
W tym poście przyglądniemy się kilku podstawowym operacjom biblioteki OpenCV.
Aby efektywnie przećwiczyć prezentowane metody, wymagany jest Jupyter Notebook, którego instalację opisałem tutaj.
[Ten post jest fragmentem serii "Krok po kroku" wprowadzającej do uczenia maszynowego (Machine Learning). Zapraszam do zapoznania się z całością.]
Co to za biblioteka?
OpenCV jest biblioteką zawierającą wiele standardowych operacji wykorzystywanych przy przetwarzaniu obrazów. Jej niebywałą zaletą jest fakt, iż implementacja jest bardzo wydajna i niektóre operacje potrafią być choćby 6x szybsze niż w innej popularnej bibliotece Pillow (PIL).
Taka wydajność nie ma znaczenia jak pracujemy z jednym obrazem, pamiętajmy jednak, iż ucząc modele sieci neuronowych w procesie nauki dostarczać będziemy wielu obrazów, często setek tysięcy. Każdy z nich musi być adekwatnie przygotowany - często wymaga to obróbki biblioteką graficzną - wówczas prędkość zaczyna mieć kolosalne znaczenie.
Format danych
Każdy obraz zapisany w pamięci w reprezentacji zgodnej z OpenCV to wielka macierz, gdzie każdy piksel widoczny w obrazie reprezentowany jest trzema składowymi kolorów R-red(czerwony) G-green(zielony) B-blue(niebieski).
Domyślny format obrazu składowe koloru (channels) przetrzymuje w odwrotnej kolejności, czyli BGR, co jest istotne przy pracy z innymi bibliotekami.
Przyglądając się własności .shape elementu macierzy zobaczymy, ze jego format to (H,W,C) [H-height, wysokość; W-width, szerokość, C-kanały (channels)).
Każda składowa koloru (R,G,B) przyjmuje wartości w przedziale [0,255] i reprezentowana jest daną typu 'uint8' (unsigned int 8, bezznakowa wartość całkowita mieszcząca się na 8 bitach).
Instalacja
W linii komend należy zainstalować pakiet, wpisując:
