Overview

In erstwhile articles, we primarily focused on the gateway side, where we handle requests from OQS and fetch the essential data from workers. The gateway operates as both a client and a server. To manage the dense workload of handling 2,160 workers with only 64 threads, we usage coroutines to avoid slowing down erstwhile juggling lots of requests at once. On the individual side, each individual handles 1 request at a time, so they don't request coroutines as everything runs smoothly with 1 thread. We have circumstantial threads—one for handling user queries and another for analytics (there are more threads, like for schemaless query, but I will skip this).
In this article, I’ll show an alternate approach for writing an efficient server-side solution for instances that handle less requests. I’ll besides usage std::shared_ptr to automate memory management and avoid manual allocation. Additionally, we will focus on implementing a mechanics for interrupting queries, enabling the cancellation of long-running requests.
Protobuf structure
As usual, we begin by defining how the Request will be structured in the protobuf file.
Listing 1. Example protobuf structure for streaming a Handle request.
Based on the method specified in the Request JSON message, the individual will find which thread will handle it. The consequence will besides be in JSON format, which is why we can specify the consequence as a string. Both the server and client will parse this string and make a JSON object to interpret the request and response.
Request Context class
Since everything will be handled asynchronously, we request to allocate memory and store all essential data—such as the server context, request messages, and so on—in a single location. After completing a request, we request to release the memory to make area for fresh requests. Previously, we handled this process manually, which may be risky and may origin a memory leak. A more reliable solution is to usage a reference-counting mechanism. Each time an object is copied, its mention number increases. erstwhile the last mention is destroyed, the memory is automatically freed. In C++, this is managed utilizing std::shared_ptr.
As mentioned earlier, the request can be in 3 states: Pending, Finished, or Interrupted (asynchronously completed). We will make a class to represent each state and implement the corresponding logic for each state. For example, a Pending state will initialize a fresh request, while a Finished state will finalize the request and send a position code. Each state will be represented by a tag which hold a std::shared_ptr to the context, ensuring that the memory is only freed erstwhile all tags have been processed. This approach ensures automatic memory management and immediate cleanup erstwhile the request is finished.
To cater to the varied logic of each request, we can employment the Template Method plan pattern. This pattern allows subclasses to specify their own behaviour for certain functions, like init or createNewHandler, while adhering to a common structure provided by the base class. Currently, we only have the Handle method, but in the future, we can easy add as many methods as needed to extend the functionality.
Listing 2. RequestContext class
Listing 3. HandlerTag class
Initialize server
We’re all set to initialize the server and start processing messages. The next step is to make a completion queue and enter a loop to process the tags. Since our tag is an object, we can simply cast it and run the appropriate logic. We can leave the memory management headaches behind, as it's all release automatically. The main things we request to focus on are mistake handling, deadlines and managing request interruptions.
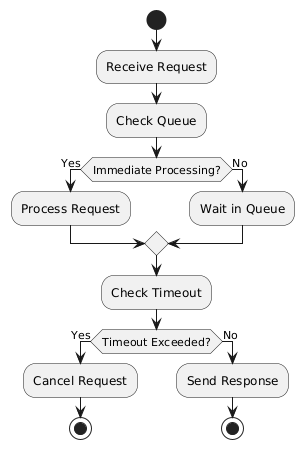 Img1. Overview of requests handling by worker
Img1. Overview of requests handling by workerError handling can be easy managed utilizing a try-catch block. If an mistake occurs while preparing a consequence or during function execution, we can catch it and send the mistake message as the response. Dealing with lost client connections can present a more complex challenge. In scenarios where the server is incapable to send a consequence due to a lost connection, the server won't initiate an automatic retry. Instead, it will stay in a state where it waits for the same request to come back around, giving it another shot at sending the response. If this solution is not ideal, we could implement a retry mechanics that triggers a reattempt to send the message. This approach can be useful, especially erstwhile it takes a crucial amount of time to collect data. alternatively than re-collecting the data, we can effort respective times to send the response, possibly improving the system's resilience in the face of intermittent communication failures.
