Praca przy systemie legacy kojarzy się z przykrym obowiązkiem. Z perspektywy entuzjasty Domain-Driven Design, systemy te kryją w sobie wiele skarbów. Dla mnie najcenniejsze są solidnie przetestowane reguły biznesowe, które sprawdziły się na produkcji. Oznacza to, iż systemy legacy rzadko zaskakują zmianami reguł biznesowych z dnia na dzień.
Co sprawia, iż odczuwamy lęk przed pracą z systemami legacy? Prawdopodobnie obawiamy się tzw. „długu technologicznego”. To pojęcie zostało ukształtowane przez Warda Cunninghama na początku lat 90. ubiegłego wieku i oznacza świadome skrócenie czasu poświęconego na projektowanie i tworzenie systemu w celu szybszego dostarczenia gotowego produktu. Skrócenie lub pominięcie fazy projektowania skutkuje obniżeniem jakości kodu.
Czy dług technologiczny zawsze jest czymś negatywnym? Niekoniecznie. Szybsze wprowadzanie kodu do produkcji daje przewagę nad konkurencją. Możemy porównać dług technologiczny do pożyczki na spełnienie marzeń o wymarzonym telefonie, samochodzie czy mieszkaniu. Dzięki zaciągnięciu tego „kredytu” możemy osiągnąć nasze cele znacznie szybciej. Problem pojawia się jednak, gdy tracimy kontrolę nad zaciągniętym długiem. To prowadzi do problemów wydajnościowych, trudności w utrzymaniu i rozwoju aplikacji. Właśnie te cechy kojarzą się z systemami legacy. Zatem niespłacony dług techniczny stanowi największe wyzwanie.
Zapach kodu
O kodzie źródłowym niskiej jakości często mówimy, iż posiada tzw. „zapachy” (ang. „code smells”). Przyjrzyjmy się im krótko. Pierwszym, dobrze znanym, jest tzw. „ośmiotysięcznik” – obszerny fragment kodu, który nie tylko utrudnia zrozumienie ze względu na swoją długość, ale prawdopodobnie łamie zasadę pojedynczej odpowiedzialności (ang. SRP – Single Responsibility Principle), ponieważ jest odpowiedzialny za zbyt wiele elementów.
Po analizie długości kodu, czas przyjrzeć się jego „szerokości” – czyli metodom posiadającym dużą liczbę parametrów i/lub długimi nazwami. Takie metody również naruszają SRP. Kolejnym rodzajem „zapachu” jest tzw. „ifoza”. Oznacza to obecność wielu instrukcji warunkowych w jednej metodzie (czasami zastępowanych przez switch, jednak to nie rozwiązuje problemu). Pracując w języku obiektowym, taki „zapach” zwykle można wyeliminować poprzez zastosowanie polimorfizmu.
Czytając książki takie jak „Clean Code” R. C. Martina („Uncle Bob-a”), „Refactoring: Improving the Design of Existing Code” M. Fowler’a, czy „Working Effectively with Legacy Code” M. Feathersa, można dojść do wniosku, iż natychmiastowe pozbywanie się wszystkich „zapaszków” z naszego kodu jest idealnym celem. Jednakże, w kontekście pracy z systemami legacy, zadanie to może przypominać syzyfową pracę syzyfową. Na każdym kroku widzimy miejsca do poprawy, co może być przytłaczające. Jak zatem uniknąć depresji?
Odpowiedź jest prosta: poprawiajmy tylko te miejsca w kodzie, które w danym momencie są dla nas opłacalne. Pojęcie „opłacalności” możemy zaczerpnąć od specjalistów z dziedziny ekonomii, którzy zdefiniowali termin „zwrot z inwestycji”. To określa czas, po którym zainwestowane środki (w naszym przypadku czas programisty) przyniosą zysk (czyli poprawa kodu spowoduje, iż praca przy nim stanie się szybsza).
