
Jakie GPU(kartę graficzną) wybrać by móc uczyć modele efektywnie i efektowanie? To pytanie spędza sen z powiek nie jednemu. Jak zrobić to dobrze, żeby:
- nie przepłacić
- nie przyoszczędzić, a potem żałować
- być gotowym na przyszłość
- mieć sprzęt, który podoła zadaniom przed nim stawianym
To będzie dłuższy post, opisujący wiele zagadnień związanych z wyborem GPU. o ile interesuje Ciebie jedynie moja konkretna rekomendacja to zapraszam od razu na sam dół tego posta.
Zacznę od jednego, kuriozalnego stwierdzenia: jakiego GPU byśmy nie mieli - to będzie za mało. Niezależnie czy to będzie jedna karta, czy osiem... Ale dlaczego?
Machine Learning przeżywa w ostatnich latach renesans. Danych do obróbki jest multum, modeli do pracy jest multum, hiper-parametrów modeli do sprawdzenia jest multum... niniejsze stwierdzenia sugerują iż przestrzeń poszukiwań w tematyce Deep Learningu jest przeogromna. Wiele gotowych modeli, na dzień dzisiejszy do treningu gotowych modeli używa 8, 16 kart graficznych, które serwują dane przez kilkadziesiąt godzin by wytrenować modele - przykładem może być model Detectron2 (X-101-64x4d-FPN), który uczy się 36h przy użyciu 8 kart graficznych NVidia P100 (każda po 16GB RAMu):
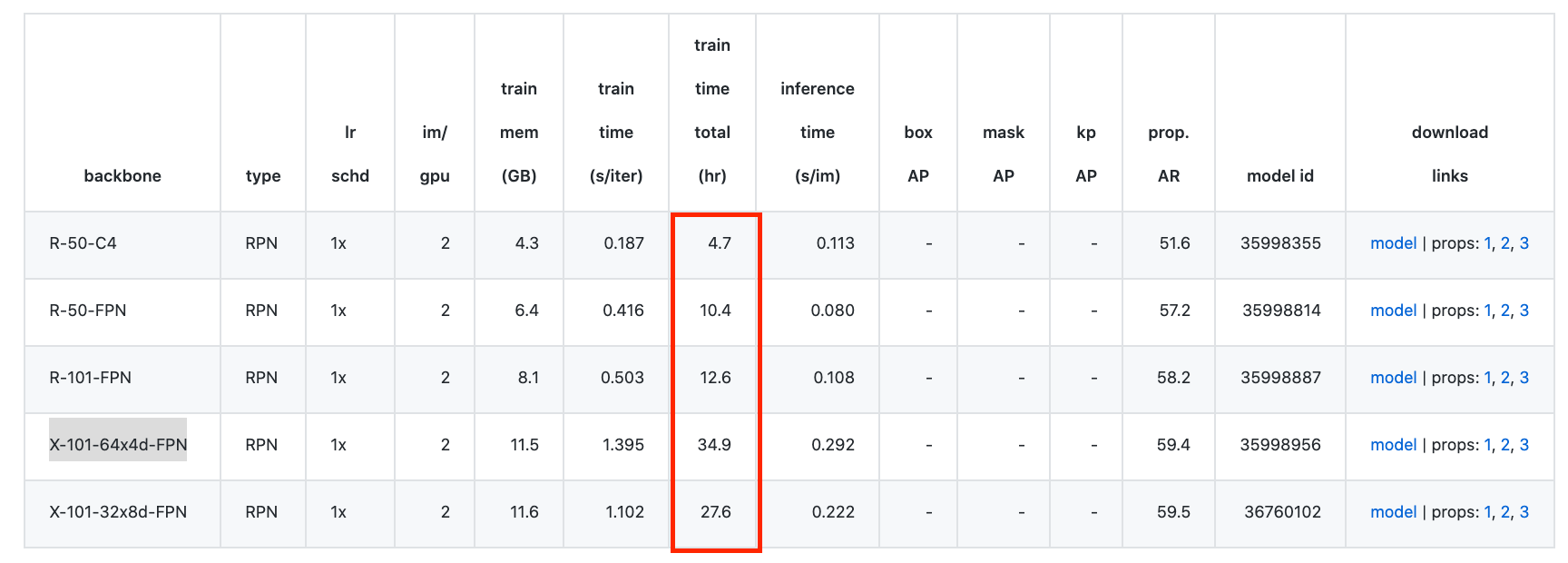 źródło: https://github.com/facebookresearch/Detectron/blob/master/MODEL_ZOO.md
źródło: https://github.com/facebookresearch/Detectron/blob/master/MODEL_ZOO.mdInnej karty/zestawu kart potrzebować będzie:
- researcher algorytmów w Deep Learning
- ktoś uczący modele na nowych dataset-ach
- ktoś korzystający z gotowych, wytrenowanych modeli
Producenci kart
Lista producentów zajmująca się tworzeniem sprzętu, na którym da się sensownie uczuć modele jest krótka: NVidia, AMD, Intel i Google.