Navigating deadlines introduces yet another layer of complexity. erstwhile do we kick off the countdown for these timelines? Is it right after the request is sent? Since the individual queues requests and handles them 1 by one, a request might spend up to 2 minutes waiting in the queue. How should we handle a situation erstwhile a request takes 10ms to process, but spends 2 minutes in the queue? Should the deadline be considered reached in this case?
In Terrarium, we decided to start measuring the deadline from the minute we send a request from OQS. For example, if a request has a 5-minute deadline, we set the deadline to "now + 5 minutes." So, if a request spends 1 minute in the gateway queue and another 2 minutes in the individual queue, the individual will have 2 minutes to finish processing the request. If the individual doesn't complete the request in that time, it will be interrupted. This solution helps defend the strategy from overly dense requests that could block the full process and make the gateway unresponsive. For example, if a individual spends 15 minutes processing an analytics request, another requests may be left waiting indefinitely without a response. By enforcing deadlines in this way, we guarantee that long-running requests don't block the strategy and keep the gateway's responsiveness.
The last part of the puzzle revolves around handling client-initiated request interruptions. For example, we may initiate a task that takes respective minutes to complete, specified as fetching dense data. However, after just 10 seconds, we realize the query was incorrect and want to halt it. Without a appropriate interruption mechanism, we'd gotta wait for the full task to finish (e.g., 4 minutes) only to get an unwanted result, then submit a fresh query.
While gRPC supports cancellation, implementing this in the asynchronous version can be a bit tricky. Our strategy involves utilizing 2 tags: Finish and Interrupt, and each request needs to process both tags—even if the request isn't interrupted. These tags can arrive in any order, so determining erstwhile to halt a task isn't straightforward. For example, an interrupt tag could arrive at the end of a request, after it's already being finalized.
