W życiu każdego developera, natrafienie na projekt borykający się z długiem technicznym i źle napisanym kodem jest niemal nieuniknione. Takie projekty często stanowią spore wyzwanie i wymagają strategicznego podejścia do ich ratowania oraz przekształcenia w solidne i łatwe w utrzymywaniu systemy.
Artykuł poświęcony jest wyzwaniu, jakim jest radzenie sobie z legacy code i długiem technicznym, a także opisuje wnioski wyciągnięte z projektu, nad którym pracowaliśmy w Brainhubie. Jako inżynierowie systemu rozumiemy, iż praca z systemami legacy jest integralną częścią naszego zawodu — to podróż, która może być tak bardzo trudna, jak i niezwykle satysfakcjonująca.
Przeczytacie o projekcie z licznymi problemami długu technicznego, złożonych API, wieloma problemami wydajnościowymi i skalowalnościowymi. Wspólnie przeanalizujemy niektóre strategie, taktyki i praktyczne kroki, które podjęliśmy, aby tchnąć nowe życie w ten projekt, dbając jednocześnie o ciągłość w dostarczaniu wartości biznesowej.
Napotkane wyzwania
- Coupling: Backend, najważniejszy komponent naszej aplikacji, został zaimplementowany w zaledwie kilku ogromnych plikach źródłowych, z których każdy zawierał tysiące linii kodu. Na froncie nasza napisana w Angularze aplikacja zawierała olbrzymie komponenty, przeładowane złożoną logiką, której utrzymanie było ogromnym wyzwaniem.
- Pokrycie testami: W projekcie było mnóstwo problemów w obszarze testowania. Backend miał zaledwie jeden test jednostkowy, a frontend nie wyglądał o wiele lepiej — miał kilka testów jednostkowych, wnoszących znikomą wartość do jakości projektu.
- Brak odpowiedniego środowiska lokalnego: Brak dobrze zdefiniowanego lokalnego środowiska programistycznego, odizolowanego od innych komponentów systemu, był ogromnym problemem, przez co praca niezależnie od reszty systemu okazała się praktycznie niemożliwa.
- Brak observability, słabe CI/CD: W projekcie brakowało podstawowych narzędzi, które zapewniłyby odpowiedniej jakości wdrożenia. Nie było możliwości monitorowania zachowania systemu, brakowało również zautomatyzowanego procesu testowania zmian w systemie.
- Problem z dokumentacją: brak odpowiedniej dokumentacji w projekcie sprawił, iż odkrywanie systemu stało się ogromnym wyzwaniem, w większości przypadków zmuszając zespół do uciekania się do testów manualnych oraz reverse engineeringu.
Audyt techniczny: określenie problemów i ryzyka
Nasz projekt mierzył się z ogromną ilością problemów technicznych, ale najtrudniejszym zadaniem okazało się podjęcie adekwatnych decyzji dotyczących kierunku poprawy sytuacji.
Zaadresowanie wszystkich wymienionych w poprzedniej sekcji kwestii było niezwykle istotne, ale próba jednoczesnego rozwiązania ich wszystkich byłaby niemożliwa. Od czego więc zaczęliśmy i jak poruszaliśmy się po tym labiryncie wyzwań?
Naszym pierwszym krokiem było przeprowadzenie kompleksowego audytu technicznego projektu. Audyt nie polegał tylko na zidentyfikowaniu problemów technicznych — chodziło o pokazanie klientowi palących kwestii długu technicznego i uświadomienie go, na jak wiele obszarów dług techniczny ma wpływ.
Priorytetyzowanie i zwiększanie świadomości
Audyt techniczny pozwolił nam uwypuklić problemy i zagrożenia, wynikające z jakości odziedziczonego przez nas kodu. Uszeregowaliśmy te kwestie pod względem priorytetów i potencjalnego wpływu na powodzenie projektu. Co ważniejsze, wykorzystaliśmy ten audyt jako platformę do zaangażowania klienta w rozmowę na temat powagi sytuacji i długoterminowego utrzymywania wysokiego długu technicznego. Uświadomiliśmy go, iż nie była to tylko kwestia poprawy jakości kodu, ale niezbędna inwestycja w przyszłość projektu — mówiąc wprost, nie było nas stać na tak duży dług techniczny.
