Internet jest ogromny. Do tego stopnia, iż można go nieironicznie uznać za wirtualny świat – choćby jeżeli weźmiemy pod uwagę tylko najzwyklejsze, codziennie odwiedzane strony. I pominiemy obiecywane nam cukierkowe metawersa.
A ponieważ jest stworzony przez ludzi, wiele jego aspektów jest odbiciem realnego społeczeństwa. Strony mogą być jak prywatne domy kolekcjonerów-hobbystów. Kluby pasjonatów. Tandetne galerie handlowe, zoptymalizowane pod napędzanie konsumpcji.
No i boczne alejki, gdzie po zapukaniu do drzwi i podaniu tajnego hasła można zamówić rzeczy sprzeczne z prawem. A czasem choćby z etyką.
W mediach ten ostatni rodzaj miejsc nazywa się często darknetem. „Ciemna strona internetu, pełna przestępców i zła, do której mogą wejść tylko użytkownicy Tora” (The Onion Router; przeglądarka anonimizująca).
Problem w tym, iż ta wizja miesza pojęcia techniczne z kwestiami etycznymi. I uderza w przeglądarkę, która sama w sobie jest narzędziem neutralnym i przydatnym. I fajnym.
W tym wpisie obalę parę medialnych mitów i po ludzku omówię, czym są te różne dziwne nety. Zobaczymy, iż podział jest umowny, a najciemniej bywa pod latarnią.
![]()
 Nim zaczniemy
Nim zaczniemy
Uprzedzam, iż to nie przewodnik po działaniu Tora. Na to jeszcze przyjdzie czas, kiedy sam się douczę :wink:
Skupiam się tu na wyjaśnianiu pojęć clearnetu, deepnetu i darknetu, zaś o cebulowym routerku będzie tylko ogólnikowo.
Spis treści
- Medialne mity
- Najciemniej pod latarnią?
- Skutki demonizowania
- Clearnet
- Deepnet
- Plik robots.txt
- Deepnetujemy swój profil
- Deepnet a logowanie
- Darknet
- Tor Browser
- Strony typu Onion
- Jasne strony darknetu
- „Wszyscy siedzimy w darknecie”
- Podsumowanie
Medialne mity
Jako przykład medialnego mieszania pojęć przedstawiam artykuł fundacji Orange, „Czym jest Darknet, dark web oraz deep web? Jak chronić dziecko przed ciemną stroną internetu?”.
Zarówno Deep web, jak i Dark web to sieci niedostępne dla wszystkich użytkowników, ani dzięki standardowych przeglądarek internetowych. (…)
Deep web zwykle jest używany do legalnych działań, które wymagają anonimowości w sieci, natomiast Dark web jest często wykorzystywany do nielegalnych celów.
Znajdziemy tu dwa przekręcone fakty.
Pierwszym jest pisanie, iż deepnet jest niedostępny dzięki zwykłych przeglądarek. Drugim – wiązanie go z anonimowością.
Jak zobaczymy, deepnet to znaczna większość internetu. Jest czymś całkiem powszechnym. I nie ma w nim nic tajemniczego.
Nawet w artykule ze strony ICANN – organizacji zajmującej się domenami internetowymi – znajdziemy wymieszanie pojęć.
W zakładce na temat darknetu napisali tylko parę zdań. Zaś druga, znacznie większa zakładka o deepnecie wspomina o zagadnieniach, które lepiej by chyba pasowały do tej pierwszej.
Some Deep Websites are unconventional marketplaces that offer a disturbing range of products or services (…) You can also use the Deep Web to anonymously share information
Pomijając mijanie się z definicją, oba źródła robią też coś, co mi osobiście nie leży. Łączenie pojęć z kwestiami legalności, jakby to było oczywiste. A tymczasem deepnet i darknet to pojęcia związane z techniką, a nie legalnością czy moralnością.
To trochę jak z kompasami politycznymi – jedna oś prawo-lewo to za mało, żeby rzetelnie przedstawić sprawę. Przydadzą się co najmniej dwie. Jedna od spraw technicznych, całkiem osobna od legalności.