pip3 install opencv-pythonJest to krok, który był już wcześniej wykonany w poście 'Konfiguracja środowiska', więc najprawdopodobniej ta komenda wypisze tylko, iż biblioteka jest już zainstalowana.
Import bibliotek
Zaimportujmy 3 biblioteki, z których korzystać będziemy przy kolejnych przykładach.
import cv2 import numpy as np from PIL import ImageNowy, czysty obraz
Pamiętając, iż obraz to tylko macierz stwórzmy obraz o wysokości 100 i szerokości 150 jako macierz z samymi zerami, co przy użyciu biblioteki numpy wygląda tak:
img = np.zeros((100,150,3), dtype='uint8')zeros oznacza stworzenie macierzy z zerami - efektywny obraz będzie czarny, gdyż wartości kolorów R, G i B wszystkie równe są 0.
Parametr dtype jest wymagany by poinformować bibliotekę numpy o żądanym formacie danych - domyślny jest inny: float.
Prezentacja obrazu w Jupyter Notebook
Mimo wbudowanej metody .imshow w OpenCV, nie polecaj jej używania w Jupyter Notebooku, gdyż często powoduje problemy z "zawieszającym się" oknem. W zamian proponuję używanie biblioteki PIL (Pillow) tylko na potrzeby prezentacji wyników.
Image.fromarray(img)PIL jest dodatkowo domyślnie zintegrowany ze środowiskiem Jupyter Notebook, przez co, gdy ostatnią operacją w bloku kody będzie obraz, zostanie on wyświetlony jako wynik.
 Jupyter Notebook, tworzenie i prezentacja obrazu
Jupyter Notebook, tworzenie i prezentacja obrazuOtwieranie obrazu
Aby otworzyć obraz z dysku (jpg, png czy inny) należy wykorzystać metodę imread:
img = cv2.imread('image2.jpg')posługując się umiejętnościami wyświetlania otrzymujemy:
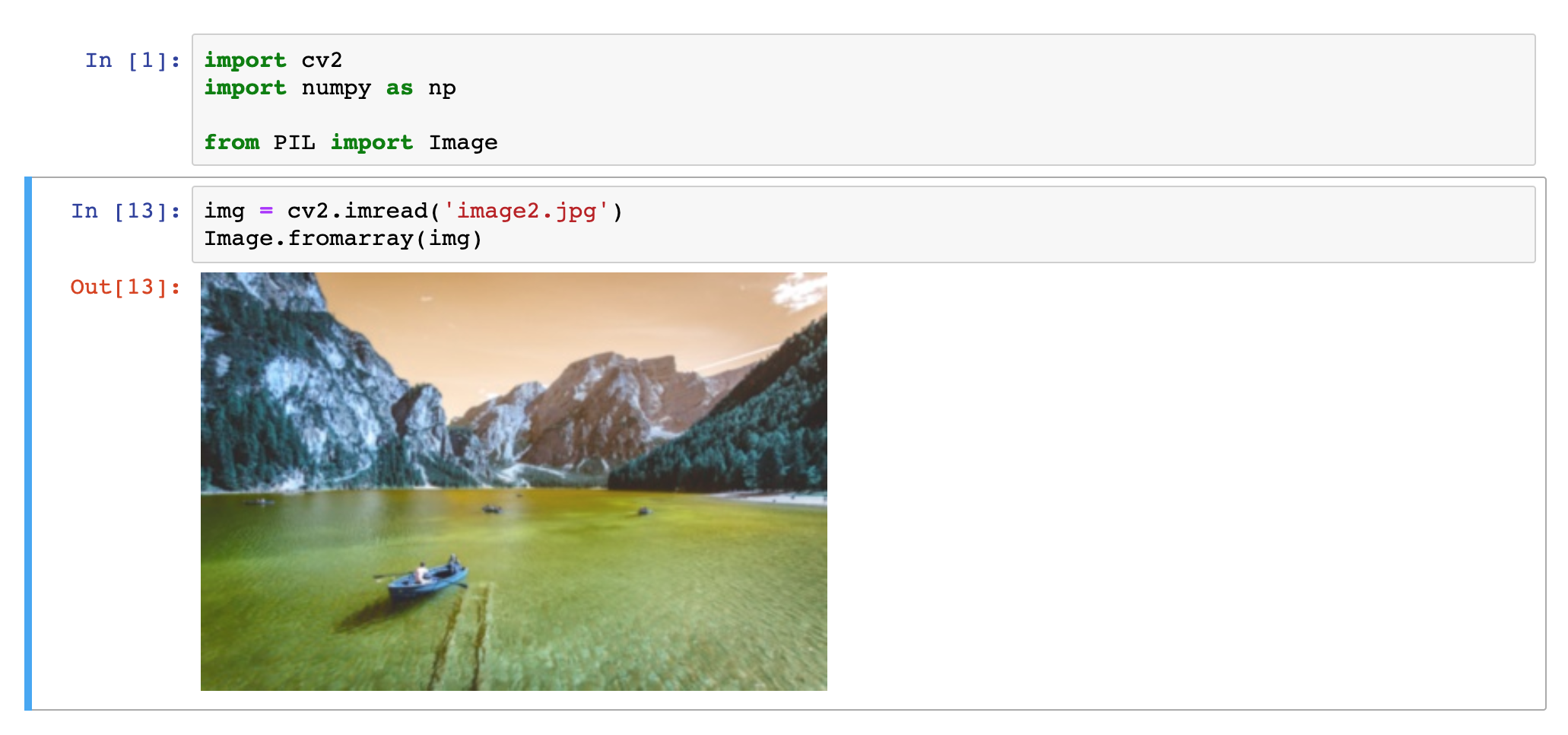 Otwieranie obrazu
Otwieranie obrazuJak na dłoni widać, iż coś jest nie-tak z kolorami. To jest właśnie ta niekompatybilność kolejności kanałów. Możemy je odwrócić na dwa sposoby.
Sposób 1: odwrócenie kolejności w macierzy na ostatniej osi (osi kanałów):