Zacznę od Google: ma on do celów uczenia maszynowego ofertę swoich TPU (Tensor Processing Unit), ale jedynie w chmurze. Wprawdzie produkuje też akcelerator machine learning-owy Coral, ale on służy jedynie do używania sieci, a nie ich treningu. W temacie klasycznego GPU nie mają więc oferty.
Co to AMD to na chwilę obecną nie posiadają użytecznej warstwy oprogramowania, która pozwalałaby framework-om machine learning-owym na sensowne wykorzystanie w ich kodzie. Od kilku lat pracuje nad ROCm, ale jest to na dzień dzisiejszy bardziej rozwiązanie teoretyczne niż coś co da się używać.
Tak więc pozostają Intel i NVidia. I faktycznie najpopularniejsze framework-i machine learning-owe (PyTorch, TensorFlow, MXNet, Caffe, Keras, CNTK, fast.ai, ...) rozwiązania obu tych producentów wspierają.
Wiadomo jednak, iż przy takim zapotrzebowaniu na moc obliczeniową jakie ma Deep Learning procesory Intel-a nie sprawdzają się na dłuższą metę, mimo wielu sprzętowych optymalizacji takich jak AVX czy MKL. Ostatnia nowinka od Intela pod enigmatyczną nazwą technologii Deep Learning Boost okazuje też nie być żadnym wsparciem do treningów modelu, ale tylko do używania gotowych modeli i to tylko w trybie INT8 (niżej będzie trochę więcej na ten temat).
NVidia jest jedynym producentem, który ma przygotowane oprogramowanie wspierające obliczenia operacji w sieciach neuronowych na najwyższym poziomie. Ich CUDA jest API zawierającym implementacje wielu funkcji matematycznych bezpośrednio na kartach graficznych. Porównując prędkości przetwarzania GPU do CPU operacje są kilkudziesięciokrotnie szybsze.
Sprawa jest więc jasna: tylko NVidia. Tyle, iż to dopiero początek poszukiwań bo patrząc na listę modeli kart wyprodukowanych przez NVidię jest tego sporo.
Parametry kart
Na czym nam zależy wybierając kartę graficzną?
W zależności od przypadku z jakim pracujemy zależeć może nam
- Opóźnienie (latency) - w zależności od architektury oraz sposobu połączenia karty (PCI-e, Thunderbolt) opóźnienie przesyłu danych może się różnić. Jest to wartość czasu jaka mija pomiędzy wysłaniem danych z pamięci systemu do pamięci karty. Ten czynnik jest szczególnie istotna o ile nasz proces przewiduje bardzo częste przerzucanie małych porcji danych - w Computer Vision to raczej nie jest realny przypadek, ale warto mieć o tym świadomość.
- Prędkość przetwarzania (Raw performance) - jest to teoretyczna wartość z jaką dane mogą być przetwarzane - niestety ciężko o jedyny wskaźnik który powie nam dokładnie jak karta sprawować się będzie w Deep Learningu. 'Raw performance', będący miksem ilości CUDA corów, taktowania kości jest jedynym punktem odniesienia co do mocy karty, choć nie taktowałbym tego tak, iż istnieje liniowa zależność pomiędzy 'raw performance' i np. prędkością FPS danej sieci.
- Ilości pamięci RAM, co ma swoje konsekwencje w wielkości batcha, jaki będziemy mogli jednocześnie wgrać na kartę. Wielkość batcha utożsamiana może być z adekwatnym wykorzystaniem przetwarzania równoległego karty graficznej, możliwością lepszej generalizacji danych, czerpania korzyści z normalizacji batcha. Często szybka karta o małej ilości RAM-u nie może wykorzystać w pełni swojego potencjału.
