We wczorajszym wpisie przedstawiłem krótko JavaScript, swoisty język programowania internetu.
Mówiąc prosto: jest osadzony w stronach internetowych, które przeglądamy. Zapewnia im interaktywność, ale oprócz tego może podpytywać naszą przeglądarkę o dość konkretne informacje. A potem wysyłać je stronie, z której przybył. A choćby obcym stronom.
Poprzednio pokazałem, iż może odczytywać prawie wszystkie informacje opisane we wpisach 1-8 z tej serii. Czyli dane z tak zwanych nagłówków HTTP, swoistej wizytówki naszej przeglądarki.
W tym wpisie natomiast przejdę do rzeczy, których dotąd nie było i które może sprawdzić tylko JavaScript. W sposób bardzo prosty, często jedną linijką kodu.
 Krótko
Krótko
Jeśli przyszliście tu po rozwiązania, a nie szczyptę wiedzy, to służę :smile:
Pobieracie dodatek uBlock Origin. Włączacie w jego ustawieniach blokowanie JavaScriptu.
Niektóre strony nie będą wtedy działały, to nieuniknione. Gdy na taką traficie, wyłączacie blokowanie i ją odświeżacie.
Spis treści
- Życiowy przykład
-
Różne oblicza śledzenia
- Wymiary ekranu
- Śledzenie myszki i klawiatury
- Pamięć i liczba rdzeni procesora
- Poziom naładowania baterii
- Informacje o sieci
- Łączenie danych
-
Jak się przed tym chronić?
- Całkowite wyłączenie JavaScriptu
- Korzystanie z publicznych komputerów
- Wtopienie się w tłum
- Sprytniejsze otwieranie narzędzi przeglądarki
- LibreJS i inne opcje pośrednie
Życiowy przykład
Wyobraźmy sobie, iż przeglądamy właśnie jakąś popularną stronkę od zakupów online; własność wielkiej, ale kontrowersyjnej firmy. Robimy to ze swojego własnego konta, pod które są podpięte nasze dane osobowe.
Nagle nachodzi nas ochota na sprawdzenie, czy w serwisie znajdziemy ogłoszenia dotyczące bardziej kontrowersyjnych rzeczy (jakich? Zostawiam wyobraźni).
Nie chcemy, żeby strona wiedziała czego szukaliśmy. Może po rozpoznaniu u nas pewnych zainteresowań bombardowałaby nas reklamami. Albo może słyszeliśmy, iż lubi takie informacje sprzedawać ubezpieczycielom, którzy by nas za to wpisali na czarną listę. Jak w USA.
A wcześniej czytaliśmy Ciemną Stronę i wiemy, jak wścibskie potrafią być korporacje. Znamy też parę sposobów na zachowanie prywatności.
Zatem uruchamiamy całkiem nową, nieużywaną dotąd przeglądarkę, z czystymi ustawieniami. Nasz system operacyjny jest popularny, wiele osób go ma. Łączymy się przez VPN-a, żeby zmienić adres IP. Dla pewności włączamy tryb incognito.
Zmieniliśmy wszystko poza komputerem. Uff. Wchodzimy na naszą stronę aukcyjną i zaczynamy szukać.
Gdyby świat kończył się na informacjach z nagłówków HTTP, omawianych do tej pory, to bylibyśmy bezpieczni. Ale istnieje JavaScript.
Jest tym, co może sprawić, iż informacje i tak trafią do naszych wirtualnych akt. choćby gdy jedyną rzeczą łączącą wyszukiwania tajne z jawnymi było urządzenie.
Zapnijcie pasy, będzie groźnie :smiling_imp:

Jeśli chcecie sprawdzić, co JS wie na temat waszej przeglądarki, możecie to zrobić np. przez stronę BrowserLeaks.
Różne oblicza śledzenia
Sposób, w jaki JavaScript może podpytać o adekwatności systemu, opisałem w poprzednim wpisie. Żeby się nie powtarzać: najczęściej po prostu odnosi się do obiektu navigator, który każda przeglądarka udostępnia. Tam może znaleźć wiele ciekawych informacji.