img = img[...,::-1]dla tych którzy teraz pytają "co tu się dzieje?" odpowiadam w osobnym poście.
Sposób 2: użycie wbudowanej funkcji konwertującej OpenCV:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)Osobiście używam pierwszej opcji:
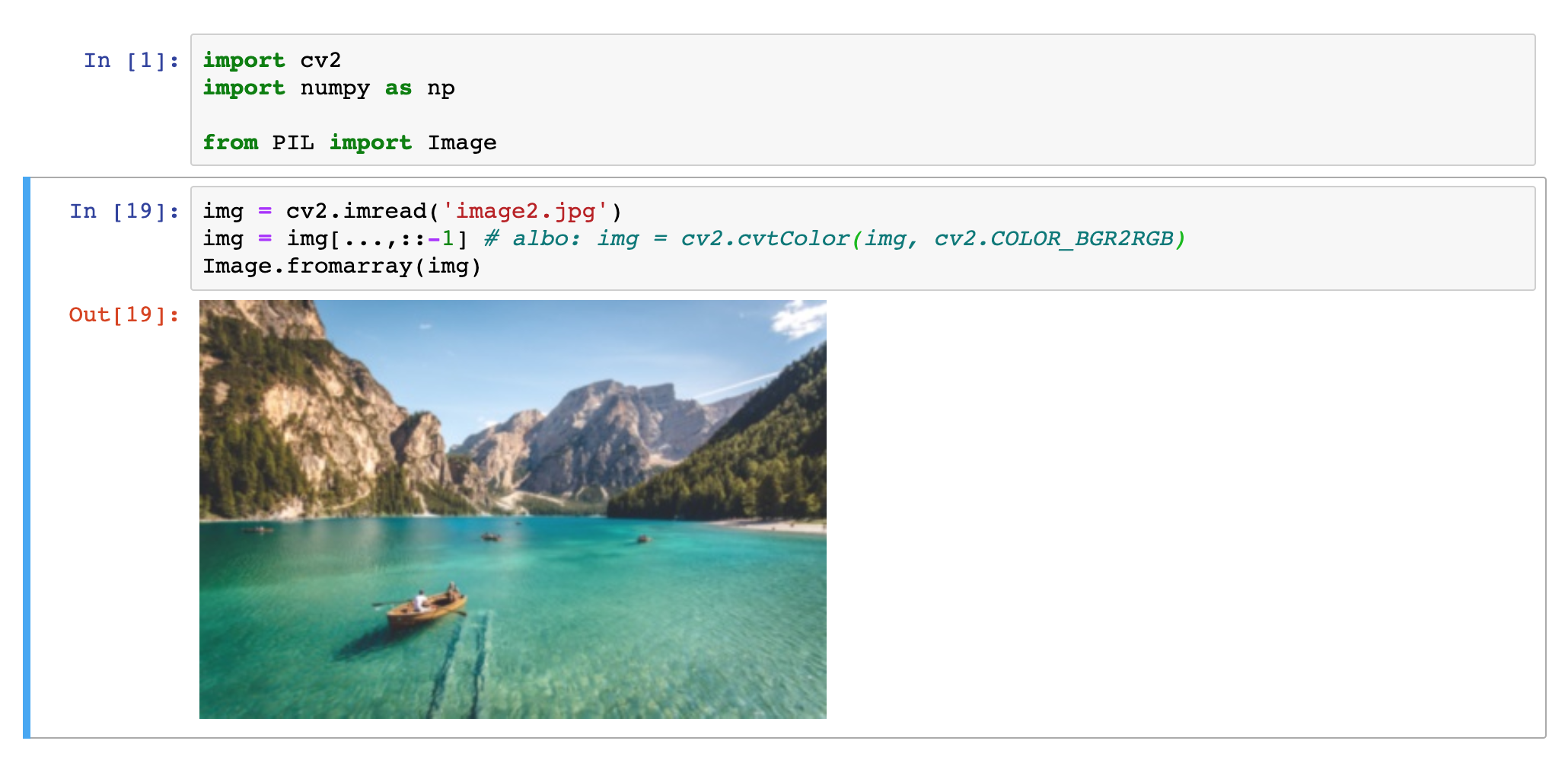 Odwracanie kanałów w numpy (BGR->RGB)
Odwracanie kanałów w numpy (BGR->RGB)Zapisywanie obrazu
Aby utrwalić obraz zapisany w pamięci używamy konstrukcji:
cv2.imwrite('save.jpg', img)Biblioteka jest na tyle sprytna, iż na podstawie rozszerzenia pliku (tutaj .jpg) sama zapisze dane we adekwatnym formacie.
Pobieranie klatki z kamery
By pobrać obraz z kamery należy wykonać trzy operacje:
- inicjacja pobierania klatek: cv2.VideoCapture(device_id)
- pobranie zdjęcia: cap.read() - tutaj radzę pobrać więcej niż jedną klatkę gdyż przy pobieraniu pierwszej klatki sterownik kamery nie dokonał jeszcze kalibracji ekspozycji i obraz może być za jasny bądź za ciemny.