Jak najbardziej istnieją takie rzeczy jak prywatnościowy darknet „w służbie dobra”. Albo przestępstwa w publicznym, mainstreamowym internecie. Zaryzykowałbym choćby stwierdzenie, iż te drugie są całkiem częste.
Najciemniej pod latarnią?
Na temat darknetu powstała niejedna miejska legenda. Że są tam nagrania morderstw na żywo. Że można wynająć zabójców.
A przecież nagrania okrutnych morderstw łatwo znaleźć w całkiem zwykłej, publicznej części internetu. Zbrodnia na żywo od niejakiego Luki M. została wrzucona na stronę niszową, ale dostępną przez zwykłą przeglądarkę. Łatwo też trafić np. na wyczyn maniaków z Dniepropietrowska.
Wiele nagrań z wypadków lub egzekucji było dostępnych na Rotten albo Liveleaku – już niedziałających, ale wcześniej hulających przez kilkanaście lat. Publicznie dostępnych.
Wynajęcie zabójców przez darknet? choćby jeżeli takie ogłoszenie się trafi, to często będzie zwykłą próbą naciągnięcia zdesperowanych ludzi na kasę. Co ma sens – w końcu raczej nie zgłoszą takiego oszustwa na policję :wink:
Niszczenie ludzi znajdziemy natomiast w całkiem publicznej sieci. W USA w niektórych kręgach propaguje się swatting – ustalali czyjś adres, dzwonili na policję i informowali, iż pod tym adresem uzbrojony napastnik wziął zakładników. Amerykańscy gieroje wpadali z bronią. W paru przypadkach doprowadziło to do śmierci niewinnych ludzi.
Wszystkie powyższe rzeczy, i wiele innych, to jak najbardziej mroczne sprawy. Ale nie darknetowe.
Gdyby pokazać w liczbach bezwzględnych, ile brudu tkwi w poszczególnych warstwach internetu, to podejrzewam iż najwięcej byłoby go w publicznie dostępnej części. Chociażby przez to, iż jest znacznie większa.
Skutki demonizowania
Mieszając ideę anonimowego przeglądania z przestępstwami, media robią jej zły PR. Rykoszetem mogą obrywać niewinne rzeczy. Jak przeglądarka Tor Browser albo samo słowo darknet.
Czas na parę sekund besztania Google’a, bowiem miała u nich miejsce pewna dziwna sytuacja. Pewnego dnia nagle i nieodwołalnie zamknęli grupę dyskusyjną o nazwie Darknet, założoną w jednym z ich serwisów, Google Groups.
Problem? Nie była to grupa o otchłaniach internetu – dotyczyła jedynie zestawu programów do uczenia maszynowego, mającego tę niefortunną nazwę. Która wzięła się stąd, iż była wariacją na temat ConvNets, pewnej ogólnej metody.
Dla formalności dodam, iż nie wiem, czy blokada nastąpiła przez samą nazwę. Mogło być też tak, iż nazwa skusiła jakiegoś trolla, ten podrzucił na grupkę nielegalne materiały, Google ją zamknął.
Ale, niezależnie od przyczyny, szkoda została wyrządzona, cenne dyskusje przepadły.
Ale uznajmy, iż to naciągany przykład. Dlatego mam kolejny – nie tak dawną dyskusję na Reddicie o tym, iż ktoś został zwolniony za jednorazowe połączenie z siecią Tor. Może choćby przypadkowe.
Osoba ta używała przeglądarki Brave, która posiada opcję oglądania stron w trybie anonimowym, przez protokół Tor. Włącza się ją kombinacją klawiszy Alt+Shift+N.
A z punktu widzenia mało ogarniętych menedżerów było to chodzenie po ciemnych zakamarkach internetu, tam gdzie są przestępcy. A zatem pospiesznie zwolnili winowajcę (obstawiam, iż historia działa się w USA, gdzie pracownicy są wymiennym mięsem).
Pamiętajmy, iż to Reddit, ludzie mogą wrzucać zmyślone historyjki. Ale, czytając komentarze, znajdziemy całkiem realne przykłady krótkowzroczności menedżerów. choćby gdyby ta konkretna historia się nie wydarzyła, to jest całkiem możliwe, iż kogoś dotknie.