Wymiary ekranu
JavaScript może odczytywać zarówno wymiary całego ekranu, jak i obszaru, na którym wyświetlana jest strona (to drugie zwykle pod nazwą viewport). Są podane w pikselach, w formacie szerokość × wysokość.
Nawet wymiary całego ekranu, zwykle powtarzalne (pełno 1920×1080 itp.), mogą być ciekawym sygnałem. jeżeli używamy nietypowego monitora (szerokokątnego, pionowego…), to w jakiś sposób się wyróżniamy.
Jeśli dorzucimy do tego wymiary okna, to już robi się bardzo ciekawie. Porównując je z całym ekranem, JS byłby w stanie rozpoznawać niestandardowe ustawienia.
Wymyśliłem na poczekaniu pewien przykład. Mianowicie: wiele systemów operacyjnych (Windows, Linux Mint…) ma w dolnej części ekranu nieruchomy pasek z opcjami.
JavaScript może spojrzeć na różnicę między wysokością okna a wysokością ekranu. W tej różnicy wysokości zawiera się nasz dolny, systemowy pasek, a także pasek górny przeglądarki.
Ale wysokość paska od przeglądarki zwykle jest standardowa! JS może sprawdzić w jakiejś bazie paski typowe dla naszej przeglądarki, w końcu ją zna. A po odjęciu wymiarów przeglądarkowych zostanie wysokość naszego dolnego, systemowego paska.
Jeśli jego wysokość nie pasuje do typowych wartości – również zebranych w jakiejś bazie – to może trafić do naszej „teczki” jako cecha szczególna.
Wysokość strony jest u nas równa lub prawie równa wysokości ekranu? To by świadczyło o tym, iż nie mamy żadnego paska. Albo ustawiliśmy sobie, żeby się chował. Odeszliśmy od ustawień typowych dla systemu, wyróżniamy się.
JavaScript może wyłapać kolejne anomalie, porównując wymiary pasków wewnątrz naszej przeglądarki z tymi typowymi. Mamy schowany pasek boczny, obecny u większości użytkowników danej przeglądarki? Wyróżniamy się.
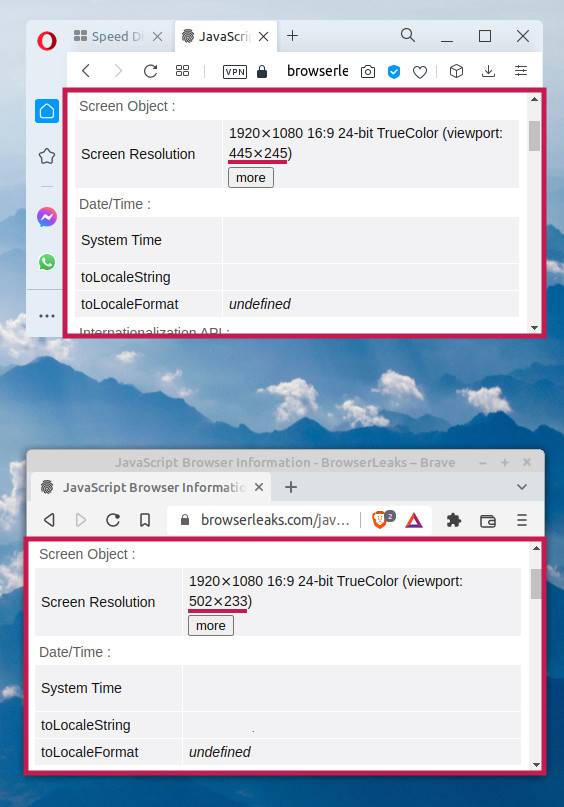
Okna dwóch przeglądarek, Opery i Brave’a. Choć ich granice mają podobne wymiary, w Operze obszar strony jest mniejszy. Przez pasek boczny.
Inny przykład – wykrywanie, czy otwarliśmy narzędzia przeglądarki.
Kiedy otwieramy te narzędzia, żeby zajrzeć stronce w bebechy, to w domyślnym trybie wysuwają się z dołu, zmniejszając obszar wyświetlanej strony.