Jakie parametry ma karta graficzna ?
- RAM - Ilość pamięci dostępna na dane. (O znaczeniu tego parametru pisałem wyżej.)
- RAW Performance - teoretyczna maksymalna prędkość przetwarzania podawana w GFLOPS (Giga floating point operations per second - Giga(10^9) operacji zmiennoprzecinkowych na sekundę). Osobiście używam strony TechPowerUp do porównania tego parametru z innymi kartami (przykład: specyfikacja RTX 2070)
- SLI support - wsparcie systemu łączenia kart, który może okazać się istotny w przypadku przyszłej rozbudowy systemu. Często w praktyce okazuje się, iż zamiast wymieniać posiadaną kartę na nowy model warto zainwestować w drugą sztukę takiej samej karty by uzyskać dużo lepszą teoretyczną wydajność przy niższych kosztach. Obsługa SLI zapewnia, iż karty będą komunikować się między sobą z dużą wydajnością.
- TDP Power - ilość prądu mierzona w Watach jaką karta pobierać będzie przy maksymalnym obciążeniu - wpływa to na zapotrzebowanie na moc zasilacza, a także koszty opłat za prąd. Idealną ekonomicznie kartą byłaby ta która ma maksymalny współczynnik RAW Performance/TDP Power.
- Obsługa wersji CUDA - o ile wybór karty sprowadza się do nowych to ten parametr nie jest istotny, niemniej należy pamiętać, iż frameworki machine learning-owe mogą bezpośrednio lub pośrednio wymuszać minimalną wersję CUDA. Przykładowo: Tensorflow wymaga do obsługi GPU Cuda Compute Capability 3.5; PyTorch 1.3 wymaga Cuda Compute Capability 3.7)
- GTX vs RTX - Często słyszę, iż karty RTX wyprzedzają wymagania gier i są na tyle mocna, iż ciężko je w 100% wykorzystać. Jednak: gry to gry, deep learning to deep learning - tutaj możemy wszystko wykorzystać na 100%).
Co takiego oferują karty RTX względem GTX ? Główną różnicą, patrząc z perspektywy machine learning-u jest obsługa typów danych FP16 oraz INT8 w wydajny sposób.
FP32 to standard zapisu liczb zmiennoprzecinkowych natywnie wspierany przez karty GTX. Każda wartość liczbowa zajmuje dokładnie 4 bajty. W przypadku FP16 ta wartość jest dwukrotnie mniejsza - przy treningu z dokładnością FP16 mamy więc możliwość upakowania w pamięci karty dwa razy więcej danych (są wprawdzie wyjątki, w których nie konwertuje się danych z FP32 to FP16 ale można potraktować to tutaj marginalnie). RTX wspiera natywnie typ FP16 co oznacza w praktyce, iż przetwarzanie FP16 jest dwa razy szybsze niż FP32. GTX nie wspierając FP16 natywnie sprawia, ze te operacje są niewyobrażalnie wolne. Tutaj jest lista wszystkich kart NVidia z ich wydajnością FP32-"single precision" i FP16-"half precision". O tym, iż w FP16 najsłabsza karta RTX wyprzedza najmocniejszą GTX można przeczytać też tu.
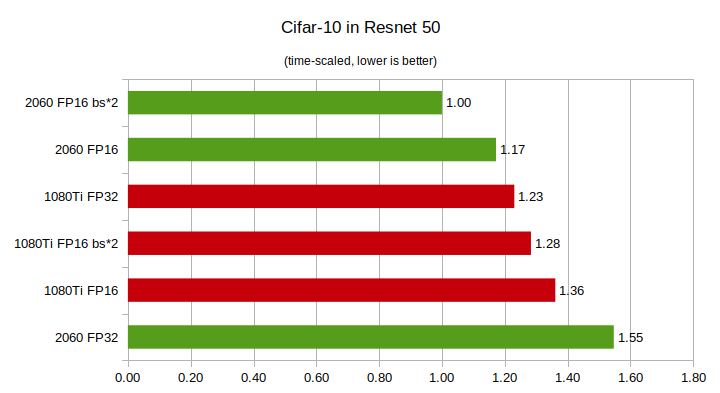 źródło: https://towardsdatascience.com/rtx-2060-vs-gtx-1080ti-in-deep-learning-gpu-benchmarks-cheapest-rtx-vs-most-expensive-gtx-card-cd47cd9931d2
źródło: https://towardsdatascience.com/rtx-2060-vs-gtx-1080ti-in-deep-learning-gpu-benchmarks-cheapest-rtx-vs-most-expensive-gtx-card-cd47cd9931d2Jedna vs wiele
Podawany wcześniej argument, iż zamiast kupować nową kartę można dokupić drugą by efektywniej wykorzystać kapitał ma też swoją ciemną stronę. Wprawdzie uczenie na dwóch kartach jest wydajne, niemniej kod treningowy musi by gotowy to obsługi dwóch kart. W PyTorch zwykle bywa to kwestia dopisania trzech linii kodu, jednak jest to dodatkowa praca, którą trzeba wykonać. W złożonych modelach koniecznych modyfikacji może być więcej.