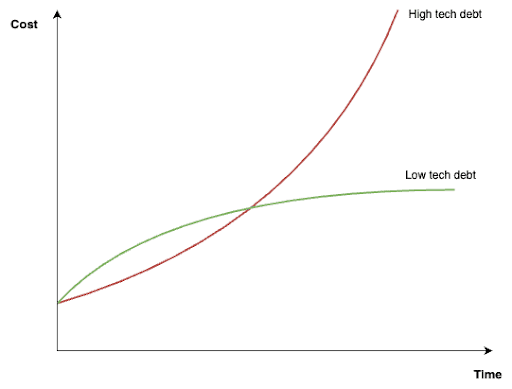
Trudno o roadmapę
Warto jednak zauważyć, iż choć audyt technologiczny był świetnym narzędziem do podniesienia świadomości, nie był rozwiązaniem samym w sobie. Problemy zidentyfikowane podczas audytu były zbyt szerokie, aby można je było bezpośrednio przekształcić w możliwe do wykonania taski lub epiki. Były one też często zbyt dalekie od priorytetów biznesowych, co utrudniało ich zaplanowanie.
Najważniejszy wniosek z tej fazy był jasny: audyt technologiczny posłużył jako najważniejszy katalizator zmian, ale nie zapewnił nam roadmapy, na której moglibyśmy się oprzeć w celu rozwiązania wymienionych problemów.
Rozwiązanie: dopasowanie problemów do celów biznesowych
Aby osiągnąć znaczący postęp, musieliśmy połączyć wspomniane wyzwania techniczne z rzeczywistą wartością biznesową. Długiem technicznym mogliśmy zająć się skutecznie tylko wtedy, kiedy dostosujemy nasze wysiłki do głównych celów biznesowych projektu, pamiętając jednocześnie o jego sztywnych deadline’ach.
Opracowanie strategii testów
Wszyscy zgadzamy się co do tego, iż każdy zdrowy projekt powinien mieć odpowiednie testy, na których może polegać. Jednym z kluczowych kroków podczas naszej misji ku poprawie jakości technicznej projektu był wybór odpowiedniej strategii do testowania, tak, abyśmy mogli spokojnie skupić się na dalszym rozwoju systemu jednocześnie nie martwiąc się o jego istniejące elementy.
Unit testy nie pomogą
Piramida testów podkreśla znaczenie solidnego fundamentu testów jednostkowych, a dalej testów integracyjnych i testów end-to-end. Jednak w omawianym konkretnie przykładzie ścisłe przestrzeganie zasad piramidy testów nie przyniosłoby oczekiwanych rezultatów — nasza baza kodu osiągnęła stan, w którym pisanie kompleksowych testów jednostkowych można porównać do nakładania świeżej warstwy farby na rozpadającą się ścianę. Zabetonowałoby to raczej istniejące problemy, zamiast je naprawić, a utrzymywanie takich testów stałoby się niezwykle kosztowne.
Rozwiązanie? Testing Trophy!
Zamiast tego przyjęliśmy alternatywne podejście, znane jako Testing Trophy, i zastosowaliśmy jego główny slogan:
Pisz testy. Nie za dużo. Głównie integracyjne.
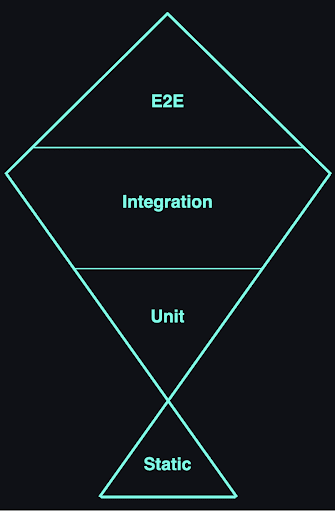
Nasze podejście było proste: skupić się na pokryciu głównego przepływu użytkowników końcowych.