JavaScript może wypatrywać takich zmian i odgadnąć, co właśnie otwieramy. Nie jest to zresztą teoria – na Githubie wprost znajdziemy projekt, który oferuje takie możliwości. Dość popularny, ponad 1700 gwiazdek.
Otwieranie narzędzi może być dla szpiegowskiej strony sygnałem, iż zaraz sama będzie szpiegowana. Niektóre zmieniają swoje zachowanie, kiedy to wykryją. Chowają śledzący JavaScript, żeby wyglądać niewinnie.
Śledzenie myszki i klawiatury
JavaScript może śledzić ruchy kursora naszej myszy. I wie, co nacisnęliśmy na klawiaturze.
Najpierw uspokoję: skrypt ze strony A nie jest w stanie odczytać informacji wpisywanych na stronie B, jak hasło do konta bankowego.
Ale i tak może robić wredne rzeczy na tej stronie, na której się znajduje. Jak choćby przechwytywanie i neutralizowanie klawiszy PrintScreen (żebyśmy nie mogli robić zrzutów ekranu) albo Ctrl+C (żebyśmy nie mogli niczego skopiować).
Wyżej wspomniałem o tym, iż po rozmiarze okna strona może poznać, czy ktoś otworzył narzędzia przeglądarki. To samo może odgadnąć, wypatrując kombinacji Ctrl+Shift+I, która je otwiera.
Dlatego, jeżeli ktoś chce dyskretnie otworzyć narzędzia przeglądarki, najlepiej przeklikać się myszką przez opcje. Śledzenie myszy nie sięga bowiem poza obszar strony.
A jeżeli chodzi o szpiegowanie użytkowników?
Stronka mogłaby trzymać listę typowych skrótów klawiszowych dla danej przeglądarki. jeżeli ktoś często używa kombinacji niestandardowych, to mogłaby to sobie zapisywać – sam na przykład mam niestandardowy skrót, który sobie ustawiłem do usuwania elementów (funkcja dodatku uBlock Origin).
Wróćmy do przykładu z początku wpisu – chcę poszukać czegoś bardzo osobistego na stronie, na której często bywam. Otwieram nowe okno w trybie incognito i zmieniam adres IP (np. przez opcje Opery).
Jeśli z przyzwyczajenia użyję swojego nietypowego skrótu klawiszowego, to strona może sprawdzić w zapisanych informacjach, czy ktoś z zarejestrowanych użytkowników tak robił. Też jest z Polski i niedawno wylogował się z konta? Ups, mają mnie.
Inne nieoczekiwane zastosowanie śledzenia klawiatury? Istnieją formularze, które wysyłają wpisywany tekst na bieżąco. Zanim w ogóle klikniemy „Wyślij”. Rzekomo po to, żeby obsługa klienta mogła szybciej reagować.
W związku z tym protip dla osób, które mają w zwyczaju pisać wiadomość na brudno („czy was tam poje…”), a potem ją kasować i pisać coś bardziej wyważonego („Dzień dobry, piszę w związku z…”).
Brudnopisem szanującym prywatność są programy w stylu Notatnika :wink: Nie internetowe formularze.
A ruchy kursora myszki czy analiza stylu pisania to tematy na osobny wpis. Potwierdzę tylko: tak, dużo o nas zdradzają.
Pamięć i liczba rdzeni procesora
Informacje z naszej internetowej „wizytówki” ukazują co najwyżej przeglądarkę i system operacyjny. JavaScript umie sięgnąć głębiej.
Pierwsza rzecz to zmienna navigator.deviceMemory. Wyraża ilość pamięci RAM w naszym komputerze i jest podana w gigabajtach.
Chrome i inne przeglądarki na silniku Chromium to ujawniają, Firefox nie.
Kolejna sprawa: liczba rdzeni procesora. Zmienna navigator.hardwareConcurrency.
Zazwyczaj parzysta. Od 2 przy urządzeniach budżetowych do nawet 18 przy hardkorowych. A wciąż mówimy o procesorach na rynek konsumencki; procesory robione pod serwery miałyby tego jeszcze więcej.