Tak to może być, kiedy ludzie decydujący o innych uwierzą w medialne bzdurki. Żeby nie być jak oni i wiedzieć coś o świecie, omówmy sobie po ludzku różne warstwy naszego internetu.
Clearnet
Pierwsze oblicze internetu. To najzwyklejsze strony, które możemy znaleźć w wyszukiwarce, odwiedzić, poczytać.
Wpisujemy w DuckDuckGo (albo choćby wścibskiego Google’a!) słowa carbonara przepis i wyskoczą nam wszelkiej maści blogi z przepisami kulinarnymi. Wpiszemy coś innego, jak szkolny wielki brat, to może wyskoczy Ciemna Strona. Bez przepisów.
A jednak, choć clearnet jest codziennością, pojęcie to widuję w mediach rzadziej niż deepnet czy darknet. Dlaczego?
Moja nieco cyniczna interpretacja – dlatego, iż w codzienności nie ma sensacji. Bardziej klikalne jest to, co związane ze zbrodniami, sprawami łóżkowymi, albo chociaż jakąś tajemniczością. Clearnet to proza życia, więc nie budzi zainteresowania.
W każdym razie, według definicji, clearnet to te strony internetowe, które są indeksowane przez wyszukiwarki.
A czym jest indeksowanie?
Mam tutaj analogię botaniczną – botanik znajduje nową, jeszcze nieopisaną roślinę. Żeby ją opisać, przyjmuje jakiś umowny klucz. Kwitnie czy nie? Jakie ma liście? W jakim rośnie klimacie?
Stopniowo uzupełnia informacje i dorzuca je do wielkiego światowego katalogu. A efekt końcowy jest taki, iż inni ludzie będą mogli zajrzeć do indeksu roślin i znaleźć nówkę pod hasłem kwiaty łąkowe Europy.
Indeks przeglądarkowy jest pod tym względem podobny. Tylko iż zamiast botanika mamy programy zwane crawlerami. Odwiedzają strony internetowe. Analizują ich tekst, obrazki, wydajność, powiązania z innymi stronami. Zapisują to, według przyjętego klucza, do swojej wewnętrznej bazy.
A efekt końcowy jest taki, iż niektóre stronki będą nam wyskakiwały na liście wyników po wpisaniu hasła carbonara przepis.
Ciekawostka
Niedawno miał miejsce wyciek danych firmy Yandex, odpowiedzialnej za jedną z bardziej znanych wyszukiwarek. Dzięki temu zyskaliśmy możliwość zerknięcia za kulisy, sprawdzenia jakim „kluczem” przy doborze treści się kierują. jeżeli kogoś interesuje temat, to można poczytać dyskusje.
Deepnet
W tym miejscu porzucę analogię botaniczną, bo nie do końca pasuje – nie ma na przykład opcji, żeby roślina nie zgodziła się na wpisanie jej do atlasu!
Niektórzy przypisują deepnetowi jakieś ciemne sprawki albo anonimizację. Ale mocno mijają się z techniczną definicją – bo według niej deepnet to ta część internetu, która nie jest indeksowana. I tyle, definicja nic nie mówi o zawartości stron.
Samo indeksowanie opisałem wyżej, porównując je do botanicznej klasyfikacji. Ale dlaczego niektóre strony nie są indeksowane? Przykładowe przyczyny:
-
Strona jest na czarnej liście wyszukiwarki.
Być może poprzedni właściciel próbował budować reputację na sztucznym ruchu i dostał karę. A nowy, po odkupieniu domeny, przez cały czas tej karze podlega.
Warto zaznaczyć, iż każda wyszukiwarka może podchodzić do tematu po swojemu. Jak najbardziej może się zdarzyć, iż ktoś jest w niełasce u Google’a, ale DuckDuckGo już by takową stronę wyszukało.
- Boty od wyszukiwarki jeszcze nie odkryły nowej strony.
- Właściciele strony proszą o to, żeby jej nie indeksować.