Jeżeli budujemy modele sami z myślą, iż od razu używany dwóch czy więcej GPU to nie powinno być żadnego problemu.
Pamiętajmy też, iż argument rozszerzania o kolejną kartę nie sprawdzi się w przypadku 95% laptopów, które większość komponentów mają zintegrowane.
Chmura
Ktoś mógłby powiedzieć, iż w świecie gdzie co roku wychodzi nowa karta graficzna warto byłoby zainwestować w obliczenia chmurze...
Najwięksi dostawcy usług w chmurze jak AWS, Azure, Google Cloud Platform, Oracle mają trochę związane ręce przez postanowienia licencyjne NVidia. Otóż NVidia w swych produktach ma wyraźny podział na karty konsumenckie i serwerowe. Te drugie, będąc kilkukrotnie droższe są jedyną komercyjną możliwością dla dostawców usług chmurowych. Sprawia to, iż koszty najmu tych kart są horendalnie wysokie.
Rozważając ostatnio zakup karty RTX 2080 TI porównałem koszty jej używania do kosztów jakie poniósłbym używając (bez przerwy) chmurowych usług najmu kart graficznych. Z obliczeń wynikało iż po 3 miesiącach pracy z chmurą zwraca się koszt karty graficznej. Jest to istotne, gdy ktoś planuje obliczeń dokonywać przez cały czas.
Korzystając osobiście z chmury doświadczyłem też innych niedogodności:
- czas startu maszyny jest zmienny (czasem trzeba chwilę poczekać)
- wszystkie dataset-y potrzebne do nauki trzeba wkopiować do chmury. W przypadku Computer Vision dataset-y zajmują niekiedy setki gigabajtów. Takie kopiowanie kosztuje to czas i pieniądze za transfer.
- pre-konfigurowane środowiska do uczenia maszynowego mogą wersjami odbiegać od pożądanej konfiguracji, więc trzeba je modyfikować i konfigurować do swoich potrzeb.
Market kart graficznych
Inną ciekawą opcją uczenia "w chmurze" jest skorzystanie z takiego serwisu jak vast.ai, który jest giełdą wynajmowania sprzętu do obliczeń. Tutaj możemy spotkać karty linii konsumenckich. Rozwiązanie to jest dużo tańsze niż chmura, ale:
- podatne na niestabilność środowiska
- potencjalnie niebezpieczne (przesyłamy dane na czyjś komputer)
- parametry maszyn zdecydowanie od siebie odbiegają (czasem jest słaby transfer do maszyny, czasem ma slaby procesor i preprocessing danych staje się wąskim gardlem systemu)
Wydajność, ekonomia
Przyglądnijmy się teraz opracowaniom z dwóch źródeł w internecie na temat wydajności kart graficznych w Deep Learningu.