Większa liczba rdzeni i pamięci może być dla JavaScriptu mocną wskazówką na to, iż ma do czynienia z komputerem stacjonarnym. Pomijając już fakt, iż jakaś szemrana strona mogłaby na podstawie mocniejszego sprzętu uznać, iż trafił się klient do oskubania. I zaproponować wyższe ceny produktów.
Tę informację zdradzają wszystkie przeglądarki, które sprawdzałem. Chromium i Opera bez zaskoczenia. Ale Brave i Firefox, reklamujące się szanowaniem prywatności, również.
Ciekawostka
Niektórych może zaskoczyć liczba rdzeni w telefonach. W słabszych laptopach miewamy zwykle od 2 do 4. Zaś przy telefonach – choćby tych tańszych – 8 nie jest niczym szokującym.
To dlatego, iż rdzeń rdzeniowi nierówny. W telefonach tylko niektóre rdzenie są mocniejsze i włączane przy cięższych zadaniach; reszta stawia na niskie zużycie energii. Taka architektura nosi nazwę big.LITTLE.
Jeśli ciekawi nas odrobina historii, to na forum HackerNews znajdziemy zażartą dyskusję z udziałem człowieka, który doprowadził do tego, iż przeglądarki ujawniają informację o liczbie rdzeni.
Jak sam wspomina w swoim wpisie, motywacją była próba lepszego dopasowania pewnej wymagającej aplikacji do możliwości systemu.
Pisze, iż JavaScript i tak mógłby zdobyć informację o liczbie rdzeni. Tylko iż nie wprost, ale przez mierzenie czasu, jaki zajmie komputerowi wykonanie pewnych wymagających obliczeń.
Jest w tym trochę racji; JavaScript mógłby dowiedzieć się wiele, choćby gdyby przeglądarka nie mówiła mu wprost.
Natomiast moim zdaniem dawny stan rzeczy przynajmniej niósł za sobą pewne konsekwencje. Procesor zaczynał buczeć, strona muliła; użytkownik mógł się zorientować, iż coś jest nie tak.
A teraz? JS dostanie swoje dane po cichu. Przeglądarki mogłyby przynajmniej pytać, czy chcemy ujawnić tę informację.
Poziom naładowania baterii
Zmienne ujawniające informacje o baterii to zbiorczo Battery Status API. Mówią o kilku rzeczach:
- czy nasze urządzenie jest aktualnie podłączone do ładowania;
- jaki jest poziom naładowania baterii (liczba z przedziału od 0 do 1, do dwóch miejsc po przecinku.
- jaki jest szacowany czas do pełnego naładowania/rozładowania baterii.
Zwolennicy ponownie twierdzą, iż to dla komfortu użytkowników. jeżeli mają słabą baterię, to strona nie włączy jakichś energożernych funkcji, zmniejszy rozdzielczość elementów i tak dalej.
Tylko iż takie spojrzenie zakłada pewną niesamodzielność użytkowników. Nie lepiej by było dać gdzieś pstryczek, którym mogą ograniczyć zasoby na własne życzenie? Naprawdę strony muszą to czytać same z siebie?
Poziom baterii potrafi być całkiem mocnym sygnałem łączącym ze sobą różne przeglądarki i adresy IP na jednym urządzeniu.
Wyobraźmy sobie: o pewnej godzinie po stronie X krążyło dość mało użytkowników. Jeszcze mniej – z ustawionym polskim językiem. I nagle jeden z tych Polaków zniknął ze strony, ale pojawił się inny, również z baterią na poziomie 37% i takim samym czasem do rozładowania. Kim on może być, no kim?
Przeglądarka Brave, choć zbudowana na tym silniku co Chrome, zataja informacje o baterii. Podobnie robi Firefox. Natomiast bardziej „konsumenckie” przeglądarki na bazie silnika Chromium ochoczo to ujawniają.
Informacje o sieci
Dostępne pod zbiorczą nazwą Network Information API.
Oprócz informacji o sprzęcie i baterii, JS może podpytać o jakość połączenia z internetem. Oficjalnego powodu możecie się domyślać – dla komfortu użytkowników! Żeby można było do nich dopasować zasobożerność strony. W praktyce to kolejne źródło informacji, którymi możemy się wyróżniać.