- zaprzestanie pobierania klatek: cap.release()
w kodzie wyglądać to może następująco:
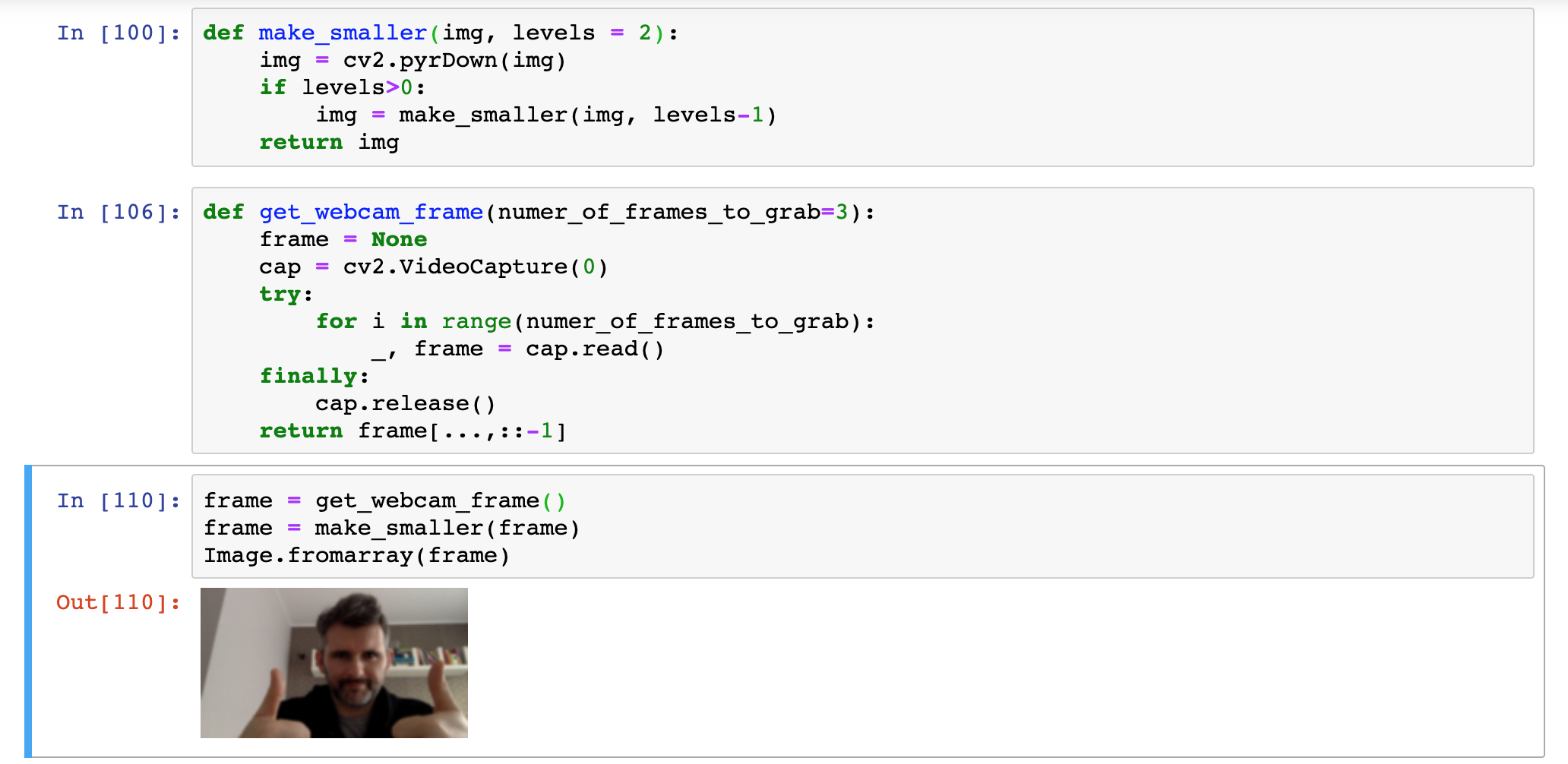 pobieranie klatki z kamery
pobieranie klatki z kameryWycinanie fragmentu zdjęcia
Wycinanie fragmentu zdjęcia to tak na prawdę operacja wycięcia fragmentu macierzy. Chcąc wyciąć lewy górny kwadrat o wielkości 20x20 pikselu wystarczy zrobić:
img = img[0:20, 0:20, :]Przykład:
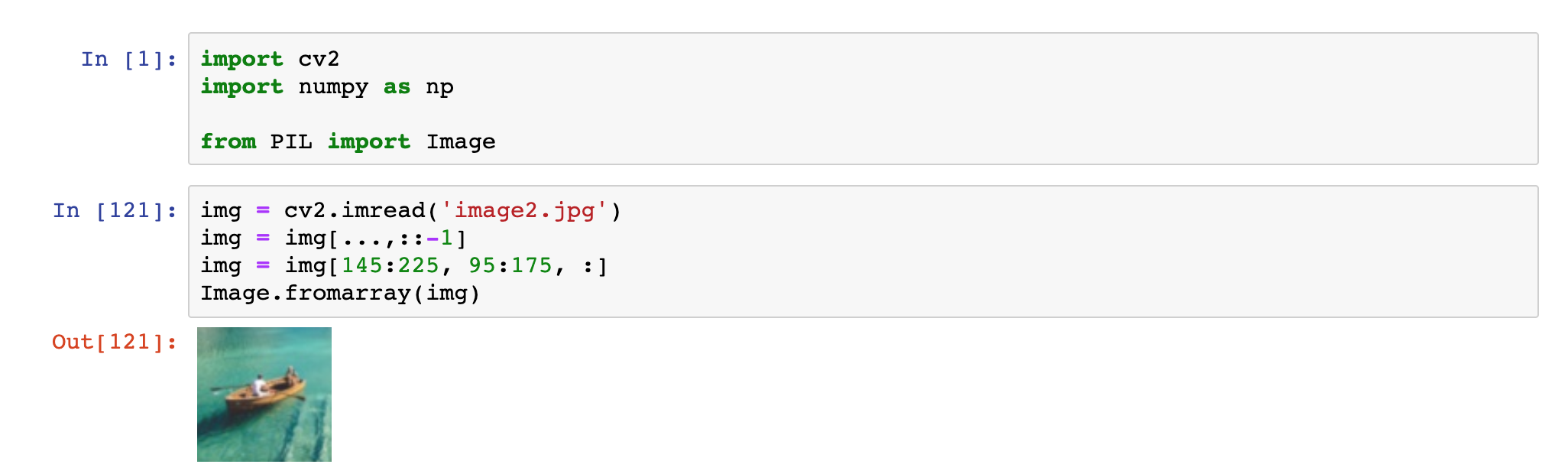 Wycięcie fragmentu zdjęcia (oryginalne zdjęcie widoczne kilka przykładów wyżej)
Wycięcie fragmentu zdjęcia (oryginalne zdjęcie widoczne kilka przykładów wyżej)Rysowanie linii
Definicja funkcji rysowania linii zawiera parametry:
- obraz, na którym rysujemy
- punkt startu (x,y)
- punkt końca (x,y)
- kolor jako krotka (tuple) : (r,g,b)
- grubość
ale trzeba uważać:
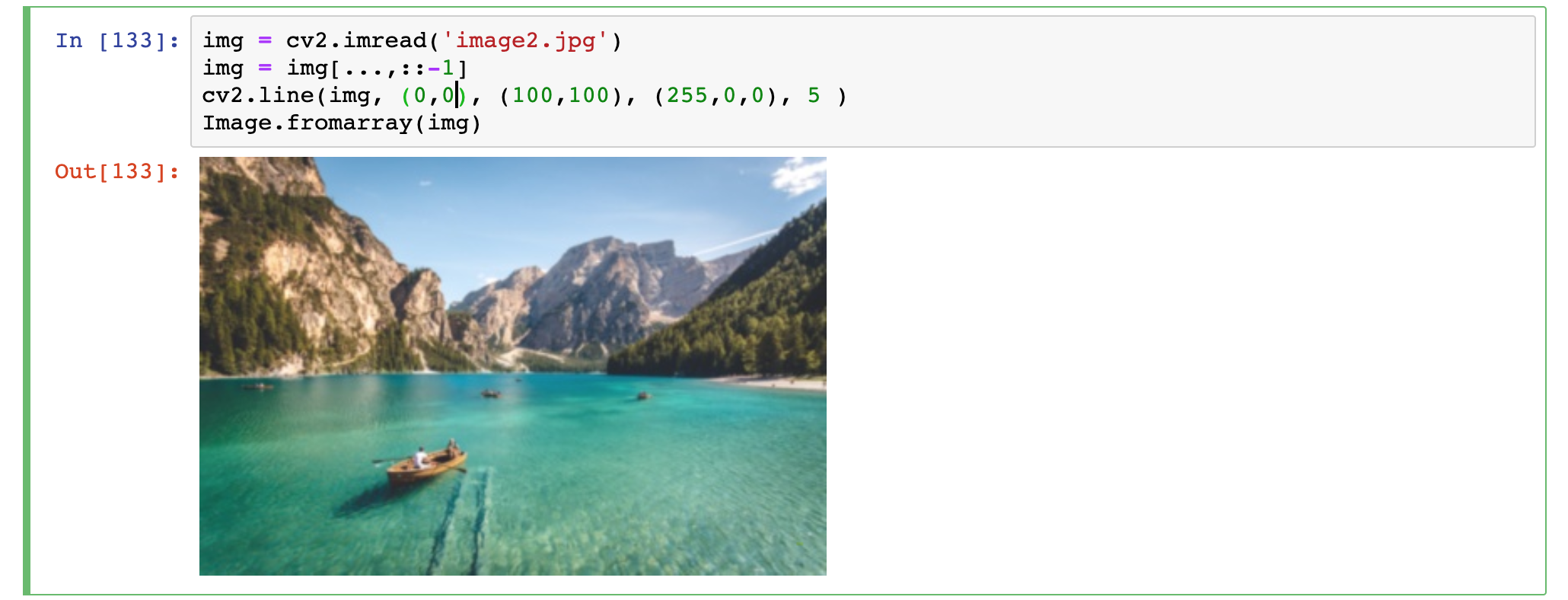 Niedziałające rysowanie linii