Obfitym źródłem wiedzy na temat porównania wydajności kart jest firma Lambda Labs, a w szczególności ich artykuły:
- Deep Learning GPU Benchmarks - Tesla V100 vs RTX 2080 Ti vs GTX 1080 Ti vs Titan V
- Titan RTX Deep Learning Benchmarks
Przykładowo: ostateczne wyniki zaprezezentowane w sposób znormalizowany do wydajności karty GTX 1080Ti pokazują realną różnicę liczoną w obrazach na sekundę pomiędzy wybranymi kartami dla treningu kilku architektur sieci:
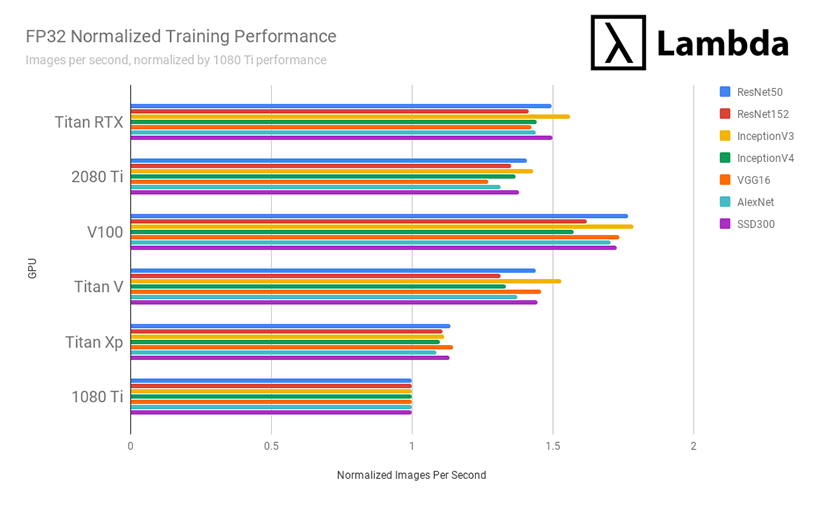 źródło: https://lambdalabs.com/blog/best-gpu-tensorflow-2080-ti-vs-v100-vs-titan-v-vs-1080-ti-benchmark/
źródło: https://lambdalabs.com/blog/best-gpu-tensorflow-2080-ti-vs-v100-vs-titan-v-vs-1080-ti-benchmark/Kolejną bardzo ciekawą stroną opisującą problem wyboru karty graficznej na potrzeby Deep Learning-u jest strona Tima Dettmers'a. Porównuje on kartu posługując się benchmarkami z rożnych źródeł. Porusza on m.in. temat ekonomiczności zakupu danego modelu karty porównując wydajność do ceny:
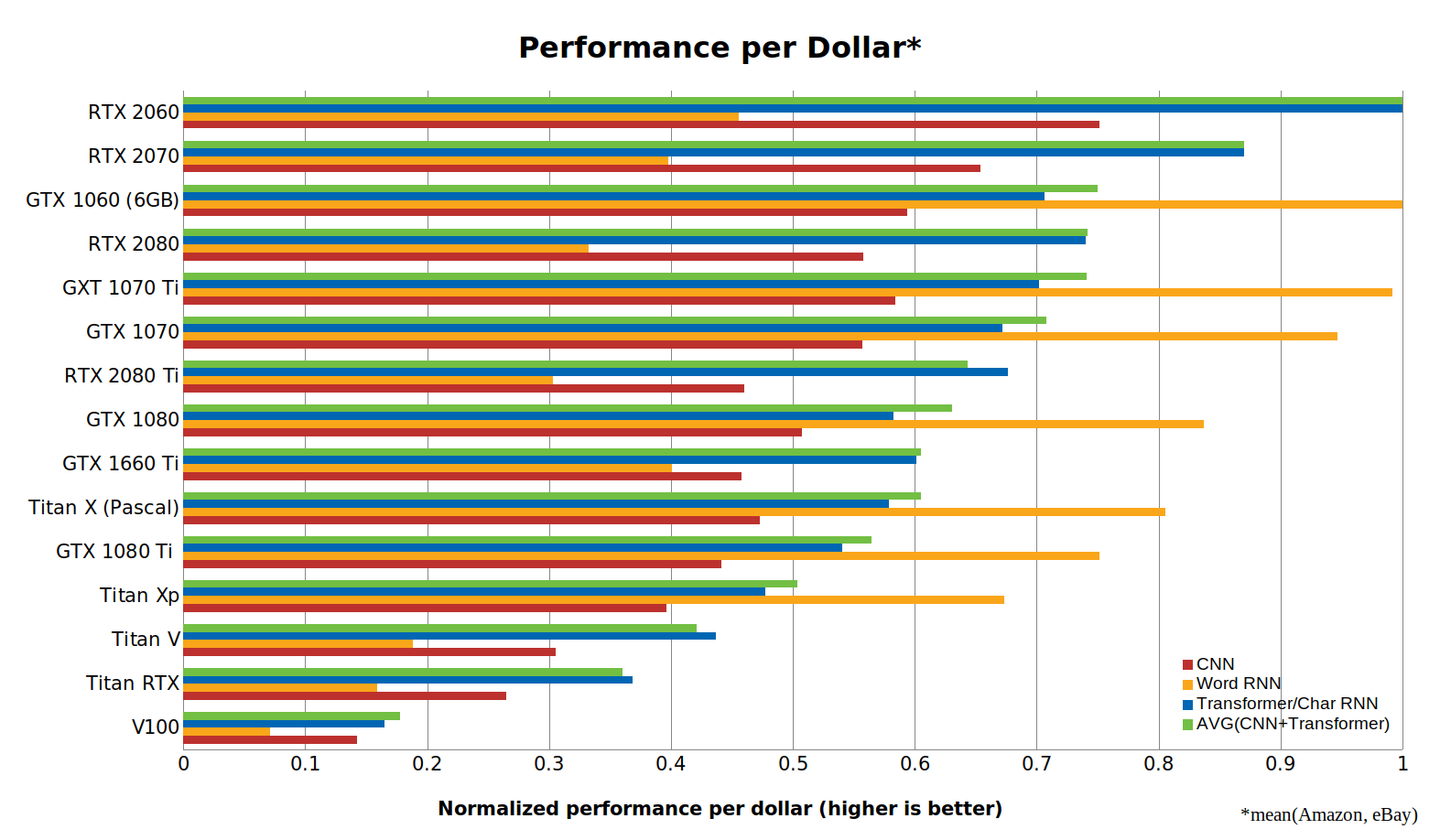 Wydajność za dolara, źródło: https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/