Podpytane przeglądarki mogą ujawnić między innymi przybliżony „poziom” sieci (3G, 4G…) oraz jej rodzaj (np. komórkową), aktualną i maksymalną przepustowość łącza w megabitach na sekundę (downlink i downlinkMax), czas pełnego obiegu danych (rtt, od round-trip time) oraz informację o tym, czy mamy włączony tryb oszczędzania danych (saveData).
Wyobraźmy sobie, iż zwykle korzystamy z wolnego mobilnego internetu, który często nam zmienia adres IP. Pewnego dnia odwiedzamy kogoś znajomego z wypasionym łączem szerokopasmowym.
Jeśli wejdziemy na swoje konto na wspomnianej wścibskiej stronie z zakupami, która dobrze nas zna, to szybkość naszego łącza w tym dniu będzie się wyróżniała.
Strona będzie miała pewność, iż podczas tej wizyty nie byliśmy u siebie. Pewność, której nie dałby jej sam adres IP, bo ten zmienia nam się często.
Ponownie: Brave i Firefox zatajają większość informacji z tej kategorii, przeglądarkowy mainstream ujawnia wszystko. Safari wyjątkowo z rigczem, zataja.
Łączenie danych
Na koniec zwróćmy uwagę na to, iż omawiane informacje nie występują w izolacji i można je łączyć w bardziej wyrafinowane kombinacje.
Jeśli z jakiejś strony korzystamy często, zalogowani na swoje konto, to JavaScript na dłuższą metę prześle o nas sporo danych. Właściciele strony mogą nas analizować. W dłuższym okresie wyłapią pewne typowe cechy.
Przykład? Załóżmy iż zwykle przeglądamy strony, korzystając z komórki podpiętej do większego monitora. Strona jest w stanie to wychwycić:
- o wymiary ekranu po prostu zapyta. Spore, ewidentnie nie komórkowe;
- z drugiej strony pamięć i liczba rdzeni nie powalają, co sugeruje słabsze urządzenie;
- do tego czasem zapomnimy wpiąć ładowarkę, a wtedy strona odczyta, iż ciągniemy z baterii.
- no i informacje o sieci mówią wprost: cellular.
Na tej podstawie trafimy do mało licznej przegródki „Preferencje: telefon + duży monitor”. Nie jest to sam w sobie jakiś unikalny sygnał. Ale jako wstępny odsiew albo sygnał wzmacniający sprawdzi się świetnie.
Nawet jeżeli się wylogujemy, zmienimy adres IP, parametry naszej komórki są typowe, zaś monitorów takich jak nasz jest wiele – możemy zostać rozpoznani. Dane z osobna nas nie zdradzają, ale ich połączenie już mocno zawęża krąg poszukiwanych.
Do tego chwilę przed tym, jak weszliśmy na stronkę anonimowo, z innego adresu IP, swoją aktywność na niej wstrzymał Adam Znany z tej samej rzadkiej przegródki.
Czyżbyśmy byli nim?
A żeby nie było, iż tu science-fiction tworzę – polecam odkrycie pewnego użytkownika pokazujące, ile informacji próbowało zebrać przez JavaScript popularne forum Reddit, prawdopodobnie korzystając z usług firmy HUMAN.
Niektóre z tych rzeczy to spoilery dotyczące przyszłego wpisu o JS-ie.
Jak się przed tym chronić?
Niuansów związanych z JavaScriptem jest multum. A przypominam, iż pisałem tutaj o tych najłatwiej dostępnych, które przeglądarka ujawnia sama.
Ogólnie powiem tak: to walka z wiatrakami.
Jasne, możemy łatać luki w naszej prywatności jedną po drugiej. Podsuwać stronom fałszywe informacje o naszym komputerze.
Ale firmy śledzące nie siedzą biernie i doskonalą metody inwigilacji; któraś w końcu może nas złapać na kłamstwie. A wtedy, zamiast zlewać się z tłumem, staniemy się szczególnie rozpoznawalni.