Niedziałające rysowanie liniigdy zdarzy się, iż linia się nie rysuje powodem może być niekompatybilność przekazywanego typu obrazu. Konwersja BGR->RGB dzięki numpy jest bardzo szybka, gdyż nie materializuje kopii pamięci jedynie odwrotnie przekazuje dane, o ile ktoś po nie sięga. Takiego typu OpenCV nie akceptuje więc należy zrobić jawną kopię i wówczas wszystko jest ok:
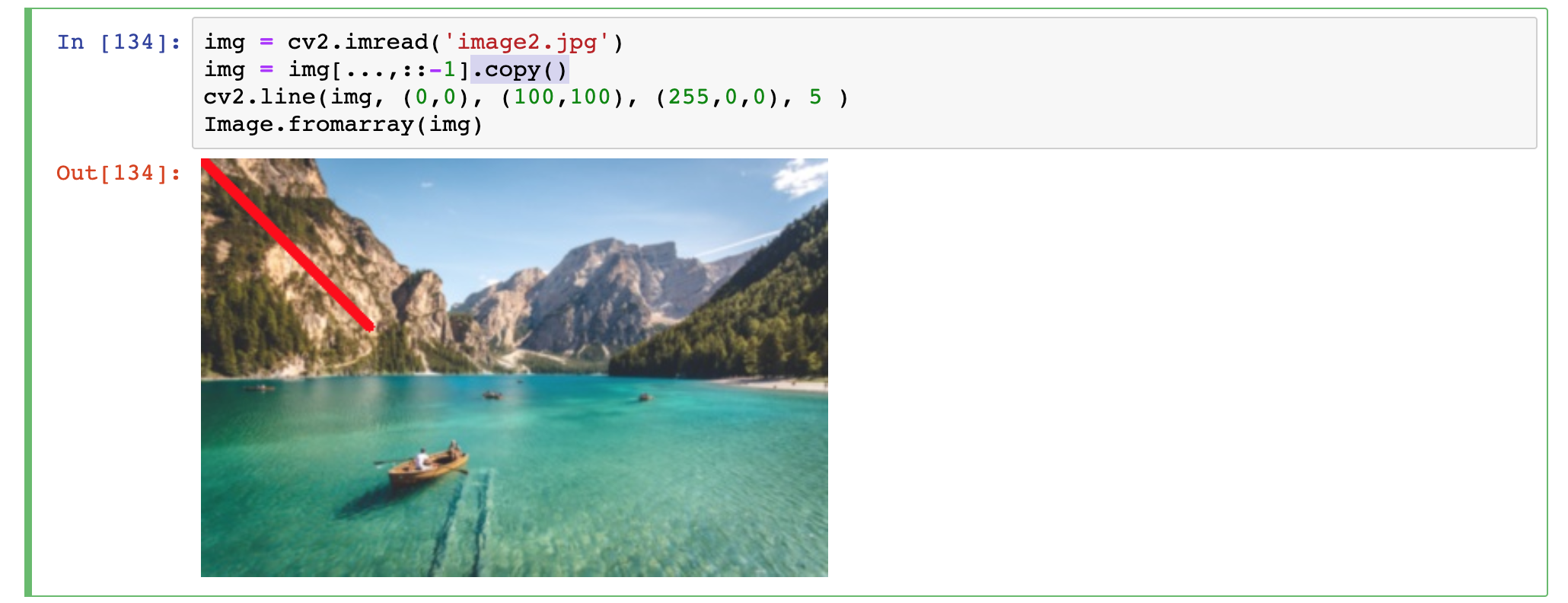 Poprawne rysowanie linii
Poprawne rysowanie liniiRysowanie okręgu
By narysować okrąg należy znać jedynie proste definicję funkcji circle; przyjmuje ona parametry:
- obraz, po którym rysujemy
- punkt środka (x,y)
- promień
- kolor
- grubość linii
Przykład:
cv2.circle(img, (100,100), 50, (255,0,0), 5)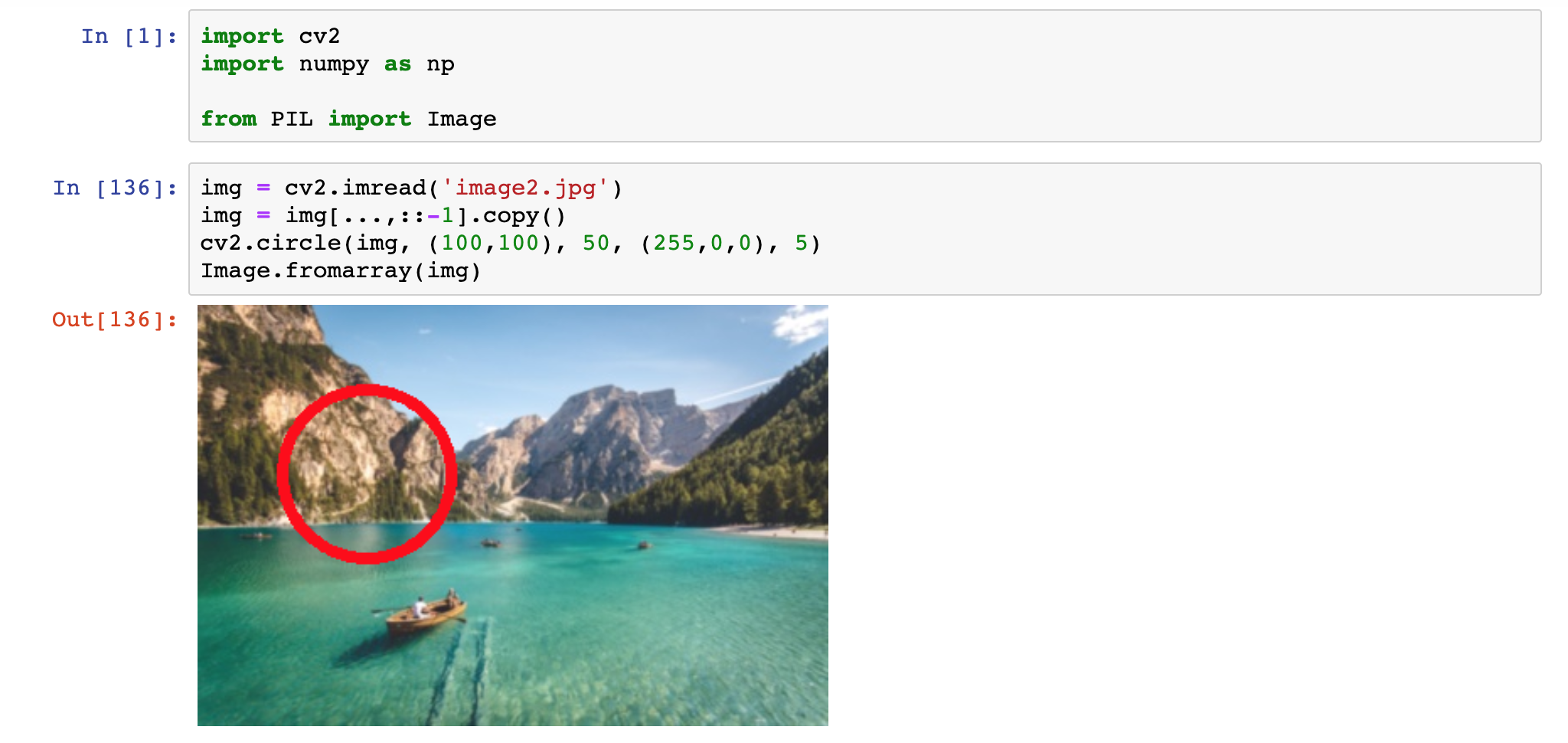 Rysowanie okręgu
Rysowanie okręguRysowanie prostokąta:
Prostokąt rysujemy używając metody rectangle z parametrami:
- obraz, po którym rysujemy