Zwrot z inwestycji = Koszt + oszczędności
Jak zrozumieć zmiany
Przeprowadźmy krótkie ćwiczenie. Załóżmy, iż potrzebujemy 40 godzin, aby „naprawić” jakiś fragment systemu. Dzięki tej zmianie, nowe osoby potrzebują już tylko 4 godzin, zamiast 8, aby zrozumieć ten fragment systemu. To oznacza, iż za każdym razem oszczędzamy 4 godziny. Pytanie brzmi, jak często zaglądamy w dany fragment? jeżeli zakładamy, iż robimy to raz na miesiąc, inwestycja zwróci się po 10 miesiącach. Jednak, zanim przystąpimy do zmian, warto zastanowić się, czy warto czekać tak długo na zwrot z inwestycji. Co się stanie, jeżeli refaktoryzacja zajmie więcej czasu, niż pierwotnie oszacowaliśmy?
Przed przystąpieniem do refaktoryzacji warto również zastanowić się nad konsekwencjami. Po pierwsze, podczas wprowadzania zmian zawsze istnieje ryzyko, iż niechcący wprowadzimy błąd do systemu. Konsekwencją tego może być konieczność poświęcenia czasu w jego naprawę. Gdy uda nam się poprawić kod, należy wziąć pod uwagę fakt, iż zespół będzie musiał zrozumieć nowy fragment. Zapoznanie się z wprowadzonymi zmianami wymaga czasu. To dodatkowy koszt, poza czasem spędzonym na modyfikację kodu. Prawdopodobnie nakład pracy, jaki pozostali członkowie zespołu muszą poświęcą na ponowne zrozumienie kodu, będzie mniejszy niż ten potrzebny autorowi na wprowadzenie zmian. Niemniej ten czas zostanie pomnożony przez liczbę osób aktywnie pracujących nad tym modułem. Warto pamiętać o tym często pomijanym aspekcie.
Poszukiwanie miejsc do refaktoryzacji w kodzie legacy przypomina szukanie igły w stogu siana. Bez względu na to, gdzie spojrzymy, zawsze znajdziemy fragmenty kodu, które można by poprawić. Niestety, miejsca, gdzie wprowadzenie zmian przyniesie rzeczywiste korzyści, są dość rzadkie. Czy możemy usprawnić proces poszukiwania miejsc do poprawy? Odpowiedź jest twierdząca. Z pomocą przyjdzie nam system kontroli wersji np. Git.
Zastosowanie systemu kontroli wersji, znacząco zwiększa efektywność, poprzez dostarczenie dodatkowego wymiaru analizy – wymiaru czasu. Podczas przeglądania kodu w zwykłym edytorze widzimy jedynie jego obecny stan. W Gicie mamy dostęp do historii zmian, która wzbogaca naszą perspektywę. Analizując historię w danym pliku (git blame), możemy dowiedzieć się, jak często dany fragment kodu ulega zmianie. To istotne, ponieważ pomaga nam lepiej ocenić, czy inwestycja w refaktoring w konkretnym miejscu przyniesie korzyści.
Korzystając z równania obliczania zwrotu z inwestycji, możemy oszacować, na podstawie danych historycznych, jak często dane miejsce będzie poddawane modyfikacjom. Może się okazać, iż fragment, który planujemy zmienić, nie uległ żadnym modyfikacjom od kilku miesięcy. W takim przypadku lepiej jest skierować uwagę na inne obszary, gdzie zmiany są bardziej aktywne i prawdopodobnie przynoszą większe korzyści. W ten sposób możemy efektywniej zarządzać refaktoryzacją, kierując nasze wysiłki tam, gdzie są najbardziej potrzebne i skuteczne.
Analiza historii całego kodu może być wyzwaniem, zwłaszcza w przypadku dużych repozytoriów. Na szczęście, systemy kontroli wersji, takie jak Git, dostarczają narzędzi ułatwiających tę analizę. Wystarczy skorzystać z wiersza poleceń i wpisać komendę git log, aby uzyskać wynik podobny do poniższego:
Oczywiście, pełna automatyzacja analizy historii commitów jest kluczowa dla efektywnego zarządzania dużymi repozytoriami. Wprowadzenie kilku parametrów do komendy git log pozwala uzyskać dane w bardziej strukturalnym formacie, zdatnym do automatyzacji.