Wydajność za dolara, źródło: https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/A sama wydajność wg tego porównania kształtuje się następująco:
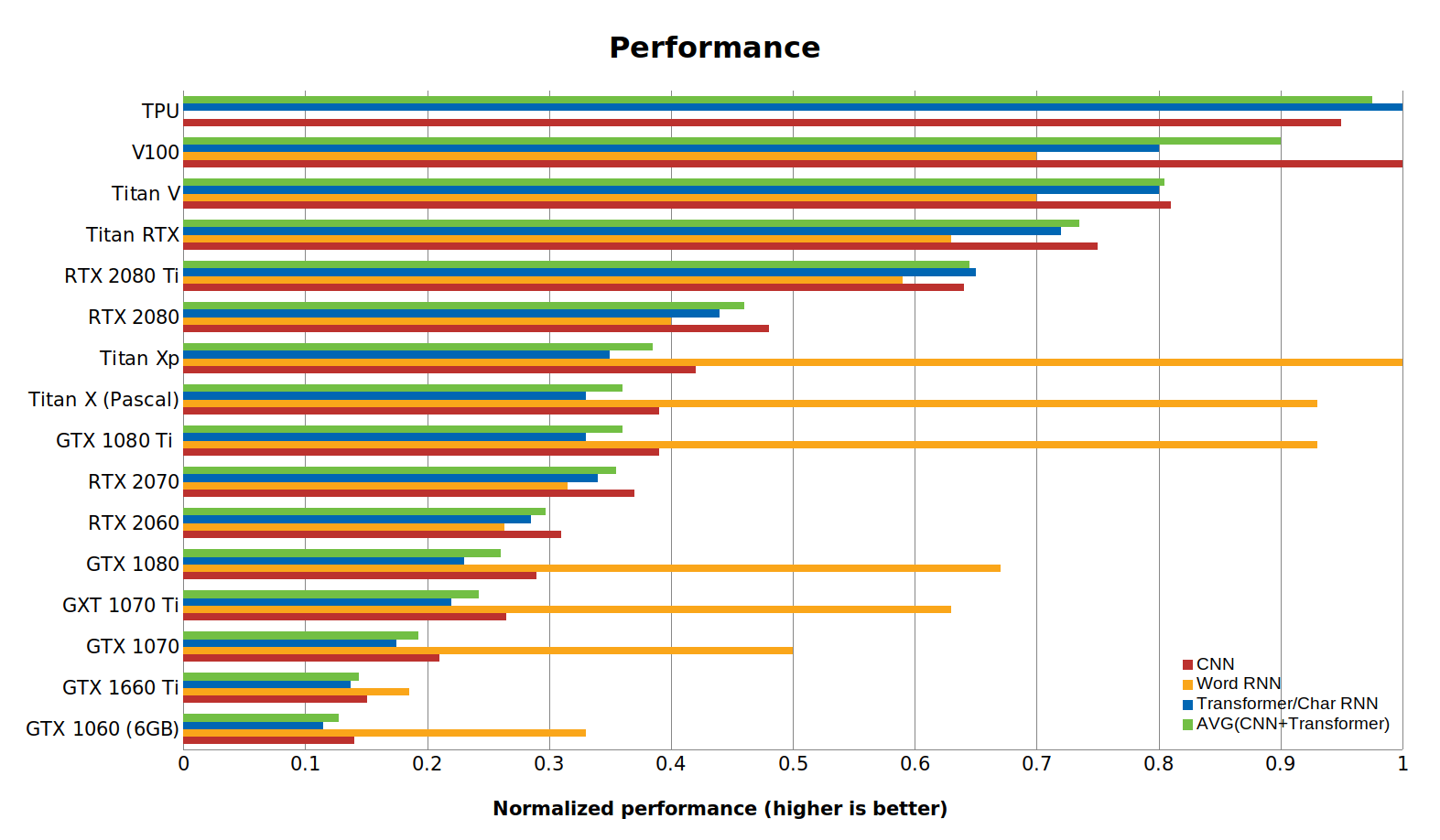 Wydajność, źródło: https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/
Wydajność, źródło: https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/Wersje kart
eGPU
Karty graficzne o pełnych wymiarach mogą być podłączane też do laptopów. To hybrydowe rozwiązanie może sprawić, iż znajdziesz kompromis pomiędzy wysoką wydajnością a mobilnością. Wymaganiem użycia kart zewnętrznych jest posiadanie portu Thunderbolt-3 (lub 2) w laptopie, do którego podłączyć chcemy kartę zewnętrzną.
Zaletą tego rozwiązania jest to iż obudowa, w której znajduje się karta ma osobne zasilanie i bardzo dobrą wentylację. Używałem tego rozwiązania w NVidia GTX 1080 oraz NVidia 2080 Ti + Razer Core X. Poziom hałasu takich rozwiązań jest minimalny, choćby przy wielodniowym wykorzystaniu kart na 100%.
Wadą jest to, iż ciężko taką obudowę zabrać "ze sobą" w przypadku podróży.
MAX-Q
