Generator
- Tak się złożyło, iż zarówno funkcję generatora, jak i obiekt klasy Generator potocznie nazywamy Generatorem ¯\_( ツ )_/¯
- Generator to nic innego jak wbudowana w PHP implementacja Iteratora
- IteratorAggregate, to interfejs mający na celu stworzenie Iteratora. Wobec tego możemy równie dobrze stworzyć za jego pomocą Generator.
- Każdy iterator (a więc każdy generator) jest Traversable
- Zarówno Traversable, jak i array podpadają pod pseudo-typ iterable
Benchmarki
Jako bonus chciałbym Ci również pokazać benchmarki iteratorów, generatorów oraz arrayów. Aby to zrobić, stworzyłem kilka prostych implementacji, a następnie uruchomiłem je przy pomocy biblioteki phpbench, która pozwoliła mi w prosty sposób zmierzyć czasy wykonania oraz zużycia pamięci. Przekonajmy się zatem, które z tych rozwiązań jest bardziej optymalne.
Benchmark #1 – odczyt danych z pliku
Stworzyłem 4 implementacje odczytu z pliku. Plik, którego użyłem, to plik csv zawierający milion rekordów użytkowników. Niech wygra lepszy! ( ͡° ͜ʖ ͡° )
1. ArrayFileReader
Implementacja wygląda w sposób następujący:
Jest to klasyczna implementacja mechanizmu odczytu z pliku przy użyciu wbudowanych funkcji PHP. Każda linia z pliku jest ładowana do arraya. Następnie zwracamy tę tablicę i dokonujemy nadpisania na jednej z kolumn, w danym elemencie.
2. NaiveIteratorFileReader
Jak sama nazwa wskazuje, jest to „naiwna” implementacja naszego FileReadera.
Jak widzisz, robimy dokładnie to samo, co w poprzedniej implementacji. Różnica polega na tym, iż tablicę z liniami naszego pliku ładujemy sobie później do wbudowanego w PHP ArrayIteratora.
3. IteratorFileReader
Kolejną implementacją jest FileReader, który został napisany w nieco mniej naiwny sposób:
Jak możesz zauważyć, zaimplementowałem również swój własny Iterator. Wygląda on w sposób następujący:
To dosyc interesujący przykład. Warto zwrócić tutaj uwagę na to co dzieje się w metodzie next(). Przypisujemy tam do adekwatności current kolejną linię. Dzięki temu mechanizmowi nie będziemy zaśmiecać pamięci liniami, które nie są już nam potrzebne.
4. GeneratorFileReader
Na sam koniec zostaje nam implementacja FileReader’a przy użyciu generatora.
Jak widzisz, jest ona podobna do dwóch pierwszych implementacji. Różnica polega na tym, iż w pętli zwracamy kolejne linie przy pomocy słowa kluczowego yield.
FileReader Benchmark
Czas na wyniki! Przy pomocy biblioteki phpbench uruchomiłem każdą z implementacji po 5 razy. Powinno nam to dać nieco bardziej uśredniony rezultat. Rezultat prezentuje się następująco:
- ArrayFileReader – zużył aż 95.622 mb pamięci! To bardzo dużo. Całość zajęła niecałe 0.6 sekundy
- NaiveIteratorFileReader – zuzył 129.172 mb pamięci. Czyli jeszcze gorzej niż poprzednie rozwiązanie! Czas zakończenia zajął 0.68 sekundy
- IteratorFileReader – i tutaj ciekawostka! Zużycie pamięci to tylko 682.104 kb pamięci! To niesamowicie dobry wynik! Czas, jaki był potrzebny to 0.846 sekundy.
- GeneratorFileReader – i tutaj również niesamowicie niskie zużycie pamięci! Jedynie 682.104 kb zużytej pamięci. Cały proces potrzebował 0.696 sekundy.
Wnioski
Jakie wnioski możemy wyciągnąć z naszego benchmarku? Otóż rozwiązanie oparte o prostacką arrayką okazało się bardzo mało optymalne pod względem zużycia pamięci. Było ono jednak najbardziej optymalne pod względem wymaganego czasu. Nasza „naiwna” implementacja iteratora zeżarła najwięcej pamięci. Osiągnęliśmy jednak znakomity wynik naszym „mądrze” zaimplementowanym iteratorem. Zdecydowanie najlepiej poradził sobie generator, który nie tylko wymagał od nas małego nakładu pracy, o ile chodzi o implementację, ale dał nam niesamowity rezultat, o ile chodzi o zużycie pamięci, a także, o ile chodzi o czas.