Również przeglądarki nie zawsze będą po naszej stronie. W ich interesie leży przede wszystkim, żeby ludzie ich używali. Zatem domyślnie będą blokowały dość zachowawczo, nie chcąc się narażać na późniejsze skargi, iż ludziom coś nie działa. I dodawały nowe, potencjalnie śledzące funkcje.
Ale to w żadnym razie nie znaczy, iż trzeba się poddać! Po prostu, zamiast łatać jedną lukę po drugiej, proponuję pójść w rozwiązania bezkompromisowe.
Całkowite wyłączenie JavaScriptu
Jesteśmy zwykłym użytkownikiem, który czasem chce zaznać trochę rozrywki. Czasem odwiedzamy też strony wścibskich amerykańskich korporacji. Nie chcemy ciągle być na bieżąco z metodami śledzenia, jak z jakimiś trendami w (tfu) modzie.
Ale równocześnie zgadzamy się z tym, iż byłoby fajnie żyć bez świadomości, iż jesteśmy pod lupą jakiegoś zbieracza danych.
Jeśli powyższy opis do nas pasuje, proponuję rozwiązanie łatwe, a skuteczne. Mieć domyślnie wyłączony JavaScript. I włączać go jednym kliknięciem, kiedy sytuacja tego wymaga. Ze świadomością, iż wtedy odwiedzana strona może poznać sporo naszych danych.
Powiem uczciwie: do włączania JS-a będziemy zmuszani dość często.
Bez niego czasem jakiś guzik wykona tylko połowę roboty po kliknięciu; to znowu podczas przewijania strony jej elementy się rozjadą (bo używała JS-a do ich ustawiania). Sposobów, w jakie coś może przestać działać, jest wiele.
Jeśli chodzi o sam sposób na wyłączanie – proponuję robić to dodatkiem uBlock Origin.
Polecałem go już przy paru poprzednich wpisach, stworzyłem też instrukcję instalacji. A skoro i tak warto go mieć, to możemy równie dobrze uczynić go naszym wyłącznikiem od JS-a. Działa też na mobilnym Firefoksie.
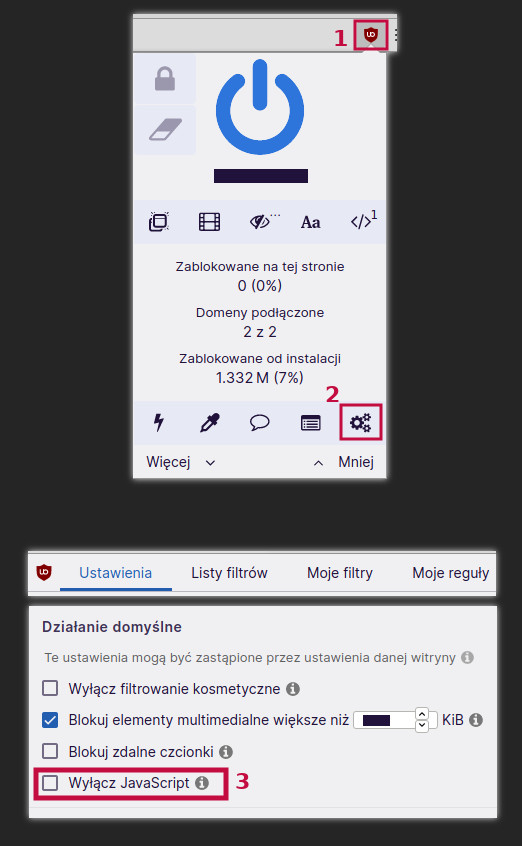
Przede wszystkim włączamy w ustawieniach, żeby JS był domyślnie blokowany. Najpierw wybieramy ikonę dodatku z górnego paska przeglądarki (warto go tam przypiąć), następnie klikamy ikonę zębatki (gdyby jej nie było, to klikamy Więcej, aż się rozwinie).
Otworzy się osobne okno z opcjami. Wybieramy z nich wyłączenie JavaScriptu.
A kiedy trafimy na stronę, która bez skryptów nam nie zadziała?