Zbierając te dane w ten sposób, możemy stworzyć model, który pozwoli na dalszą automatyzację analizy historii commitów. Dokładnie, analiza częstości zmian w plikach oraz ich rozmiaru stanowi potężne narzędzie w identyfikacji „Hot spotów” w kodzie. Kombinując te metryki, można stworzyć mapę, która pomaga skupić uwagę na obszarach najbardziej wymagających uwagi. Oto kroki analizy:
1. Określ częstość zmian
Wyszukaj pliki, które ulegają najczęstszym zmianom. Następnie zidentyfikuj „hot spoty”, czyli te obszary, które są regularnie modyfikowane. Mogą to być fragmenty kodu, które wymagają ciągłego dostosowywania do nowych wymagań.
2. Zbadaj złożoność
Zastosuj naiwną heurystykę, która zakłada, iż większe pliki mogą być bardziej złożone i trudniejsze do zrozumienia. Warto zaznaczyć, iż choć analiza liczby linii w każdym pliku jest naiwną miarą złożoności kodu, to jednocześnie jest to prosty, szybki sposób na uzyskanie ogólnej perspektywy. W rzeczywistości, złożoność kodu może być oceniana przez różnorodne, bardziej wysublimowane metryki, takie jak ilość wcięć, liczba gałęzi w strukturze warunkowej czy stopień zależności między modułami.
3. Zobrazuj wyniki
Stwórz mapę. Przykładowo każde koło reprezentuje jeden obszar. Rozmiar koła jest powiązany z liczbą linii kodu, który znajduje się w danym miejscu (może to być pojedynczy plik lub folder). Intensywność koloru uzależnij od częstości zmian, tj. intensywniejszy kolor dla plików zmieniających się często i/lub dla większych plików.