Managing interrupt tags presents another hurdle: erstwhile we receive a tag, how do we actually interrupt a moving function? Our best course of action involves meticulously designing interruptible segments within the function. This strategical planning should be an integral part of the first plan phase erstwhile crafting the data collection algorithm. For instance, if we're reading data from a file inside a loop, we can check for a cancellation request after each iteration. Upon receiving an interrupt tag, we can trigger a callback or set a flag. The function that fetches the data will periodically check this flag and halt if necessary, or the callback function will prevent further calculations. This way, the request can be interrupted smoothly without waiting for the task to finish.
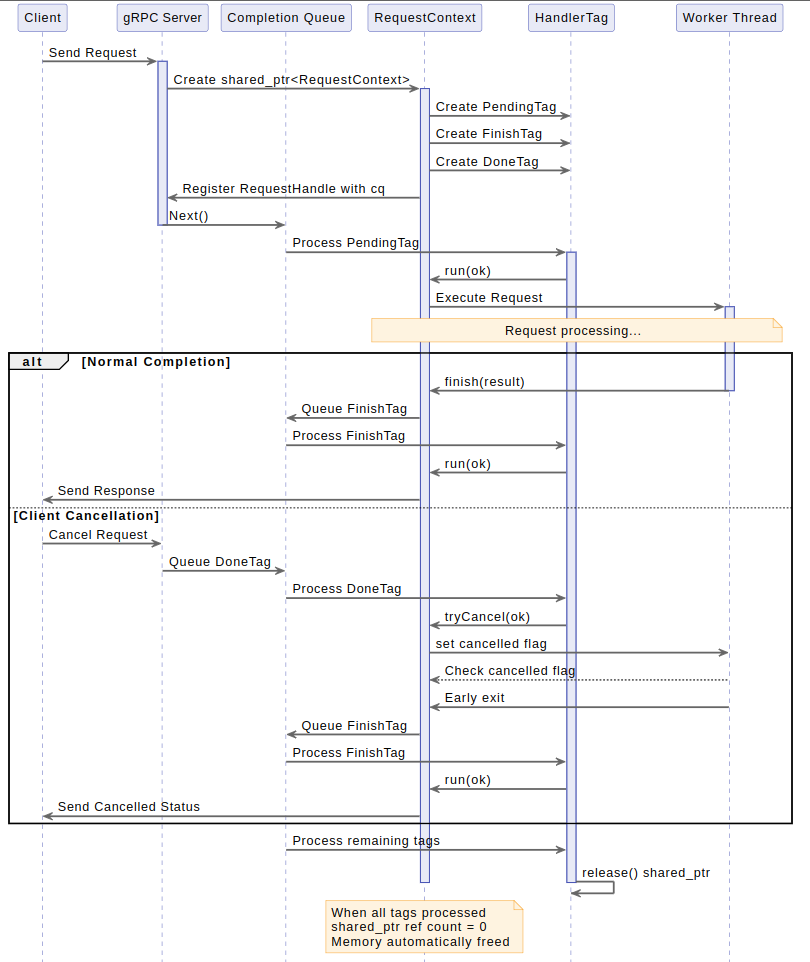 Img2. series diagram of request handling
Img2. series diagram of request handlingSince we usage std::shared_ptr, we don't request to worry about manually calling cancel, even after the query is finished. This is due to the fact that all the essential data is stored in the RequestContext object, which will only be deleted erstwhile all tags have been processed. So, even if we receive the Finish tag first and the Interrupt tag later, we can inactive set a flag or invoke a callback. The object will not be deallocated until both tags are processed, ensuring that no memory is prematurely freed. If the interrupt is received after the finish, it will fundamentally do nothing, but it won't origin a crash. erstwhile the last tag is processed, the memory will be automatically released.
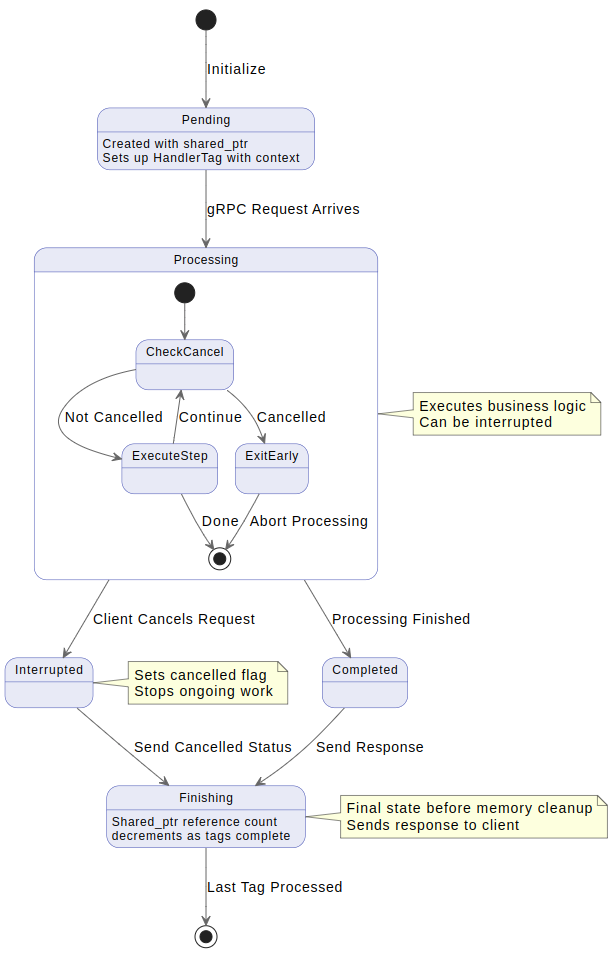 Img3. Processing a pending tag. Handling request and verify cancellation.
Img3. Processing a pending tag. Handling request and verify cancellation.After designing the server, we can rapidly implement a solution that addresses all the mentioned issues. The first step is to add a function to the server that creates an first handler to set up the gRPC Handle method. This function will push a completion queue, a callback, and a pointer to the service, allowing the server to manage requests and handle asynchronous processing effectively.