Ostatni punkt wyjaśnijmy sobie nieco dokładniej. Istnieje pewien umowny sposób, w jaki strony mogą wyrażać niechęć do ich indeksowania. Jest nim wpisanie odpowiednich rzeczy do pliku tekstowego nazwanego robots.txt, umieszczonego na tym samym serwerze co plik ze stroną.
Plik robots.txt
Wiele odwiedzanych przez nas stron ma coś takiego, zresztą sami możemy sprawdzić! W tym celu odwiedzamy interesującą nas stronę, patrzymy na nazwę jej domeny (czyli to, co przeglądarki często wyróżniają w pasku ciemnym kolorem). A następnie usuwamy wszystko, co po tej nazwie i dopisujemy po ukośniku robots.txt:

Jeśli strona ma taki plik, to zobaczymy jego zawartość. Znajdziemy w nim zestaw instrukcji w określonym formacie, przeznaczonych dla botów indeksujących.
To coś w rodzaju regulaminu na placu zabaw. Mówią na przykład, iż dana strona sobie nie życzy, żeby przeszukiwały je crawlery, których „wizytówka” zawiera tekst Google. Albo iż wszystkie crawlery powinny zignorować niektóre podstrony.
Czasem trafiają tam również komentarze od autorów stron, wyjaśniające dlaczego zbanowali niektóre boty. Przykładem choćby nasza Wikipedia.
Ciekawostka
Czasem pliki robots.txt mogą być całkiem ciekawe. Niektórzy umieszczają w nich smaczki dla zainteresowanych, przemyślenia, oferty pracy… A choćby grafikę. Tylko iż siłą rzeczy w formie samego tekstu, jako ASCII Art. Przykład znajdziemy na końcu instrukcji z nike.com.
Kiedy stronę odwiedza grzeczny bot, to w pierwszej kolejności zagląda do robots.txt. Odczytuje, co mu wolno. jeżeli natrafi na polecenie „nie indeksuj mnie”, to odpuszcza. Strona nie jest indeksowana, czyli trafia do deepnetu.
Oczywiście mogą istnieć boty niegrzeczne, które po prostu oleją takie instrukcje.
Widzimy zatem, iż pojęcie deepnetu jest względne. Stronka może zabraniać indeksowania niektórym serwisom, ale pozwalać na nie innym.
Mamy też potwierdzenie, iż słowa z artykułu Orange, który cytowałem na początku – iż deepnet nie jest dostępny z użyciem zwykłej przeglądarki (Firefoksa, Chrome’a itp.) – są nieprawdziwe.
Do deepnetu może należeć najzwyklejsza, prosta strona. Ktoś podrzuca link do niej, klikamy, normalnie się ładuje. Jej „deepnetowość” polega wyłącznie na tym, iż na własną prośbę nie pojawi się w wyszukiwarkach.
Deepnetujemy swój profil
Jeśli masz konto na Facebooku, czytelniczko lub czytelniku, to też możesz łatwo przepchnąć swój profil do deepnetu!
W tym celu wchodzisz w ustawienia konta, klikając swoje zdjęcie profilowe w prawym górnym rogu (mówię tu o wersji na komputery). Następnie wybierasz Ustawienia i prywatność, potem Ustawienia, potem Prywatność. Na koniec zaznaczasz opcję mówiącą o tym, żeby nie indeksowało Twojego konta w znanych wyszukiwarkach.
Instrukcje mogą się zmienić, gdyby Facebook zmienił kiedyś swoją stronę – zaczerpnąłem je z oficjalnej stronki.
A czy takie ukrycie ma jakiś sens?
Moim zdaniem tak! Zapewnia odrobinę ochrony przed mniej subtelnymi stalkerami – takimi, którzy potrafią co najwyżej wpisać twoje imię i nazwisko w Google, a następnie patrzeć, czy wyskoczyło coś związanego z mediami społecznościowymi.
Porada
Ale uwaga! Gdyby wpisali nasze imię i nazwisko w wewnętrzną wyszukiwarkę Facebooka, to już by znaleźli profil. Osoby chcące lepiej się ukryć powinny pokusić się również o zmianę nazwy konta. A także prowadzącego do niego linku; on również zawiera czasem imię i nazwisko).