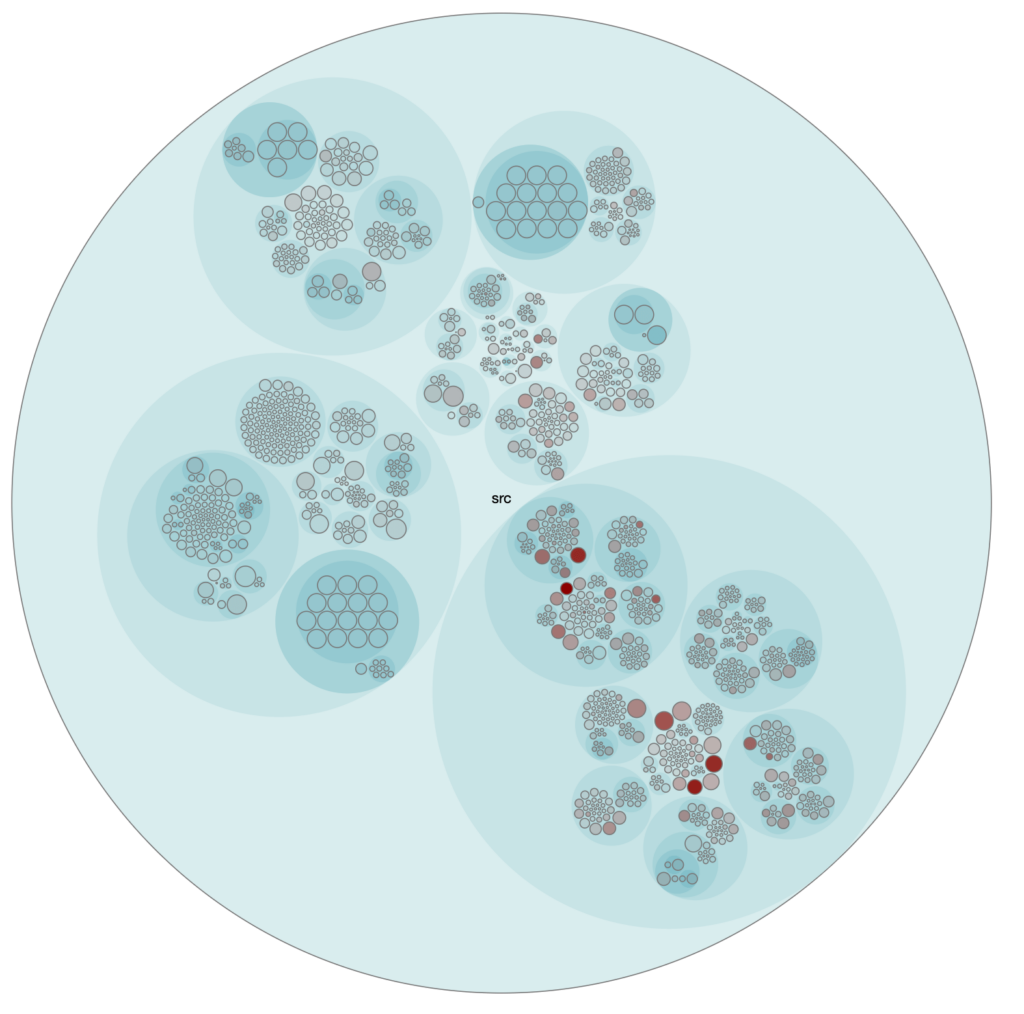 Obraz: Analiza hot spotów dla projektu MartenDB
Obraz: Analiza hot spotów dla projektu MartenDB4. Zweryfikuj “hot spoty”
Krytyczne spojrzenie na wyniki analizy oraz zdolność do rozpoznawania potencjalnych błędów, takich jak “false positive”, są najważniejsze w interpretacji mapy. Pamiętajmy o kilku ważnych aspektach:
Kontekst biznesowy
Zrozumienie kontekstu biznesowego i celów projektu pomaga zinterpretować, dlaczego dany plik jest duży i często się zmienia. Przykładowo, dopisywanie metod do fabryki obiektów może być zgodne z zamierzeniem projektowym.
Weryfikacja ręczna
Ostateczna ocena wymaga “ręcznej” weryfikacji kodu. Pomimo zaawansowanych narzędzi, pewne konteksty mogą wymagać ludzkiego zrozumienia.
Przemyślane decyzje
Wykorzystanie analizy jako narzędzia wspomagającego, a nie decydującego. Ostateczne decyzje o refaktoryzacji powinny być przemyślane i oparte na kompleksowej ocenie.
Powyższa mapa stanowi punkt wyjścia, który pomaga zidentyfikować obszary potencjalnego zainteresowania. Jednak jej interpretacja musi być elastyczna i uwzględniać kontekst oraz specyfikę danego projektu. Krytyczne spojrzenie jest najważniejsze dla skutecznej analizy. Stosowanie zasady Pareto w analizie historii commitów pozwala skupić wysiłki na kluczowych obszarach, generujących największy wpływ na projekt. Dzięki temu osiągamy największe korzyści przy minimalnym nakładzie pracy. Zaoszczędzony czas można z powodzeniem przeznaczyć na inne istotne cele.