W laptopach możemy mieć do czynienia z kartami klasycznymi, bądź opatrzonymi dopiskiem "MAX-Q". Tych drugich jest zdecydowanie więcej. MAX-Q to wersje kart dostosowane do laptopów - ich taktowanie jest obniżone by sprostać warunkom wentylacyjnym w laptopie. W związku z obniżoną częstotliwością taktowania niższa jest też wydajność takich kart. Wydajność wersji bez dopisku "MAX-Q" może być 40-60% wyższa.
1650 oraz 1660
Większość kart w architekturze "Turing" to karty RTX. Jednak seria 16xx jest inna. Jest trochę jak GTX, trochę jak RTX. Operacje zmiennoprzecinkowe FP16 są dwukrotnie szybsze niż FP32, jednaj system nie posiada Tensor Corów do obliczeń INT8.
V100, K80, P100, ...
Tak oznaczone są karty z linii serwerowej NVidia. Posiadają lepsze własności termiczne i mają więcej pamięci RAM. W chmurach często mogą być współdzielone przez dwie wirtualne maszyny. Przykładowo: Karta K80 składa się fizycznie z dwóch zintegrowanych chipów K40, które są jednak separowalne w oprogramowaniu.
RTX TITAN
Najszybszy w tej chwili na rynku model konsumenckiej karty RTX Titan jest kilka szybszy od RTX 2080 TI kosztując ponad dwukrotnie więcej. o ile masz nieograniczny budżet to lepiej wziąć odpowiednik RTX Quadro 8000 z 48GB pamięci RAM za 30'000zł sztuka. Oba rozwiązania (RTX TITAN, RTX Quadro 8000) są mocno dyskusyjne.