Nieprawdziwa nazwa była kiedyś wbrew regulaminowi platformy, i może przez cały czas jest... Ale w najgorszym wypadku byłby ban konta, czyli też nic strasznego.
Deepnet a logowanie
Do deepnetu przyjęło się zaliczać nie tylko strony publicznie dostępne, które zabraniają się indeksować. To również wszelkie stronki wymagające logowania. Nasze konta bankowe, grupy na mediach społecznościowych, niejedno forum. Patrząc w ten sposób, deepnet byłby zdecydowanie największą częścią współczesnego internetu.
Ale w tym miejscu nasza definicja – do tej pory wyraźnie rozdzielająca dwa rodzaje stron – moim zdaniem nieco się rozmywa. Mamy przypadki, kiedy strona jak najbardziej jest dostępna w wyszukiwarce, a więc indeksowana, ale stoi w rozkroku między światami. Przykładem wspomniany wyżej Facebook.
Strona facebook.com jak najbardziej jest widoczna w wyszukiwarce.
Ale jeżeli ją odwiedzimy bez odpowiednich plików cookies, wskazujących kim jesteśmy, to zobaczymy jedynie prośbę o login i hasło. Dopiero po zalogowaniu pokaże się coś więcej.
Do czego zatem należy strona główna Facebooka? Clearnetu czy deepnetu?
Sprawa sięga zresztą nieco głębiej! Możemy być na Facebooku, ale przez cały czas nie widzieć niektórych treści (jak posty na grupach, do których nie należymy; zdjęcia na profilach osób, których nie mamy w znajomych). Tak jakby istniał osobny, wewnętrzny clearnet i deepnet Facebooka.
Z kolei wiele stron portalu Github wygląda bardzo podobnie dla osób zalogowanych i niezalogowanych; jedyną różnicą u zalogowanych bywa górny pasek z nazwą konta i paroma opcjami. Czy to wystarczy, żeby zaliczyć cały portal do deepnetu?
Dalszą polemikę zostawię sobie na koniec wpisu. Chciałem tylko pokazać, iż w świecie cyfrowym granice bywają płynne.
Na razie możemy sobie przyjąć taki podział: clearnet to strony, które są jednocześnie widoczne w wyszukiwarkach i zawierają coś więcej niż ekran logowania. Deepnet to wszystkie pozostałe.
Teraz pozostaje nam jeszcze darknet, czyli pewna konkretna część deepnetu.
Darknet
Nazwa brzmi nieco groźnie, nieprawdaż? Dark może po angielsku oznaczać mroczny, co kojarzy się z tymi medialnymi opowieściami o złoczyńcach i czarnych rynkach.
A tymczasem prawda jest dość prozaiczna. Poczynając od nazwy. Pojęcie darknet
istniało już w latach 70. i odnosiło się do tych serwerów, które były częścią sieci, ale nie odpowiadały na zapytania, nie wchodziły w interakcje.
Dark oznacza nie tylko mrok w sensie negatywnym. Ale również zwyczajną ciemność, taką jak po wyłączeniu światła. Nieaktywność.
Od tego czasu definicja nieco się zmieniła i oznacza teraz strony wymagające specjalnej konfiguracji albo korzystania z osobnych protokołów, żeby się do nich dostać. Po ludzku – nie da się tak po prostu wziąć ich adresu i go wkleić w pierwszą lepszą przeglądarkę.
Choć brzmi to bardzo restrykcyjnie, moim zdaniem pod darknet dałoby się podciągnąć zadziwiająco wiele rzeczy. Pod koniec wpisu pokażę parę przykładów do przemyślenia. Ale w mediach utarło się, iż darknet równa się Tor:
It’s strange how they always identify "Darknet" as Tor. There are other darknets like SIPRnet, JWICS, etc, and basically anything non-government groups want to spin up for their own purposes.
Tym razem nie będę szedł pod prąd i też użyję Tora w roli przykładu. Ale pamiętajmy, iż tak naprawdę darknetów może być wiele.