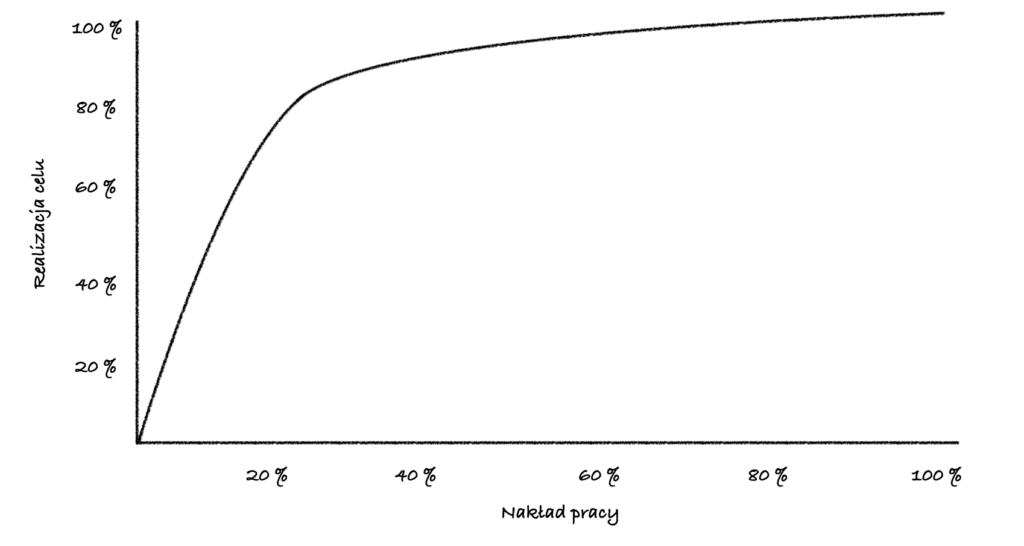 Wizualizacja reguły Pareto, nakładu pracy względem uzyskanych efektów
Wizualizacja reguły Pareto, nakładu pracy względem uzyskanych efektówOwnership
Kolejnym ważnym aspektem jest aspekt socjalny. Posiadając dane na temat tego, kto kontrybuował do zmian w poszczególnych obszarach kodu, możemy stworzyć mapę przypisującą osoby o największej wiedzy w danym miejscu. Jest to istotne dla określenia tzw. Ownership, czyli odpowiedzialności za dany fragment kodu. Warto rozróżnić kilka rodzajów własności w zależności od kontekstu:
1. Całkowita wiedza w rękach jednej osoby
W przypadku, gdy tylko jedna osoba jest odpowiedzialna za dany fragment kodu, mamy do czynienia z jednoosobową własnością. Ta osoba ma pełną wiedzę na temat danego obszaru i jest odpowiedzialna za jego rozwój i utrzymanie.
2. Podział wiedzy między kilku deweloperów:
W niektórych obszarach kodu wiedza może być podzielona między kilku deweloperów. Każda z tych osób wnosi wkład w rozwój kodu w danym obszarze, choć może nie mieć pełnego zrozumienia całego modułu.
3. Kolaboratywny chaos:
Szczególnie w projektach open source, do danego fragmentu kodu może kontrybuować wiele osób. W takich przypadkach nie ma jednoznacznie określonej osoby odpowiedzialnej za dany obszar, a rozwój kodu odbywa się w sposób kolaboratywny.
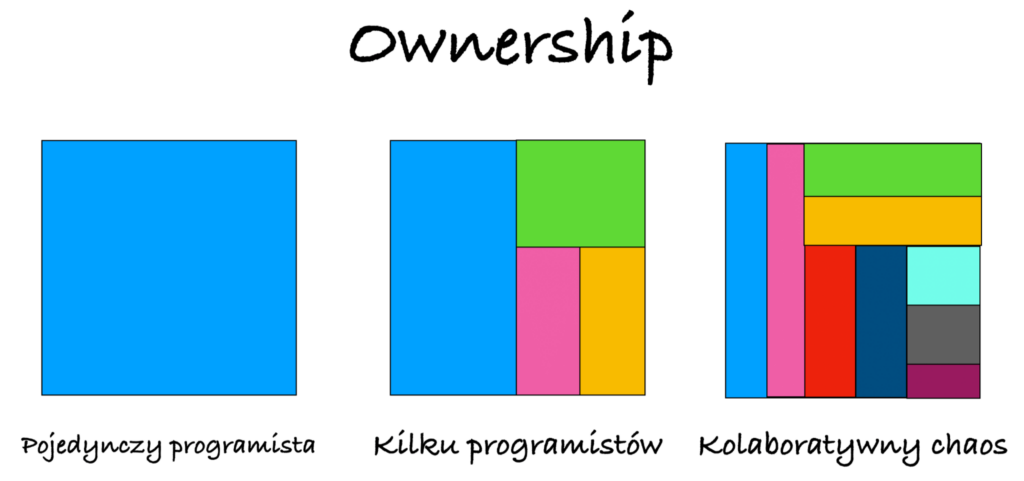 Przedstawienie różnych modeli Ownership
Przedstawienie różnych modeli OwnershipMając taką wiedzę jesteśmy w stanie przewidzieć, jaki będzie miało skutek odejście jeden z osób z naszego projektu. Pomoże nam to również zaplanować proces przekazania wiedzy w najefektowniejszy sposób.