- punkt lewego górnego wierzchołka
- punkt prawego dolnego wierzchołka
- kolor
- grubość linii
Przykład:
cv2.rectangle(img, (10,10), (100,100), (255,0,0), 5 )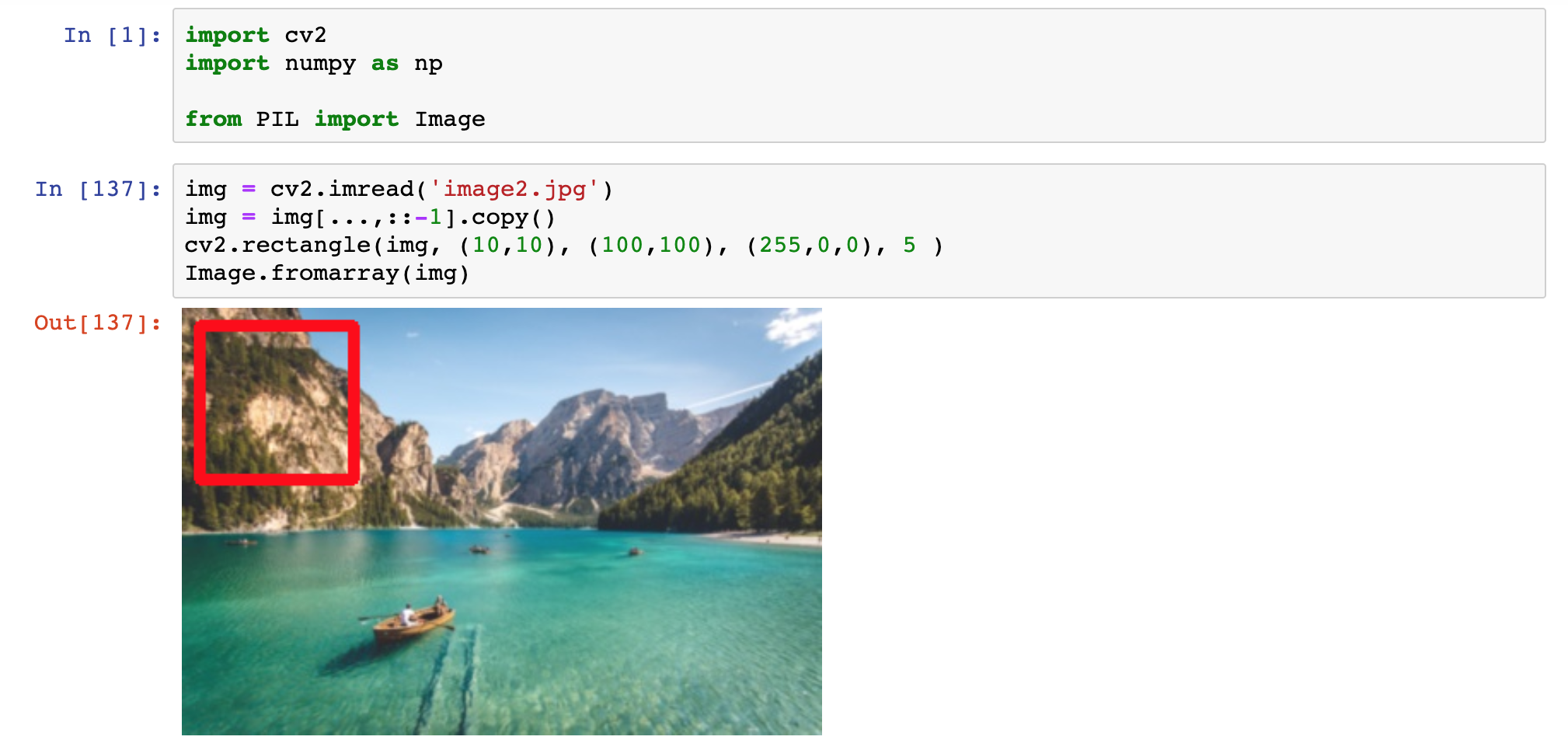 Rysowanie prostokąta
Rysowanie prostokątaWypisywanie tekstu
By napisać coś na obrazie należy użyć metody putText z parametrami:
- oprac, na którym piszemy
- tekst
- punkt określający lewy dolny puknt położenia tekstu
- czcionkę (jedną ze zdefiniowanych w OpenCV)
- skalę/rozmiar czcionki
- kolor
Przykład:
cv2.putText(img, "AIVision", (5,240), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0,255,200))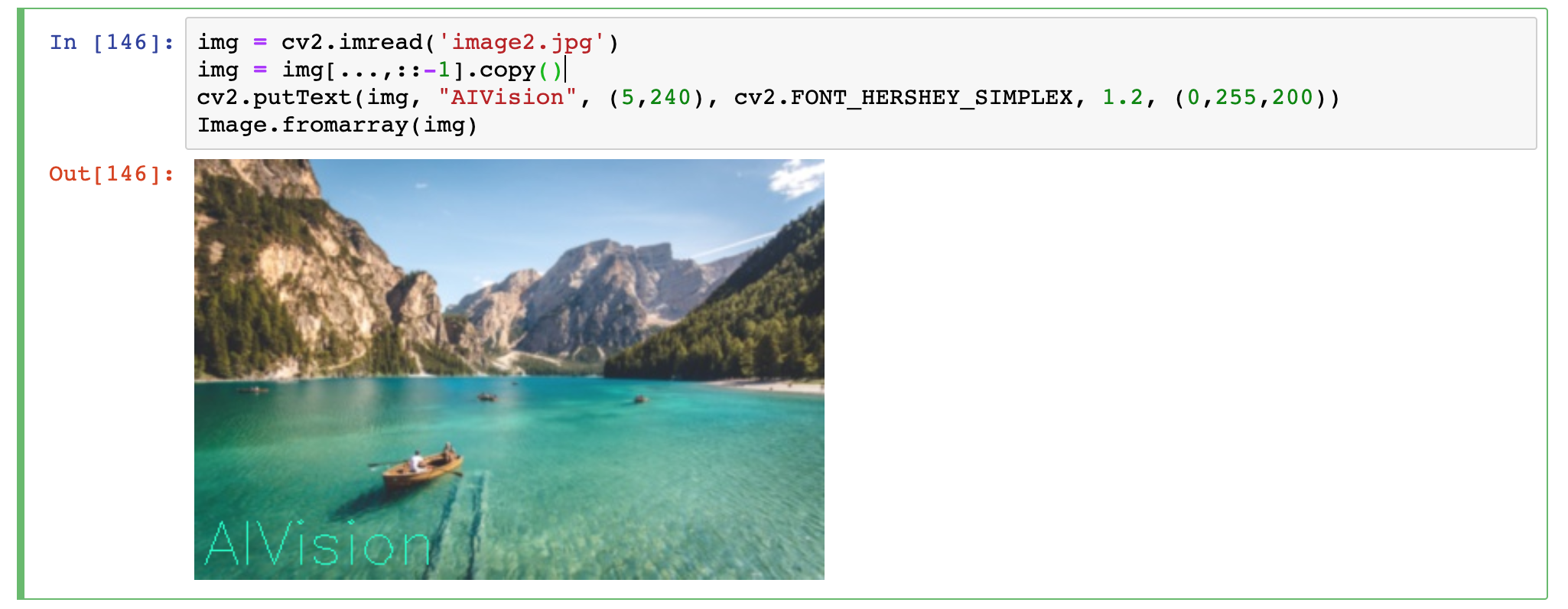
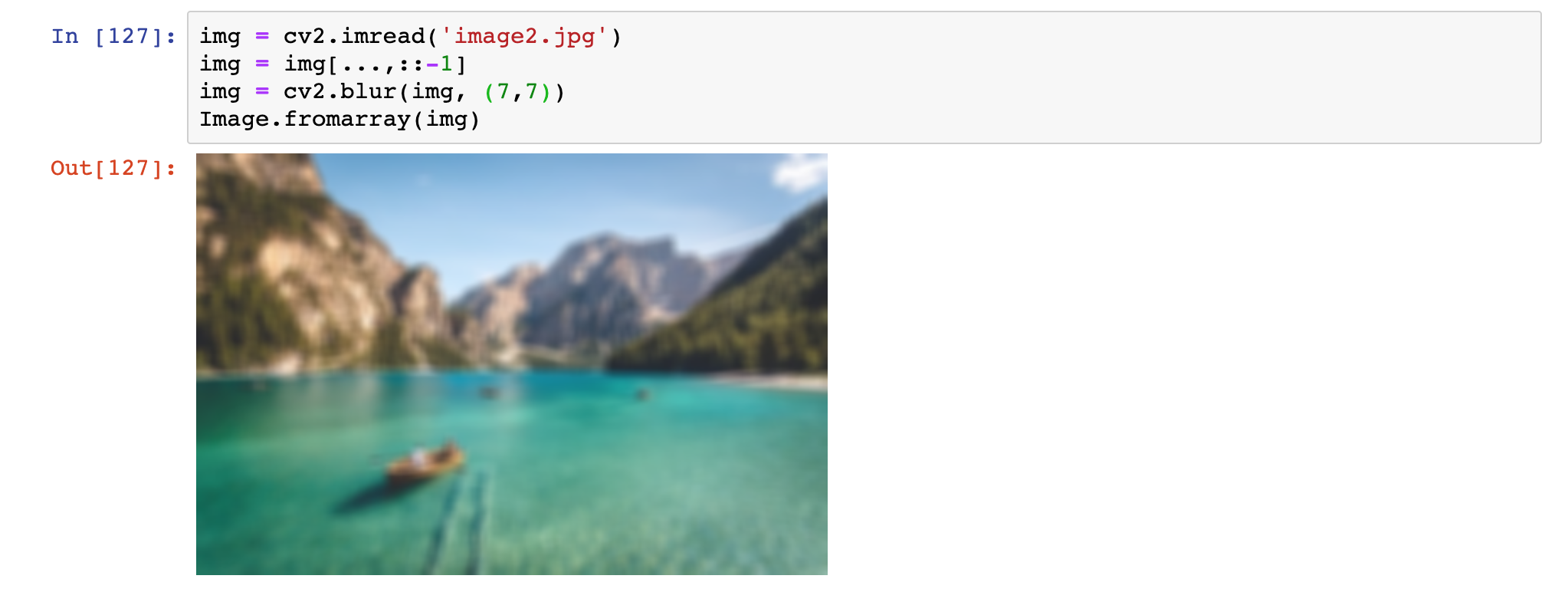
Rozmazywanie(Blur)
By rozmazać zdjęcie, należy użyć funkcji blur. Jako jeden z parametrów przyjmuje wielkość kernela, co efektywnie oznacza siłę rozmycia:
img = cv2.blur(img, (7,7))Przykład:









{kind=link}
{kind=link}