Seria Quadro
Quadro to seria dla profesjonalistów. Większość kart serii GTX posiada swój odpowiednik w serii Quadro wyposażony w dwukrotną ilość pamięci RAM. Oczywiście to wszystko kosztem zdecydowanie wyższej ceny.
Seria RTX SUPER
Wersje kart "SUPER" to taka opcja "na sterydach". Są w liczbach wydajniejsze od swoich poprzedników - jednakże jest to różnica niewielka, przykładowo wykres poniżej przedstawia prędkość uczenia sieci ResNet-50 mierzoną w obrazach na sekundę:
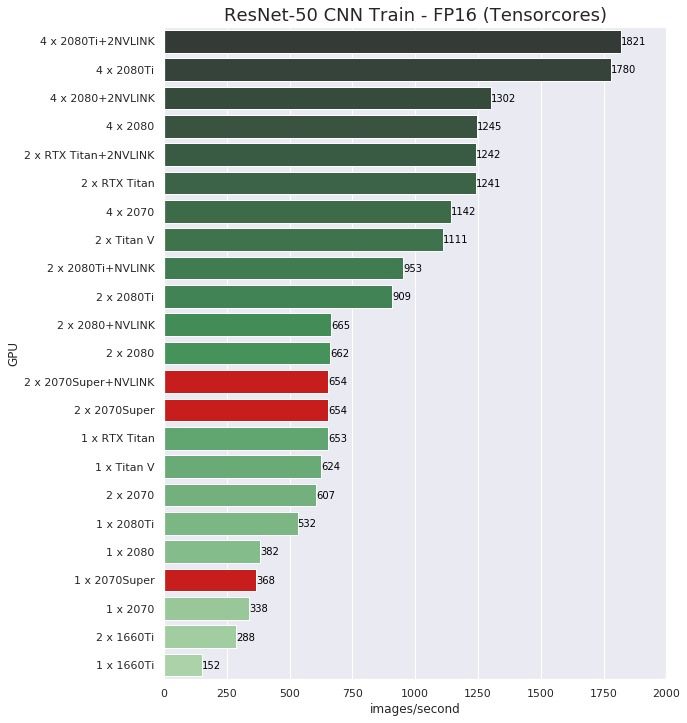 źródło: https://www.pugetsystems.com/labs/hpc/2-x-RTX2070-Super-with-NVLINK-TensorFlow-Performance-Comparison-1551/
źródło: https://www.pugetsystems.com/labs/hpc/2-x-RTX2070-Super-with-NVLINK-TensorFlow-Performance-Comparison-1551/Ponoszonym kosztem, oprócz wyższej ceny jest także większy hałas:
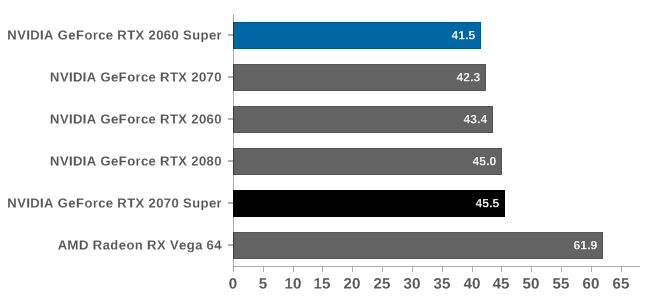 FurMark, poziom głośności w dB. źródło: https://www.anandtech.com/show/14586/geforce-rtx-2070-super-rtx-2060-super-review/15
FurMark, poziom głośności w dB. źródło: https://www.anandtech.com/show/14586/geforce-rtx-2070-super-rtx-2060-super-review/15Werdykt
Biorąc pod uwagę:
- ilość pamięci RAM
- wydajność
- obsługę FP16 oraz INT8
- możliwość podłączenia drugiej karty
- współczynnik wartości do ceny
- poziom hałasu
- cykle produkcyjne kart graficznych
do prototypowania polecam (teraz, pod koniec 2019):
Desktop: NVidia RTX 2070 (desktop)
Laptop: NVidia RTX 2070 Max-Q (laptop)
Badania nad rozwojem sieci w poszukiwaniu hiperparametrów czy uczenie skomplikowanych modeli, chcąc zaoszczędzić czas adresowałbym przy użyciu rozwiązań chmurowych, prawdopodobnie przy użyciu kart NVidia V100.