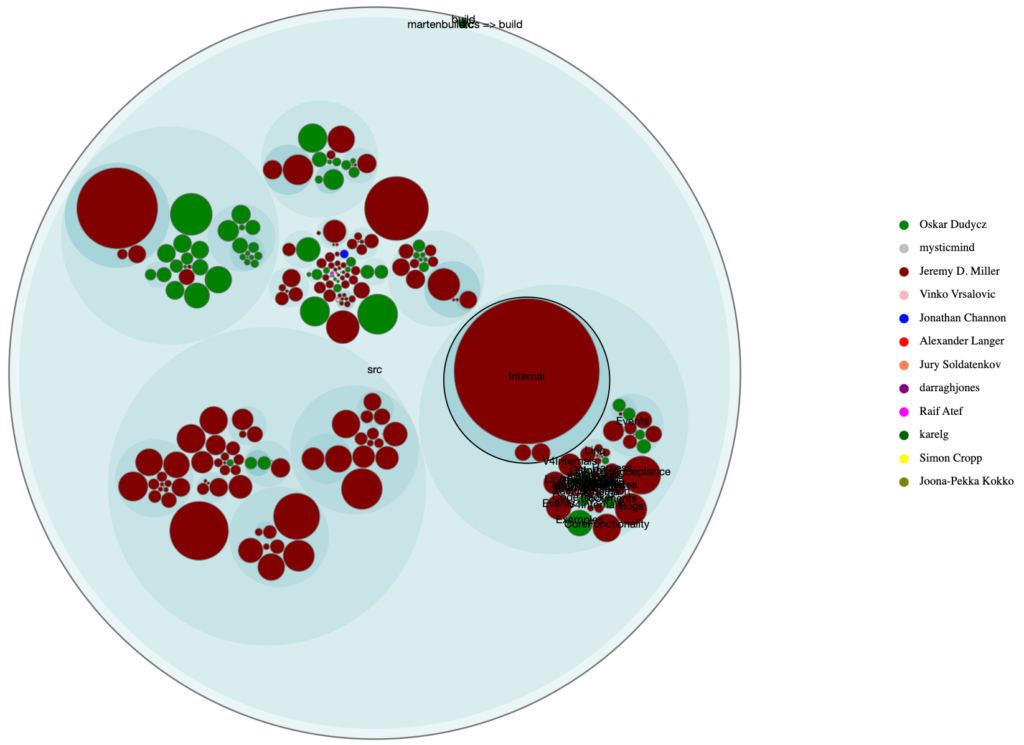 Obraz: Analiza ownership dla projektu MartenDB
Obraz: Analiza ownership dla projektu MartenDBWeryfikacja decyzji architektonicznych
Analizując zmiany w kodzie, możemy ocenić trafność podjętych decyzji architektonicznych. Możemy zauważyć, które pliki lub obszary kodu zmieniają się zawsze razem, co może wskazywać na ich silne powiązanie.
Analizując change coupling może mieć miejsce sytuacja, w której commit powoduje zmiany zarówno w CustomerRepository, jak i OrderService to może to oznaczać, iż naruszona jest enkapsulacja i warto wydzielić dodatkową klasę obszar, który będzie ja enkapsulował.