Tor Browser
Zacznijmy od ważnej rzeczy – kiedy jedna osoba pisze drugiej „użyj Tora”, to w praktyce zwykle ma na myśli przeglądarkę Tor Browser.
Ale Tor to coś ogólniejszego niż Tor Browser. To protokół, metoda działania. jeżeli porównamy protokół Tora z typowym internetem:
-
Nasz typowy internet stawia na szybkość. Przesyłane dane pokonują jak najkrótszą odległość.
-
Tor stawia na anonimowość. Wysyłane dane przechodzą przez kilka „węzłów przesiadkowych” w różnych krajach. W ten sposób trudniej wyśledzić, kto je wysłał.
Ten protokół jest publicznie dostępny, więc mogą z niego korzystać dowolne programy. choćby mieliśmy wcześniej przykład, kiedy jeden pracownik przejechał się na wersji umieszczonej w przeglądarce Brave.
Twórcy Tora połączyli go z otwartym kodem Firefoksa… I tak powstał Chocapic Tor Browser, przeglądarka internetowa.
Powiązane wpisy
O tej przeglądarce wspominałem już w paru wpisach, pokazując jak można jej użyć do ominięcia geofencingu (np. niewpuszczania europejskich adresów IP) albo niektórych blokad stron internetowych.
Była to tylko część jego możliwości; również ten wpis nie pokaże ich w całości, ale tylko dołoży do układanki parę faktów.
Tor Browsera można używać jak najzwyklejszej przeglądarki i chodzić po stronach całkowicie clearnetowych. Jedyna różnica polega na tym, iż Wasz prawdziwy adres IP jest ukryty przed oczami odwiedzanych stron, do tego działa parę bajerów chroniących prywatność. No i iż przy każdym połączeniu „skaczecie” najpierw po świecie, przez co przeglądanie jest nieco wolniejsze.
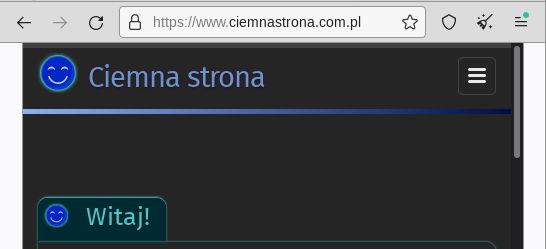
Mój skromny blog oglądany przez Tora.
Ciekawostka: pusta przestrzeń po bokach to zabezpieczenie przed identyfikacją po rozmiarze okna.
Strony typu Onion
Jeśli ktoś chce – i tylko wtedy, bo nic na siłę – to może odwiedzić przez Tora również inny, specjalny rodzaj stron, zwanych onion services (dawniej: hidden services). To właśnie je media utożsamiają z darknetem.
Spójrzmy tutaj na przykład – opis ich działania na stronie głównej projektu Tor. Tu jego publicznie dostępny, clearnetowy adres:
Kolorem czerwonym wyróżniłem nazwę domeny.
Możemy go sobie zaznaczyć i wkleić w pasek popularnej przeglądarki. Strona normalnie nam się załaduje, o ile nasz dostawca internetu jej nie blokuje.
Ale jeżeli używamy Tor Browsera, to ten rozpozna, iż stronka ma również wersję „cebulową”. W rogu wyświetli nam się napis .onion available.
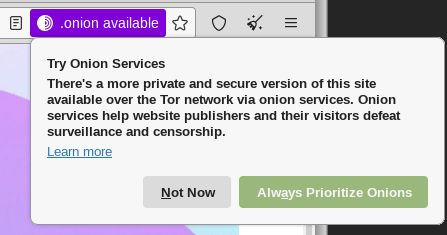
Możemy go kliknąć, żeby przejść na ukrytą wersję strony. Wygląd ten sam, adres inny:
Gdybyśmy go wkleili do jakiejś mainstreamowej przeglądarki, nieznającej protokołu Tor, to byłaby lipa. Wyskoczyłby komunikat, iż strona jest nieznana.
Ciekawostka
Wnikliwi zauważą, iż adres zaczyna się od http, bez s na końcu.