Listing4. Initialization of Handle request
Next, we request to make a class named HandleContext, which will inherit from RequestHandler and override the missing functions utilizing the template method plan pattern.
Listing5. Override method by HandleContext class
When we decide to add a fresh gRPC method, we can easy make a fresh class and override these 3 functions, thanks to the template method pattern. Now, we request to implement the HandlerTag function. This function should release the mention to the shared_ptr upon completion. Additionally, it must guarantee that the same tag is not invoked twice, as doing so would constitute a bug that should never occur.
Listing 6. HandlerTag class
Once we make all implementation, we request to implement completion queue, that will support deadlines and another errors
Listing 7. Completion queue loop for handling requests
Comparison of Different Approaches
Summarizing the 3 approaches discussed in erstwhile articles, we can measure their pros and cons:
Global Map with Tags as Keys and Coroutines as Values
Advantages:
- Straightforward to implement if a high-performance thread-safe map is available.
- No request to manage memory manually, as coroutines encapsulate essential data on the stack and reconstruct it during resumption.
Disadvantages:
- Performance depends heavy on the efficiency of the thread-safe map. A slow map can importantly impact coroutine retrieval. Optimization is possible by utilizing separate maps for each completion queue, reducing contention, and improving access velocity erstwhile multiple queues are used.
Self-Allocate/Deallocate Objects
Advantages:
- High performance since only essential data is stored and manually freed after request processing.
- Avoids overhead from mention counting or thread-safe mechanisms.
Disadvantages:
- Increased complexity in implementation.
- Risk of memory leaks if objects are not decently deallocated.
- Harder to keep and understand, making debugging and future improvement more challenging.
Reference Counter Objects
Advantages:
- Uses std::shared_ptr for automatic memory management, simplifying life handling.
- Minimizes the hazard of memory leaks erstwhile implemented correctly.
- Easier to compose and keep compared to manual memory management.
Disadvantages:
- Slower than manual object management due to the overhead of mention counting, which frequently relies on thread-safe locking mechanisms.
Choosing the Right Approach
The perfect approach depends on the circumstantial requirements of your application:
- For high-concurrency scenarios where managing thousands of requests simultaneously is critical, coroutines are preferable to minimize thread-switching overhead.
- For little demanding code areas, simpler implementations like manual or reference-counted object management may suffice, making the code easier to keep and understand.
Ultimately, balancing performance, complexity, and maintainability is key. Developers can choice the most suitable approach based on the trade-offs and the stress levels of different parts of the system.
Conclusion
In this series, we explored strategies for enhancing the efficiency of streaming and request handling utilizing gRPC and coroutines. This installment focused on designing an optimized server-side solution tailored for instances handling less requests. By leveraging std::shared_ptr for automatic memory management and introducing mechanisms to handle request interruptions, we tackled any of the core challenges in building resilient systems.
We implemented the Template Method pattern to standardize request handling while enabling extensibility for additional gRPC methods. This plan simplifies the creation of fresh handlers, ensuring consistent logic across request types. Furthermore, the HandlerTag class effectively manages state transitions while preventing issues like double-processing or premature memory deallocation.
To guarantee responsiveness, we addressed key challenges, including mistake handling, managing deadlines, and interrupting long-running requests. By adopting these solutions, we prevent blocking operations, keep strategy responsiveness, and handle client cancellations smoothly without risking crashes or memory leaks.
With the addition of a robust completion queue and the ability to handle asynchronous workflows, we demonstrated how to efficiently manage thousands of requests while maintaining advanced strategy performance. These techniques guarantee scalability, reliability, and maintainability, making them indispensable for real-world gRPC-based systems.
This comprehensive approach lays the groundwork for future extensions and adaptations, empowering developers to build efficient and reliable distributed systems.
Mateusz Adamski, elder C++ developer at Synerise