Tworząc odpowiednie wysokopoziomowe testy przy użyciu Playwright (co uczyniło zadanie całkiem przyjemnym), koncentrując się przede wszystkim na E2E i testach integracyjnych, upewniliśmy się, iż każda wprowadzona przez nas zmiana jest zgodna z głównym celem naszej aplikacji.
Testy stały się strażnikami chroniącymi przed regresjami i nieoczekiwanymi zachowaniami, dały nam też bardzo wysoką wartość w stosunkowo krótkim czasie. Oczywiście, testy nie były ani najszybsze, ani doskonałe, ale czuliśmy się dzięki nim znacznie pewniej.
Refactoring: Cel ponad doskonałość
Gdy dzięki przeprowadzonym testom osiągnęliśmy już zapewniony pewien poziom bezpieczeństwa i pewności, mogliśmy zacząć myśleć o wprowadzeniu konkretnych zmian i usprawnień.
Mając do czynienia z kodem, którego jakość jest daleka od szeroko pojętych dobrych standardów, naturalnym jest odczuwanie chęci świeżego startu. Pomysł pozbycia się wszystkiego i zbudowania od zera może być kuszący, ale ostatecznie byłaby to bardzo wymagająca droga – refaktoryzacja zawsze wiąże się z ryzykiem i powinna być ściśle związana z określonymi celami biznesowymi.
Zazwyczaj przepisywanie systemu ma sens tylko wtedy, gdy jest jedyną opcją, jaka nam pozostała.
Powodem, dla którego przepisywanie jest tak ryzykowne w praktyce, jest to, iż proces zastąpienia jednego systemu innym zajmuje dużo czasu. Rzadko rozumiemy co robił poprzedni system – wiele jego adekwatności ma charakter przypadkowy, a same testy nie będą w stanie zagwarantować, iż ostatecznie nie wprowadziliśmy znaczących regresji.
Małymi krokami do celu!
Choć z inżynierskiego punktu widzenia może się to wydawać znacznie mniej atrakcyjnym i ekscytującym wyborem, możliwość usprawniania istniejącego i ciągle działającego systemu może w rzeczywistości wiązać się ze znacznie bardziej złożonymi i interesującymi wyzwaniami.
Nie wiesz gdzie zacząć? Pomyśl o celach biznesowych
Estetyka kodu to element kluczowy, ale nigdy nie powinien być jedynym motorem napędowym podczas prac nad refaktoryzacją. Zamiast tego, proces ten powinien przyjąć formę strategicznego działania, skierowanego na rozwiązanie konkretnych problemów lub osiągnięcie długofalowych korzyści.
Refaktoryzacja powinna mieć precyzyjnie zdefiniowany cel i zawsze wspierać biznes.
Cztery kroki do poznania obszarów do poprawy
Mając poprzednią regułę w pamięci, zidentyfikowaliśmy następujące punkty, które pomagały nam w skutecznej identyfikacji kolejnych obszarów do usprawnień w projekcie:
- Zwracaj uwagę na roadmapę – szukanie okazji do usprawnień i zmian powinno być silnie oparte o roadmapę projektu. Dzięki temu strategicznie dostosowujemy ulepszenia kodu do zmieniających się potrzeb i priorytetów biznesowych.
- Przeanalizuj błędy – być może są one ze sobą powiązane i pochodzą z tego samego obszaru w systemie. W takim przypadku warto rozważyć bardziej znaczące zmiany lub choćby stopniowe zastąpienie tej części systemu.
- Zdefiniuj najważniejsze części systemu – takie podejście zagwarantuje, iż wysiłki związane z refaktoryzacją będą skoncentrowane na obszarach, które najbardziej wpływają na realizację celów biznesowych.
- Komunikacja jest kluczowa – jasna i transparentna komunikacja w zespole stanowi fundament. Istotne jest wcześniejsze rozpoznawanie i dzielenie się wyzwaniami technicznymi, a także uwzględnianie ich w procesie planowania.
Studium przypadku: Przejdźmy do praktyki
Jak już wspomniano, napotkaliśmy na swojej drodze kilka wyzwań. Aby sprawnie poruszać się w tym labiryncie, przyjęliśmy metodyczne podejście, wykorzystując testowanie, refaktoryzację i staranne planowanie.