Ktoś mógłby się przestraszyć, bo w końcu w normalnym przypadku oznaczałoby to brak szyfrowanego połączenia. Każdy podglądacz by widział, jakie dane wymieniamy ze stroną.
Ale na szczęście nie jest tak źle! Połączenie z cebulowymi stronami jest szyfrowane w inny sposób, dzięki protokołowi Tora.
I to tyle! Tak właśnie wygląda darknet związany z Torem. Stronki kończące się na .onion, które załadują się (prawie) wyłącznie w przeglądarce Tor Browser. Kiedy się z nimi łączymy, to nasza prawdziwa tożsamość jest mocno chroniona.
Ich zresztą też – cebulowe stronki to rozwiązanie chroniące „tożsamość” stron internetowych, ich adres IP. Agresorom jest bardzo trudno je znaleźć i ubić.
Jasne strony darknetu
A co można znaleźć w tym cebulowym darknecie? Pominę tu rzeczy mniej legalne, bo nie chcę być częścią medialnego szumu. Zamiast tego spójrzmy na przykłady, kiedy z dobrodziejstw anonimowej sieci skorzystali gracze znani lub dobrzy.
-
W 2014 roku zespół Aphex Twin opublikował informacje o nowej płycie właśnie na cebulowej stronce.
-
Na bazie Tora działa SecureDrop, dający możliwość anonimowego przesyłania informacji różnym organizacjom medialnym.
To sensowne rozwiązanie dla osób chcących np. ujawnić lokalną korupcję. Korzystanie z publicznej sieci byłoby groźne, bo złoczyńcy mogliby podpytać znajomków z firmy telekomunikacyjnej o personalia samotnych bohaterów. Tor częściowo przed tym chroni (acz nie całkiem, bo telekomy zwykle widzą sam fakt, iż coś w nim robiliśmy).
-
Swój adres .onion ma Facebook, od 2014 roku.
Może to początkowo dziwić, patrząc na to iż Facebook słynie ze zbierania danych.
Ale po chwili zastanowienia wcale na tym nie tracą. Kiedy jesteśmy zalogowani na swoje konto, to Fejs i tak widzi naszą aktywność, nie ma na to rady.A do tego zyskuje szersze grono użytkowników – ludzi ceniących prywatność oraz takich, których kraj blokuje Facebooka (Tor, jako pośrednik sieciowy, pozwala ominąć blokady stron).
-
Ma go również Twitter.
Motywacja pewnie jak wyżej. Po ostatnich zmianach kadrowych ktoś nie dopilnował sprawy i cebulkowa wersja przestała działać przez nieodnowienie certyfikatu na czas.
Wcześniej widzieliśmy, iż w clearnecie może być pełno mroku, a rzeczy ukryte są największą częścią internetu. Do burzenia światopoglądu doliczmy sobie teraz fakt, iż mamy niemało dobra w anonimowym darknecie :wink:
„Wszyscy siedzimy w darknecie”
Ta część to już moje subiektywne przemyślenia i kwestionowanie definicji.
Jeśli dobrze rozumiem definicję, darknet jest podzbiorem deepnetu, a więc z założenia wyklucza się z clearnetem.
Ale na chwilę odejdźmy od ścisłej definicji. Intuicyjnie na darknet można patrzeć tak: „to strony, które ci się nie załadują, jeżeli nie używasz czegoś nietypowego”.
A do takiego opisu pasowałoby moim zdaniem zadziwiająco wiele rzeczy, bo strony internetowe lubią rozgraniczać. Przykłady?
-
Wersje stron przeznaczone dla crawlerów.
Automaty dostają czasem inne treści niż użytkownicy zwykłych przeglądarek. A są czymś absolutnie powszechnym – według nowych danych stanowią przeciętnie choćby 40% całego ruchu w internecie
Mają specjalną konfigurację, widzą inny internet niż my. Czasem są większością w internecie. Czy w takich warunkach nie dałoby się przewrotnie stwierdzić, iż to my, ludzie, mamy swój mniejszościowy darknet? -
Blokowanie adresów IP z wybranych krajów.