Benchmark #2 – tworzenie wartości
Czas na kolejny benchmark. Tym razem postaramy się stworzyć w PHP liczby całkowite – od 0 do 1mln. W tym celu użyłem sobie iteratora oraz generatora.
1. IteratorValueCreator
Przyjrzyjmy się implementacji opratej na iteratorze:
Tym razem użyłem sobie IteratorAggregate. Wykorzystałem wbudowany w PHP ArrayIterator który przyjmuje od 0 do 1mln wartości stworzonych przy pomocy funkcji range.
2. GeneratorValueCreator
A teraz implementacja oparta na generatorze:
Do tego celu również użyłem IteratorAggregate. Jako iterator zwracam po prostu funkcję generatora, która yielduje wartości tworzone w ramach pętli for.
ValueCreator Benchmark
Widziałeś już implementacje. Niech wygra lepszy! Ponownie uruchomiłem procesy po 5 razy.
- GeneratorValueCreator – super wynik, o ile chodzi o pamięć! Zaledwie 682.104kb zużytej pamięci! Czas, jakiego potrzebował to 0.023 sekundy.
- IteratorValueCreator – nie powinno nas zaskoczyć, iż zużycie pamięci jest dużo gorsze – 34.121mb. Proces potrzebował 0.026 sekundy.
Wnioski
W przypadku tworzenia wartości generator poradził sobie zdecydowanie lepiej. o ile chodzi o nasz iterator, no cóż. Całą winę za ten wynik ponosi po prostu użycie funkcji range. Zapchała nam ona pamięć. Moglibyśmy oczywiście ponownie zaimplementować jakiś własny iterator, który będzie bardziej wydajny, o ile chodzi o zużycie pamięci, ale… nie oszukujmy się… komu chciałoby się implementować te 5 metod, skoro optymalne rozwiązanie mamy na wyciągnięcie ręki? ( ͡° ͜ʖ ͡° )
Czym różni się iterator od generatora?
Czym zatem różni się iterator od generatora? Aby odpowiedzieć na to pytanie, wybrałem sobie kilka kryteriów porównawczych:
- Narzut implementacyjny
- Iterator wymaga od nas spełnienia Iterator interface (5 metod do zaimplementowania).
- Generator wymaga od nas implementacji dużo mniejszej ilości kodu.
- Wielokrotne wykorzystanie
- Iterator może być wykorzystywany wielokrotnie.
- Generator jest tzw. forward-only iteratorem. Po przejściu do końca iteracji nie możemy go użyć jeszcze raz. Należy go wtedy zbudować po raz kolejny.
- Zużycie pamięci
- Poprawnie zaimplementowany Iterator może wykazać się podobnie niskim zużyciem pamięci co Generator. Obydwa te rozwiązania pod tym względem sprawdzają się dużo lepiej niż zwykły array.
- Jak już wspomniałem, Iterator może wykazać się niskim zużyciem pamięci, o ile trochę mu w tym „pomożemy” (tj. zaimplementujemy go w przemyślany sposób). Niestety, jest to niewspółmierny wysiłek, o ile chodzi o implementację. Dużo lepiej jest zwyczajnie użyć generatora.
- Czas
- Pod względem czasu Generator wypada nieco lepiej od Iteratora
Podsumowanie
Mam nadzieję, iż podobał Ci się dzisiejszy post. Omówiliśmy wiadomości teoretyczne na temat iteratorów i generatorów – nie powinny one już dla Ciebie posiadać żadnych tajemnic! Ponadto omówiliśmy także wyniki benchmarków, które jasno wskazały, co należy zrobić, aby zaadresować problemy natury optymalizacyjnej, które mogą się pojawić przy ciężkich iteracjach. Daj znać w komentarzu, jakie masz w temacie naszych dzisiejszych rozważań!
Bonus
Dnia 15.12.2022 miałem przyjemność wystąpić na konferencji PHPCircle 2022. W ramach prelekcji omówiłem temat iteratorów i generatorów, a także przeprowadziłem benchmarki na żywo. Treść tej prezentacji okrywa się z treścią dzisiejszego posta. o ile słuchanie i oglądanie jest dla Ciebie lepszą formą nauki niż, czytanie postów, to zachęcam Cię do obejrzenia!