Klikamy ikonę dodatku, potem przekreślony znaczek z nawiasami ostrymi po prawej stronie. Gdy się “odkreśli”, to znaczy iż włączyliśmy JS-a. Powyżej pojawi się duży przycisk, który po kliknięciu odświeży stronę.

Przełączanie JS-a możemy również podpiąć w opcjach dodatku pod jakiś skrót klawiszowy.
Więcej informacji znajdziecie na stronie uBO.
Beztroskie surfowanie, a w razie czego kliknięcie dwóch rzeczy. Wiele osób sobie z tym poradzi.
Ale mniej „komputerowi” dziadkowie/wujkowie mogliby nie docenić naszej troski, gdybyśmy szykowali im przeglądarkę i domyślnie wyłączyli JS-a. Dlatego proponuję zrobić to tylko za ich zgodą i po krótkim przeszkoleniu.
Uwaga
Czasem po wyłączeniu JavaScriptu możecie zwątpić, czy na pewno się udało, bo niektóre animacje przez cały czas działają.
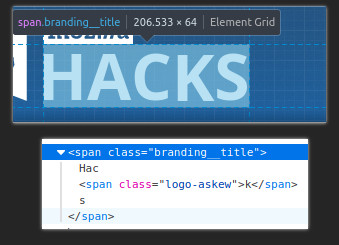
Przykład: blog techniczny Mozilli. jeżeli używacie komputera z myszką i najedziecie kursorem na napis HACKS, to literka K się przekręci. choćby jeżeli macie wyłączony JavaScript.
Na szczęście to złudzenie; niektóre animacje po prostu nie zależą od JavaScriptu, tylko opierają się na tak zwanych arkuszach styli CSS. Po bliższym spojrzeniu widzimy, iż ta literka była otoczona osobnym stylem.
Korzystanie z publicznych komputerów
Mamy też rozwiązanie na poważniejsze przypadki – gdy chcemy szukać informacji legalnych, ale bardzo osobistych. A stronka jednak JavaScriptu wymaga.
Może na przykład na coś zachorowaliśmy i chcemy o tym poczytać. Ale ubezpieczyciel, gdyby się dowiedział, przyciąłby nam nasz dystopijny social credit score.
W takim wypadku idźmy na całość!
Warto się przejść do jakiejś kafejki internetowej, biblioteki publicznej albo uczelnianej czytelni. Znam niejedną, do której dało się wejść bez żadnego zostawiania dokumentu. A choćby gdyby był potrzebny, to i tak prywatne firmy nie mają na tyle władzy, żeby dzwonić do bibliotek i pytać o dane osobowe.
Dla pewności nie bierzemy telefonu albo wyłączamy w nim łapanie hotspotów i geolokalizację. Nie chcemy, żeby jakaś wścibska apka powiązała z nami taki sam adres IP, z jakiego robiliśmy anonimowe wyszukiwanie.
Potem siadamy i przeglądamy. Korzystając z obcego komputera, mamy inny adres IP, inne parametry urządzenia… Prawie wszystko inne. Teraz choćby wścibski JavaScript może nie być w stanie nas rozpoznać.
Trzeba tylko pamiętać, żeby podczas surfowania nie logować się na żadne swoje konta, nie odwiedzać swojego osobistego bloga. Nie robić rzeczy, które by powiązały wyszukiwania z jakimś konkretnym człowiekiem.
Pamiętajmy, iż miejsca publiczne, choćby jeżeli są poza wpływami większych firm, mają z kolei swoich administratorów. Być może znudzonych i wścibskich.
Wtopienie się w tłum
A jeżeli już musimy odwiedzić jakąś stronę z JavaScriptem? A przy tym to nic na tyle drażliwego, żeby dreptać do biblioteki?
W takim wypadku starajmy się minimalizować informacje, jakie ukazuje nasza przeglądarka. Jednocześnie nie odchodząc zanadto od domyślnych ustawień.
- Korzystamy z przeglądarki względnie popularnej.
- I z jej względnie nowej wersji. Raz, iż zlejemy się z tłumem ludzi aktualizujących na bieżąco. Dwa, iż nówka powinna być bardziej doszlifowana.