Stosowane choćby przez stronki z USA, które nie lubią europejskich przepisów dotyczących ochrony danych.
Dla wielu osób zmiana adresu IP może być niemożliwa, więc nie zobaczą strony. A niektórzy zrobią specjalną konfigurację, jak włączenie VPN-a, i ją ujrzą.
Czy takie stronki nie są swego rodzaju darknetem?
Rzeczy ukryte na widoku
Co więcej, może się choćby zdarzyć, iż strona pokazuje całkiem inną treść osobom znającym odpowiednik tajnego hasła.
Przykładem jest odwiedzenie strony, gdy mamy w linku parametry o specjalnym znaczeniu.
Wyjaśnienie
Ogólnie: parametry to tekst rozpoczynający się od znaku zapytania, który można dodać na końcu linku do strony.
Często (nie zawsze) parametry nie mają wpływu na sam link i odwiedzana strona normalnie się bez nich załaduje. Ale jeżeli są, to właściciel strony może na nie zerknąć. I na tej podstawie zachować się wobec nas inaczej niż wobec innych.
Poniżej masz parametr, który możesz stąd skopiować i wkleić w pasek adresu swojej przeglądarki, na samym końcu obecnego linku.
Jeśli w Twojej przeglądarce jest włączony kod JavaScript, to na początku tego wpisu, zamiast słów o siedzeniu w clearnecie, zobaczysz coś innego.
Będzie tam też link pozwalający tu wrócić i uniknąć przewijania strony. Komfort czytelników przede wszystkim! :wink:
Ktoś powie: no dobra, ale to tylko tekst dodany do linku. Mała szansa, żeby ktoś to odkrył… Ale nie ma tu konfiguracji ani odrębnych przeglądarek, więc niezbyt podchodzi pod definicję darknetu.
Ale co byśmy powiedzieli, gdyby ktoś:
- wziął publicznie dostępny kod źródłowy jakiejś przeglądarki (na przykład Chromium albo Firefoksa),
- dodał do niego regułkę sprawiającą, iż podczas odwiedzania jakiejś strony będzie dodawało do linku tajne hasło,
- utworzył z tego kodu przeglądarkę i zainstalował ją na wybranych komputerach?
W ten sposób, bez użycia żadnych nietypowych protokołów, mamy pełnoprawny efekt darknetu – tylko wybrane urządzenia są w stanie zobaczyć ukryte treści na jakiejś stronie. Zwykli użytkownicy widzą coś innego.
W moim przypadku jest nieco inaczej, bo nie mam wglądu do serwera i muszę korzystać z kodu JavaScript na stronie, widocznego dla wnikliwych. Ale w normalnej sytuacji analiza parametrów odbywałaby się na odwiedzanym serwerze, poza oczami innych.
Podsumowanie
Wizja mrocznych internetowych głębin przemawia do wyobraźni. Nic dziwnego, iż media chętnie się do niej odwołują. Ale wywołują niemało szkód, zlepiając różne rzeczy w jedno. Darknet, Tor, przestępstwa. Te trzy rzeczy strasznie często pokazują razem.
Mam nadzieję, iż mój wpis pokazał, iż rzeczywistość jest bardziej złożona. Tor, warstwy internetu oraz sprawy legalności to trzy osobne zbiory, które nie muszą się przecinać.
Możemy używać Tora do zwykłego łażenia po publicznym clearnecie. Możemy w nim znaleźć rzeczy nielegalne, korzystając z pierwszej lepszej przeglądarki. Zaś deepnet, wbrew egzotycznej nazwie, to coś absolutnie powszechnego i choćby facebookowe profile mogą tam trafić.
Owszem, gdzieś istnieje styk trzech zbiorów. Tam Tor spotyka się z darknetem (strony typu .onion), a równocześnie z czymś nielegalnym.
Ale takie miejsca nie są normą. jeżeli sami ich nie szukamy, to pewnie nigdy na naszej drodze nie staną. Dlatego nie ma sensu demonizować Tor Browsera oraz zapewnianej przez niego anonimowości. Bo kto wie, może nam się kiedyś przydać.