W tej części chciałbym się skupić na przykładzie naszego backendu, gdzie postanowiliśmy wprowadzić stopniową migrację z Express’a do Nest’a. Uważaliśmy, iż to dobry krok w stronę poprawy jakości kodu, wprowadzenia klarownych struktur i granic. Nest, będąc opartym na Expressie, oferuje bardziej zaawansowane narzędzia i szereg funkcji, które znacząco ułatwiają utrzymanie czytelności kodu, a dzięki modularnej architekturze, możliwe było dostawianie nowo napisanej warstwy aplikacji obok już istniejącej bez konieczności ingerencji w jej kod. Takie podejście pozwoliło na rozwój projektu w sposób bardziej skalowalny i zorganizowany, co było najważniejsze dla jego długoterminowego utrzymania i dalszego rozwoju. Cała konfiguracja z tym związana okazała się bardzo prosta i wymagała dodania zaledwie kilku linijek kodu:
Główny cel migracji
Framework miał być jedynie narzędziem wspierającym dalsze zmiany, a nasz główny cel i plan dalszej migracji uwzględniał następujące główne punkty:
Izolacja długu technicznego
Dzięki hermetyzacji legacy w ramach istniejącego systemu i stopniowemu dokładaniu nowej warstwy aplikacji obok istniejącej, skutecznie odizolowaliśmy starszy kod, zapobiegając zanieczyszczaniu nowej części systemu.
Wprowadzenie API v2
Wprowadziliśmy nową wersję naszego API, charakteryzującą się czystszą, bardziej intuicyjną strukturą, zaimplementowaną zgodnie ze specyfikacją, która została w pełni pokryta odpowiednimi testami. Pozwoliło nam to na dodanie nowych funkcji i usprawnień bez zmiany istniejącego API, jednocześnie stopniowo przenosząc klientów naszego API na jego nowszą wersję.
Dokumentowanie wymagań biznesowych
Aby uzyskać jasność i zgodność wśród zespołu oraz stakeholderów, zainwestowaliśmy czas w kompleksowe dokumentowanie wymagań biznesowych, tworząc szczegółową specyfikację, którą następnie wykorzystaliśmy jako podstawową strategię do developmentu i testów.
Stopniowe ulepszenia poprzez drobne zmiany
Jedną z podstawowych zasad naszego podejścia było unikanie dużych zmian. Zamiast tego zdecydowaliśmy się na małe, łatwe w kontrolowaniu kroki, które można było płynnie zintegrować z naszymi bieżącymi zadaniami biznesowymi.
Takie podejście dawało nam pewność, iż mierzymy siły na zamiary, i pozwoliło nam ulepszać kolejne rzeczy przy jednoczesnym niezależnym i ciągłym dostarczaniu nowych funkcjonalności.
Przykład: Zmiany w procesie rejestracji użytkowników
Powiedzieliśmy już sporo na temat teorii, przyjrzyjmy się teraz więc praktycznemu przykładowi.
W pewnym momencie zostaliśmy poproszeni o dodanie funkcji wysyłania e-maili dotyczących weryfikacji konta w ramach procesu rejestracji użytkownika.
Istniejąca w systemie logika rejestracji stała się z czasem bardzo złożonym fragmentem kodu, składającym się z wielu interakcji z bazą danych, uwierzytelnianiem i nie tylko – a wszystko to w setkach linii kodu.
Aby poradzić sobie z tym wyzwaniem, moglibyśmy zaimplementować wspomnianą funkcjonalność w nowy, Nestowy sposób, ale najtrudniejszą częścią byłoby zintegrowanie jej z istniejącym endpointem po stronie legacy.
Kolejnym rozwiązaniem mogłoby być przepisanie wspomnianego endpointa, co rozwiązałoby wszystkie powyższe problemy, ale jednocześnie wprowadziłoby ogromne ryzyko i wymagałoby od nas włożenia dużego nakładu pracy związanym z przepisaniem istniejącej funkcjonalności, i to zanim jeszcze choćby będziemy mogli zająć się głównym celem zadania.