-
…Ale najlepiej nie z Chrome’a, Chromium, Opery, Edge’a…
Są najpopularniejsze, ale też bardziej konsumenckie. Otwierają dla JavaScriptu coraz to nowe możliwości, których ten może potem nadużyć w celu profilowania.
Moim zdaniem najlepiej korzystać z Firefoksa i Brave’a albo czegoś na ich bazie.
Będziemy rzadsi niż chrome’owcy, jasne. Ale dużo opcji prywatnościowych będzie włączonych domyślnie. Więc z jednej strony blokujemy część mocy JS-a, a z drugiej nie wyróżniamy się spośród innych użytkowników Brave’a/FF.
Rzeczy poniżej to niuanse i bzdety w porównaniu z tymi wyżej. Ale zawsze pozwalają nieco zmniejszyć ilość ujawnianych informacji.
- Urządzenie naładowane do pełna i podłączone do prądu
(kontra wobec Battery API). - Ekran/monitor w dość typowych rozmiarach; okno przeglądarki ustawione na cały ekran; nie chowamy żadnych domyślnych pasków
(kontra wobec informacji o ekranie). - Nie żyć ponad stan :wink: Procesor, pamięć i łącze internetowe mieć jak najbardziej przeciętne; przynajmniej w skali swojej okolicy
(kontra wobec informacji o sprzęcie/połączeniu).
Jeśli ktoś korzysta z iPhone’a, to mam złe wieści – jakiej przeglądarki się nie wybierze, za kulisami będzie silnik od Apple. A ta firma pod względem „uprywatniania” przeglądarki nie jest jakoś szczególnie aktywna.
Sprytniejsze otwieranie narzędzi przeglądarki
Tu coś dla osób, które chcą zaglądać za kulisy szemranych stron.
Pokazałem w tym wpisie, w jaki sposób strona może się zorientować, iż otworzyliśmy narzędzia przeglądarki:
- użyliśmy konkretnego skrótu klawiszowego,
- nagle zmieniły się nam rozmiary okna.
Żeby nie ujawniać tych informacji, najlepiej otwierać narzędzia przeglądarki z wyprzedzeniem, w osobnym oknie. Otwieramy je na jakiejś bezpiecznej stronie, przed odwiedzeniem szpiegującej. Potem wybieramy opcję z menu po prawej stronie.
LibreJS i inne opcje pośrednie
A może dałoby się w jakiś sposób wyłączyć wścibskie części JavaScriptu, a pozostawić te przydatne?
Z takiego założenia wyszli ludzie z Free Software Foundation, proponując podzbiór JavaScriptu prosty, czytelny i niegroźny dla użytkowników. Stworzyli również LibreJS – dodatek do Firefoksa pozwalający wyłapywać mniej sympatyczne wersje JS-a.
Tylko jedna sprawa. jeżeli ktoś jeszcze nie słyszał o tym ruchu, to warto wspomnieć, iż są dość… bezkompromisowi.
Jako nieprzyjazność dla użytkowników rozumieją również rzeczy mocno zakorzenione we współczesnej kulturze tworzenia JS-a. Takie jak zmniejszanie rozmiaru kodu przez usuwanie z niego spacji.
Z tego względu raczej nie ma co liczyć na szersze poparcie dla wizji LibreJS. Ale sam pomysł stworzenia „nieszkodliwego” podzbioru JavaScriptu, który nasza przeglądarka by dopuszczała, jak najbardziej ma ręce i nogi.
Osoby zainteresowane programowaniem i „naprawieniem internetu” mogą obserwować zarówno LJS, jak też inne podobne inicjatywy.
Mam nadzieję, iż w tryby internetowej machiny śledzącej będą coraz częściej wpadały drobiny żwiru. choćby jeżeli jedna nic nie zmieni, to w większych ilościach mogą rozwalić niejeden mechanizm.
W kolejnym wpisie przyjrzymy się tej machinie jeszcze dokładniej. Ciepłego maja życzę! :sunglasses:

