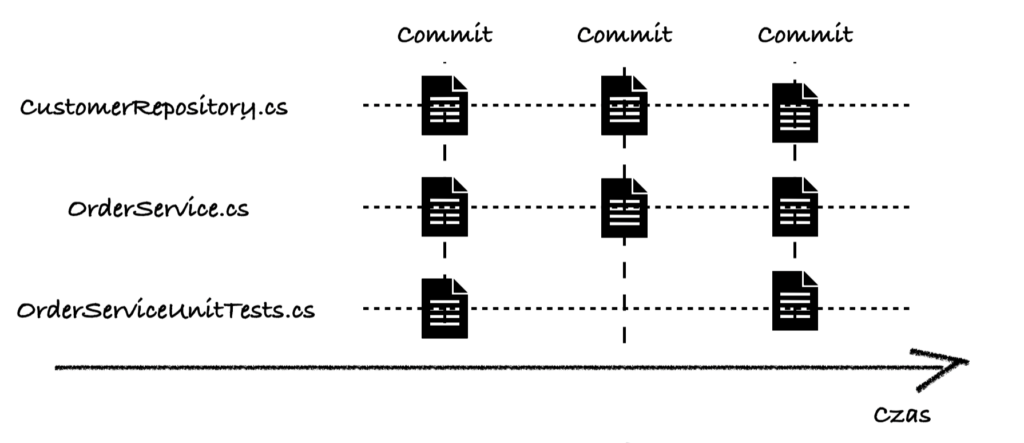 Analiza change coupling
Analiza change couplingWarto jednak podejść do tych obserwacji z krytycyzmem, ponieważ zmiany mogą wynikać z dodawania nowych funkcjonalności, co wymaga aktualizacji testów. Mimo to, warto zbadać ten obszar pod kątem możliwości poprawy jakości kodu i testów.
Podsumowanie
Prędzej czy później każdy z nas znajdzie się w projekcie, który można określić mianem legacy. Pomimo licznych obaw dotyczących jakości kodu i strachu przed wprowadzaniem w nim zmian, warto pamiętać o dziedzictwie, które niesie ze sobą kod źródłowy takiego systemu. Patrząc na istniejący kod, miejmy empatię. Prawdopodobnie podjęte decyzje nie zostały dobrze udokumentowane, możliwe iż otoczenie się zmieniło, przez co początkowa dobra decyzja nie wytrwała próby czasu. Starajmy się zrozumieć, co kierowało naszymi poprzednikami. Nie zapominajmy, iż zmiany wprowadzone przez nas, czy tego chcemy czy nie, również będą oceniane przez kolejnych programistów.
Przy wprowadzaniu zmian w kodzie legacy bądźmy pragmatyczni. Czasem po prostu lepiej jest wstrzymać chęć refaktoryzacji, dodać nowy fragment kodu i kontynuować pracę, niż przez wiele dni wprowadzać zmiany do modułu, który już nie będzie dalej rozwijany lub zostanie zastąpiony innym. Pamiętajmy, iż praca z systemami legacy to wyzwanie, ale także szansa na rozwijanie umiejętności i tworzenie bardziej zrównoważonego oraz łatwiejszego do utrzymania oprogramowania
Na koniec chciałbym zaznaczyć, iż powyższy artykuł powstał po lekturze książki Adama Tornhill “Your Code as a Crime Scene”. Serdecznie polecam lekturę osobom, które chciałby się bardziej zagłebić w temat analizy systemów legacy na podstawie historii zmian w systemie kontroli wersji.
Dodatkowe materiały:
- Your Code as a Crime Scene, Second Edition A. Tornhill (źródło),
- Software Design X-Rays, Fix Technical Debt with Behavioral Code Analysis A. Tornhill (źródło),
- Code-maat tool (źródło),
- Repozytorium kodu zawierające mój projekt (źródło).
Zdjęcie główne artykułu pochodzi z envato.com.