Aby tego uniknąć, zdecydowaliśmy się na wprowadzenie podejścia opartego na zdarzeniach (Broker Topology).
Przy zastosowaniu Broker Topology, komunikacja między modułami odbywa się poprzez wysyłanie zdarzeń do scentralizowanego brokera (magistrali), a wszyscy subskrybenci brokera odbierają i przetwarzają zdarzenia asynchronicznie.
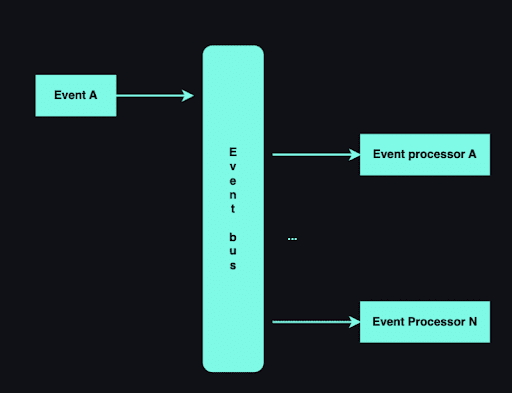
W tym podejściu za każdym razem, gdy magistrala zdarzeń otrzymuje zdarzenie od twórców producentów, jest odpowiedzialna za przekazanie ich do wszystkich subskrybentów, którzy mogą następnie przetwarzać dane dzięki własnej logiki. W tym przypadku jedyną zależnością zarówno wydawców, jak i subskrybentów jest magistrala zdarzeń, co znacznie zmniejsza coupling.
Poniższy fragment kodu ilustruje implementację funkcjonalności opartej na zdarzeniach, dzięki której jedyna zmiana, która została wykonana po stronie legacy, polegała na powiadomieniu magistrali zdarzeń o rejestracji nowego użytkownika:

Tak wygenerowane zdarzenie może następnie być obsługiwane przez wszystkich zainteresowanych nim subskrybentów, między innymi przez wspomniany wcześniej nowy moduł, odpowiedzialny za weryfikację kont użytkowników:
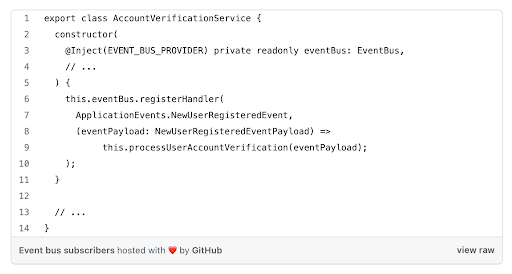
Wykorzystując magistralę zdarzeń i modularność, osiągnęliśmy nasz cel, jakim było dodawanie kolejnych funkcjonalności systemu w stopniowy sposób, przy jednoczesnym minimalizowaniu ingerencji w istniejącym systemie.
Dług techniczny – podsumowanie
Radzenie sobie z długiem technicznym może być wyzwaniem i długą drogą, która wymaga cierpliwości i strategicznego myślenia.
Po około dziesięciu miesiącach pracy przekształciliśmy opisywaną bazę kodu z 0% do około 50% code coverage, zmigrowaliśmy większość kodu do odizolowanych i niezależnych modułów oraz znacząco poprawiliśmy wiele problemów wydajnościowych.
Po tym czasie i efektach zaczęliśmy również zauważać znaczący wzrost wydajności zespołu oraz dostarczania zmian – mając odpowiednią dokumentację, strukturę, testy i narzędzia czuliśmy się o wiele pewniej w dostarczaniu kolejnych funkcjonalności.
Co więcej, z powodzeniem wdrożyliśmy testy integracyjne i end-to-end, zapewniające stabilność rozwiązania, pozostając wystarczająco elastycznym w dodawaniu nowych funkcjonalności i dostosowując się do zmiennych wymagań biznesowych.
Przed nami jeszcze wiele pracy, ale projekt jest już w zupełnie innym miejscu, gotowy do dalszego rozwoju.
Zdjęcie główne pochodzi z Unsplash.com.








